 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChild-directed speech facilitates production, not comprehension, in BabyLMs
May 31, 2026Recent studies suggest that child-directed speech is not conducive to language learning in BabyLMs. However, current evaluations focus predominantly on comprehension and not production, which is central to usage-based theories of language acquisition which argue how CDS facilitates early language use through constructional ''frames'' (frequent lexical patterns with open slots). We introduce a novel generation-based evaluation inspired by such theories in form of a frame-completion task, and compare Llama models trained with CDS, the BabyLM corpus, and web-crawl data (FineWeb-edu) on comprehension benchmarks and our novel framework. Our results reveal a clear dissociation between models' comprehension and production capabilities: while FineWeb-trained models excel at minimal pairs, CDS-trained models produce grammatical completions substantially earlier in training and concentrate probability mass on appropriate slot-fillers. These findings show that comprehension benchmarks underestimate what CDS affords to BabyLMs.
The Frequency Confound in Language-Model Surprisal and Metaphor Novelty
May 07, 2026Language-model (LM) surprisal is widely used as a proxy for contextual predictability and has been reported to correlate with metaphor novelty judgments. However, surprisal is tightly intertwined with lexical frequency. We explore this interaction on metaphor novelty ratings using two different word frequency measures. We analyse surprisal estimates from eight Pythia model sizes and 154 training checkpoints. Across settings, word frequency is a stronger predictor of metaphor novelty than surprisal. Across training stages, the surprisal--novelty association peaks at an early stage and then falls again, mirroring a similarly timed increase in the surprisal--frequency association. These results suggest that the often-reported optimal LM surprisal settings may incorrectly associate contextual predictability with metaphor novelty and processing difficulty, whereas lexical frequency may be the major underlying factor.
Talking to a Know-It-All GPT or a Second-Guesser Claude? How Repair reveals unreliable Multi-Turn Behavior in LLMs
Apr 22, 2026Repair, an important resource for resolving trouble in human-human conversation, remains underexplored in human-LLM interaction. In this study, we investigate how LLMs engage in the interactive process of repair in multi-turn dialogues around solvable and unsolvable math questions. We examine whether models initiate repair themselves and how they respond to user-initiated repair. Our results show strong differences across models: reactions range from being almost completely resistant to (appropriate) repair attempts to being highly susceptible and easily manipulated. We further demonstrate that once conversations extend beyond a single turn, model behavior becomes more distinctive and less predictable across systems. Overall, our findings indicate that each tested LLM exhibits its own characteristic form of unreliability in the context of repair.
Reference Games as a Testbed for the Alignment of Model Uncertainty and Clarification Requests
Jan 12, 2026In human conversation, both interlocutors play an active role in maintaining mutual understanding. When addressees are uncertain about what speakers mean, for example, they can request clarification. It is an open question for language models whether they can assume a similar addressee role, recognizing and expressing their own uncertainty through clarification. We argue that reference games are a good testbed to approach this question as they are controlled, self-contained, and make clarification needs explicit and measurable. To test this, we evaluate three vision-language models comparing a baseline reference resolution task to an experiment where the models are instructed to request clarification when uncertain. The results suggest that even in such simple tasks, models often struggle to recognize internal uncertainty and translate it into adequate clarification behavior. This demonstrates the value of reference games as testbeds for interaction qualities of (vision and) language models.
Surprisal and Metaphor Novelty: Moderate Correlations and Divergent Scaling Effects
Jan 08, 2026Novel metaphor comprehension involves complex semantic processes and linguistic creativity, making it an interesting task for studying language models (LMs). This study investigates whether surprisal, a probabilistic measure of predictability in LMs, correlates with different metaphor novelty datasets. We analyse surprisal from 16 LM variants on corpus-based and synthetic metaphor novelty datasets. We explore a cloze-style surprisal method that conditions on full-sentence context. Results show that LMs yield significant moderate correlations with scores/labels of metaphor novelty. We further identify divergent scaling patterns: on corpus-based data, correlation strength decreases with model size (inverse scaling effect), whereas on synthetic data it increases (Quality-Power Hypothesis). We conclude that while surprisal can partially account for annotations of metaphor novelty, it remains a limited metric of linguistic creativity.
Dialogue Is Not Enough to Make a Communicative BabyLM (But Neither Is Developmentally Inspired Reinforcement Learning)
Oct 23, 2025We investigate whether pre-training exclusively on dialogue data results in formally and functionally apt small language models. Based on this pre-trained llamalogue model, we employ a variety of fine-tuning strategies to enforce "more communicative" text generations by our models. Although our models underperform on most standard BabyLM benchmarks, they excel at dialogue continuation prediction in a minimal pair setting. While PPO fine-tuning has mixed to adversarial effects on our models, DPO fine-tuning further improves their performance on our custom dialogue benchmark.
Are BabyLMs Deaf to Gricean Maxims? A Pragmatic Evaluation of Sample-efficient Language Models
Oct 06, 2025
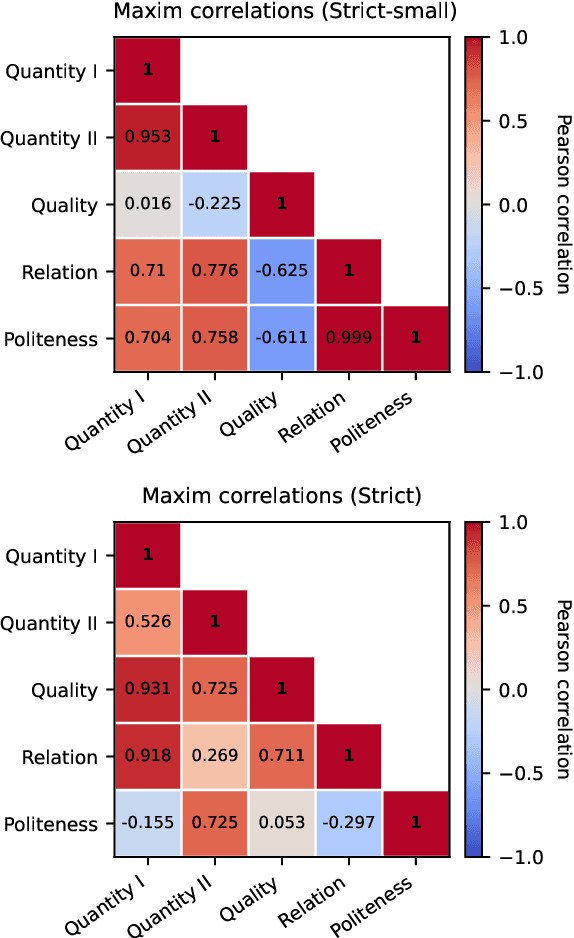
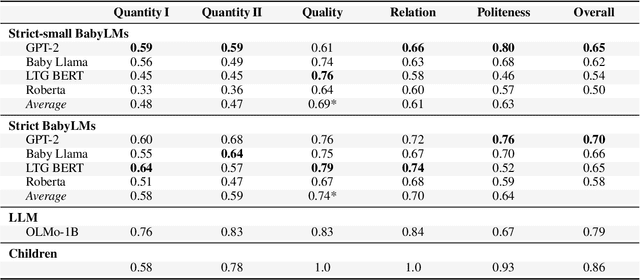

Implicit meanings are integral to human communication, making it essential for language models to be capable of identifying and interpreting them. Grice (1975) proposed a set of conversational maxims that guide cooperative dialogue, noting that speakers may deliberately violate these principles to express meanings beyond literal words, and that listeners, in turn, recognize such violations to draw pragmatic inferences. Building on Surian et al. (1996)'s study of children's sensitivity to violations of Gricean maxims, we introduce a novel benchmark to test whether language models pretrained on less than 10M and less than 100M tokens can distinguish maxim-adhering from maxim-violating utterances. We compare these BabyLMs across five maxims and situate their performance relative to children and a Large Language Model (LLM) pretrained on 3T tokens. We find that overall, models trained on less than 100M tokens outperform those trained on less than 10M, yet fall short of child-level and LLM competence. Our results suggest that modest data increases improve some aspects of pragmatic behavior, leading to finer-grained differentiation between pragmatic dimensions.
The InviTE Corpus: Annotating Invectives in Tudor English Texts for Computational Modeling
Sep 26, 2025In this paper, we aim at the application of Natural Language Processing (NLP) techniques to historical research endeavors, particularly addressing the study of religious invectives in the context of the Protestant Reformation in Tudor England. We outline a workflow spanning from raw data, through pre-processing and data selection, to an iterative annotation process. As a result, we introduce the InviTE corpus -- a corpus of almost 2000 Early Modern English (EModE) sentences, which are enriched with expert annotations regarding invective language throughout 16th-century England. Subsequently, we assess and compare the performance of fine-tuned BERT-based models and zero-shot prompted instruction-tuned large language models (LLMs), which highlights the superiority of models pre-trained on historical data and fine-tuned to invective detection.
Are Multimodal Large Language Models Pragmatically Competent Listeners in Simple Reference Resolution Tasks?
Jun 13, 2025We investigate the linguistic abilities of multimodal large language models in reference resolution tasks featuring simple yet abstract visual stimuli, such as color patches and color grids. Although the task may not seem challenging for today's language models, being straightforward for human dyads, we consider it to be a highly relevant probe of the pragmatic capabilities of MLLMs. Our results and analyses indeed suggest that basic pragmatic capabilities, such as context-dependent interpretation of color descriptions, still constitute major challenges for state-of-the-art MLLMs.
SceneGram: Conceptualizing and Describing Tangrams in Scene Context
Jun 13, 2025



Research on reference and naming suggests that humans can come up with very different ways of conceptualizing and referring to the same object, e.g. the same abstract tangram shape can be a "crab", "sink" or "space ship". Another common assumption in cognitive science is that scene context fundamentally shapes our visual perception of objects and conceptual expectations. This paper contributes SceneGram, a dataset of human references to tangram shapes placed in different scene contexts, allowing for systematic analyses of the effect of scene context on conceptualization. Based on this data, we analyze references to tangram shapes generated by multimodal LLMs, showing that these models do not account for the richness and variability of conceptualizations found in human references.