 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Implicatures: Modelling Relevance Theory Probabilistically
Sep 26, 2025
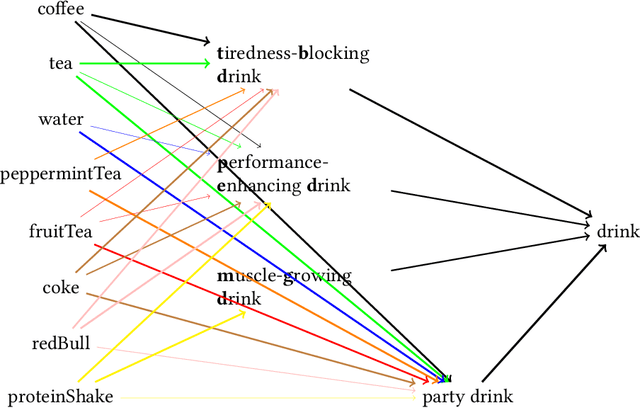

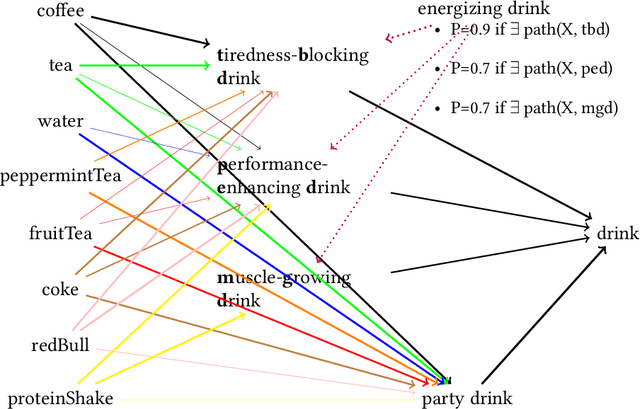
Recent advances in Bayesian probability theory and its application to cognitive science in combination with the development of a new generation of computational tools and methods for probabilistic computation have led to a 'probabilistic turn' in pragmatics and semantics. In particular, the framework of Rational Speech Act theory has been developed to model broadly Gricean accounts of pragmatic phenomena in Bayesian terms, starting with fairly simple reference games and covering ever more complex communicative exchanges such as verbal syllogistic reasoning. This paper explores in which way a similar Bayesian approach might be applied to relevance-theoretic pragmatics (Sperber & Wilson, 1995) by study a paradigmatic pragmatic phenomenon: the communication of implicit meaning by ways of (conversational) implicatures.
GerPS-Compare: Comparing NER methods for legal norm analysis
Dec 03, 2024



We apply NER to a particular sub-genre of legal texts in German: the genre of legal norms regulating administrative processes in public service administration. The analysis of such texts involves identifying stretches of text that instantiate one of ten classes identified by public service administration professionals. We investigate and compare three methods for performing Named Entity Recognition (NER) to detect these classes: a Rule-based system, deep discriminative models, and a deep generative model. Our results show that Deep Discriminative models outperform both the Rule-based system as well as the Deep Generative model, the latter two roughly performing equally well, outperforming each other in different classes. The main cause for this somewhat surprising result is arguably the fact that the classes used in the analysis are semantically and syntactically heterogeneous, in contrast to the classes used in more standard NER tasks. Deep Discriminative models appear to be better equipped for dealing with this heterogenerity than both generic LLMs and human linguists designing rule-based NER systems.
ANNETTE: Accurate Neural Network Execution Time Estimation with Stacked Models
May 07, 2021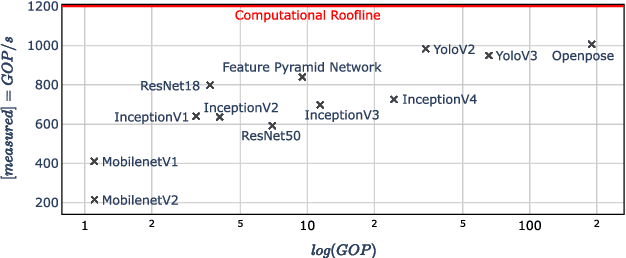
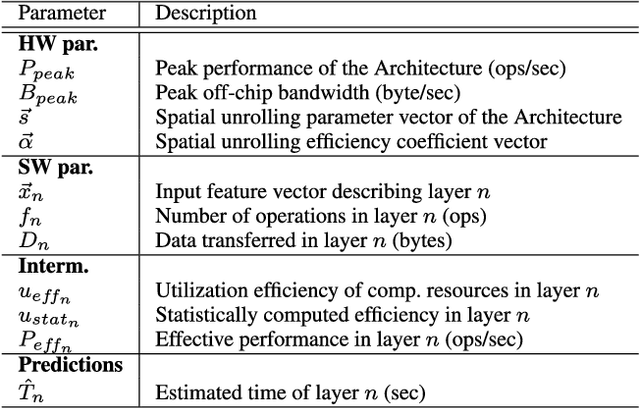
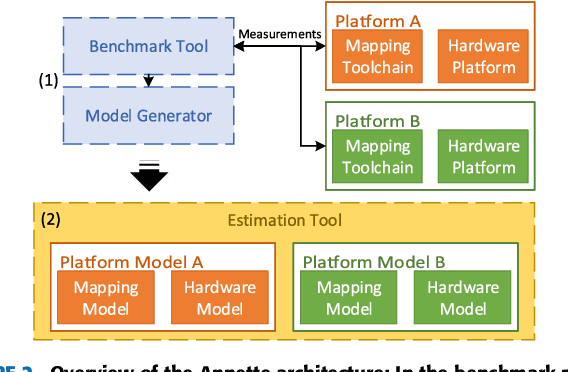

With new accelerator hardware for DNN, the computing power for AI applications has increased rapidly. However, as DNN algorithms become more complex and optimized for specific applications, latency requirements remain challenging, and it is critical to find the optimal points in the design space. To decouple the architectural search from the target hardware, we propose a time estimation framework that allows for modeling the inference latency of DNNs on hardware accelerators based on mapping and layer-wise estimation models. The proposed methodology extracts a set of models from micro-kernel and multi-layer benchmarks and generates a stacked model for mapping and network execution time estimation. We compare estimation accuracy and fidelity of the generated mixed models, statistical models with the roofline model, and a refined roofline model for evaluation. We test the mixed models on the ZCU102 SoC board with DNNDK and Intel Neural Compute Stick 2 on a set of 12 state-of-the-art neural networks. It shows an average estimation error of 3.47% for the DNNDK and 7.44% for the NCS2, outperforming the statistical and analytical layer models for almost all selected networks. For a randomly selected subset of 34 networks of the NASBench dataset, the mixed model reaches fidelity of 0.988 in Spearman's rank correlation coefficient metric. The code of ANNETTE is publicly available at https://github.com/embedded-machine-learning/annette.