 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting States of Understanding in Explanatory Interactions Using Cognitive Load-Related Linguistic Cues
Mar 20, 2026We investigate how verbal and nonverbal linguistic features, exhibited by speakers and listeners in dialogue, can contribute to predicting the listener's state of understanding in explanatory interactions on a moment-by-moment basis. Specifically, we examine three linguistic cues related to cognitive load and hypothesised to correlate with listener understanding: the information value (operationalised with surprisal) and syntactic complexity of the speaker's utterances, and the variation in the listener's interactive gaze behaviour. Based on statistical analyses of the MUNDEX corpus of face-to-face dialogic board game explanations, we find that individual cues vary with the listener's level of understanding. Listener states ('Understanding', 'Partial Understanding', 'Non-Understanding' and 'Misunderstanding') were self-annotated by the listeners using a retrospective video-recall method. The results of a subsequent classification experiment, involving two off-the-shelf classifiers and a fine-tuned German BERT-based multimodal classifier, demonstrate that prediction of these four states of understanding is generally possible and improves when the three linguistic cues are considered alongside textual features.
Reference Games as a Testbed for the Alignment of Model Uncertainty and Clarification Requests
Jan 12, 2026In human conversation, both interlocutors play an active role in maintaining mutual understanding. When addressees are uncertain about what speakers mean, for example, they can request clarification. It is an open question for language models whether they can assume a similar addressee role, recognizing and expressing their own uncertainty through clarification. We argue that reference games are a good testbed to approach this question as they are controlled, self-contained, and make clarification needs explicit and measurable. To test this, we evaluate three vision-language models comparing a baseline reference resolution task to an experiment where the models are instructed to request clarification when uncertain. The results suggest that even in such simple tasks, models often struggle to recognize internal uncertainty and translate it into adequate clarification behavior. This demonstrates the value of reference games as testbeds for interaction qualities of (vision and) language models.
Identifying the Periodicity of Information in Natural Language
Oct 31, 2025Recent theoretical advancement of information density in natural language has brought the following question on desk: To what degree does natural language exhibit periodicity pattern in its encoded information? We address this question by introducing a new method called AutoPeriod of Surprisal (APS). APS adopts a canonical periodicity detection algorithm and is able to identify any significant periods that exist in the surprisal sequence of a single document. By applying the algorithm to a set of corpora, we have obtained the following interesting results: Firstly, a considerable proportion of human language demonstrates a strong pattern of periodicity in information; Secondly, new periods that are outside the distributions of typical structural units in text (e.g., sentence boundaries, elementary discourse units, etc.) are found and further confirmed via harmonic regression modeling. We conclude that the periodicity of information in language is a joint outcome from both structured factors and other driving factors that take effect at longer distances. The advantages of our periodicity detection method and its potentials in LLM-generation detection are further discussed.
Dialogue Is Not Enough to Make a Communicative BabyLM (But Neither Is Developmentally Inspired Reinforcement Learning)
Oct 23, 2025We investigate whether pre-training exclusively on dialogue data results in formally and functionally apt small language models. Based on this pre-trained llamalogue model, we employ a variety of fine-tuning strategies to enforce "more communicative" text generations by our models. Although our models underperform on most standard BabyLM benchmarks, they excel at dialogue continuation prediction in a minimal pair setting. While PPO fine-tuning has mixed to adversarial effects on our models, DPO fine-tuning further improves their performance on our custom dialogue benchmark.
Conversational Implicatures: Modelling Relevance Theory Probabilistically
Sep 26, 2025
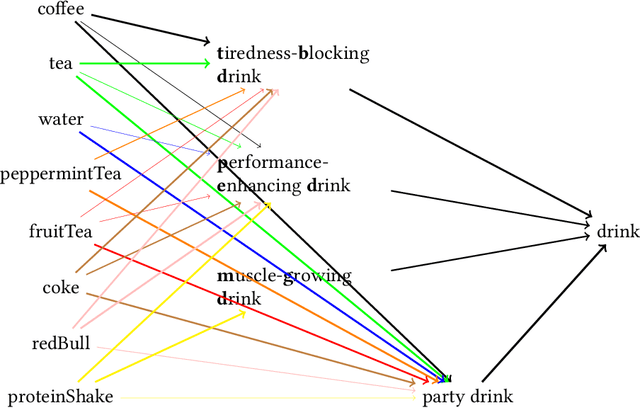

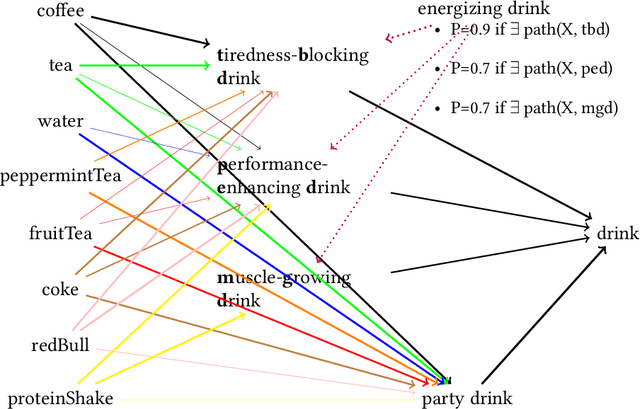
Recent advances in Bayesian probability theory and its application to cognitive science in combination with the development of a new generation of computational tools and methods for probabilistic computation have led to a 'probabilistic turn' in pragmatics and semantics. In particular, the framework of Rational Speech Act theory has been developed to model broadly Gricean accounts of pragmatic phenomena in Bayesian terms, starting with fairly simple reference games and covering ever more complex communicative exchanges such as verbal syllogistic reasoning. This paper explores in which way a similar Bayesian approach might be applied to relevance-theoretic pragmatics (Sperber & Wilson, 1995) by study a paradigmatic pragmatic phenomenon: the communication of implicit meaning by ways of (conversational) implicatures.
Are Multimodal Large Language Models Pragmatically Competent Listeners in Simple Reference Resolution Tasks?
Jun 13, 2025We investigate the linguistic abilities of multimodal large language models in reference resolution tasks featuring simple yet abstract visual stimuli, such as color patches and color grids. Although the task may not seem challenging for today's language models, being straightforward for human dyads, we consider it to be a highly relevant probe of the pragmatic capabilities of MLLMs. Our results and analyses indeed suggest that basic pragmatic capabilities, such as context-dependent interpretation of color descriptions, still constitute major challenges for state-of-the-art MLLMs.
Revisiting the Phenomenon of Syntactic Complexity Convergence on German Dialogue Data
Aug 22, 2024We revisit the phenomenon of syntactic complexity convergence in conversational interaction, originally found for English dialogue, which has theoretical implication for dialogical concepts such as mutual understanding. We use a modified metric to quantify syntactic complexity based on dependency parsing. The results show that syntactic complexity convergence can be statistically confirmed in one of three selected German datasets that were analysed. Given that the dataset which shows such convergence is much larger than the other two selected datasets, the empirical results indicate a certain degree of linguistic generality of syntactic complexity convergence in conversational interaction. We also found a different type of syntactic complexity convergence in one of the datasets while further investigation is still necessary.
The Illusion of Competence: Evaluating the Effect of Explanations on Users' Mental Models of Visual Question Answering Systems
Jun 27, 2024



We examine how users perceive the limitations of an AI system when it encounters a task that it cannot perform perfectly and whether providing explanations alongside its answers aids users in constructing an appropriate mental model of the system's capabilities and limitations. We employ a visual question answer and explanation task where we control the AI system's limitations by manipulating the visual inputs: during inference, the system either processes full-color or grayscale images. Our goal is to determine whether participants can perceive the limitations of the system. We hypothesize that explanations will make limited AI capabilities more transparent to users. However, our results show that explanations do not have this effect. Instead of allowing users to more accurately assess the limitations of the AI system, explanations generally increase users' perceptions of the system's competence - regardless of its actual performance.
Forms of Understanding of XAI-Explanations
Nov 15, 2023

Explainability has become an important topic in computer science and artificial intelligence, leading to a subfield called Explainable Artificial Intelligence (XAI). The goal of providing or seeking explanations is to achieve (better) 'understanding' on the part of the explainee. However, what it means to 'understand' is still not clearly defined, and the concept itself is rarely the subject of scientific investigation. This conceptual article aims to present a model of forms of understanding in the context of XAI and beyond. From an interdisciplinary perspective bringing together computer science, linguistics, sociology, and psychology, a definition of understanding and its forms, assessment, and dynamics during the process of giving everyday explanations are explored. Two types of understanding are considered as possible outcomes of explanations, namely enabledness, 'knowing how' to do or decide something, and comprehension, 'knowing that' -- both in different degrees (from shallow to deep). Explanations regularly start with shallow understanding in a specific domain and can lead to deep comprehension and enabledness of the explanandum, which we see as a prerequisite for human users to gain agency. In this process, the increase of comprehension and enabledness are highly interdependent. Against the background of this systematization, special challenges of understanding in XAI are discussed.
Conversational Feedback in Scripted versus Spontaneous Dialogues: A Comparative Analysis
Sep 27, 2023
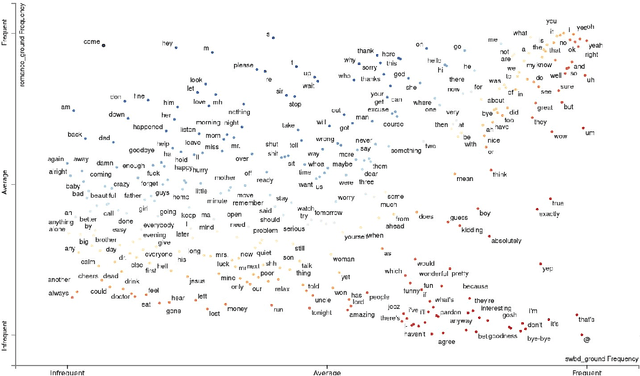

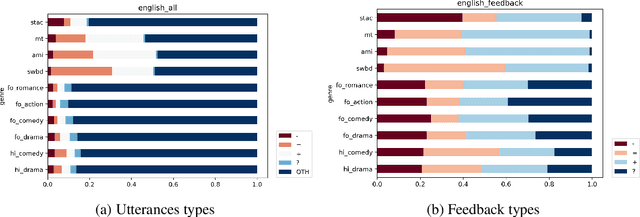
Scripted dialogues such as movie and TV subtitles constitute a widespread source of training data for conversational NLP models. However, the linguistic characteristics of those dialogues are notably different from those observed in corpora of spontaneous interactions. This difference is particularly marked for communicative feedback and grounding phenomena such as backchannels, acknowledgments, or clarification requests. Such signals are known to constitute a key part of the conversation flow and are used by the dialogue participants to provide feedback to one another on their perception of the ongoing interaction. This paper presents a quantitative analysis of such communicative feedback phenomena in both subtitles and spontaneous conversations. Based on dialogue data in English, French, German, Hungarian, Italian, Japanese, Norwegian and Chinese, we extract both lexical statistics and classification outputs obtained with a neural dialogue act tagger. Two main findings of this empirical study are that (1) conversational feedback is markedly less frequent in subtitles than in spontaneous dialogues and (2) subtitles contain a higher proportion of negative feedback. Furthermore, we show that dialogue responses generated by large language models also follow the same underlying trends and include comparatively few occurrences of communicative feedback, except when those models are explicitly fine-tuned on spontaneous dialogues.