 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthful Text Sanitization Guided by Inference Attacks
Dec 17, 2024



The purpose of text sanitization is to rewrite those text spans in a document that may directly or indirectly identify an individual, to ensure they no longer disclose personal information. Text sanitization must strike a balance between preventing the leakage of personal information (privacy protection) while also retaining as much of the document's original content as possible (utility preservation). We present an automated text sanitization strategy based on generalizations, which are more abstract (but still informative) terms that subsume the semantic content of the original text spans. The approach relies on instruction-tuned large language models (LLMs) and is divided into two stages. The LLM is first applied to obtain truth-preserving replacement candidates and rank them according to their abstraction level. Those candidates are then evaluated for their ability to protect privacy by conducting inference attacks with the LLM. Finally, the system selects the most informative replacement shown to be resistant to those attacks. As a consequence of this two-stage process, the chosen replacements effectively balance utility and privacy. We also present novel metrics to automatically evaluate these two aspects without the need to manually annotate data. Empirical results on the Text Anonymization Benchmark show that the proposed approach leads to enhanced utility, with only a marginal increase in the risk of re-identifying protected individuals compared to fully suppressing the original information. Furthermore, the selected replacements are shown to be more truth-preserving and abstractive than previous methods.
Neural Text Sanitization with Privacy Risk Indicators: An Empirical Analysis
Oct 22, 2023Text sanitization is the task of redacting a document to mask all occurrences of (direct or indirect) personal identifiers, with the goal of concealing the identity of the individual(s) referred in it. In this paper, we consider a two-step approach to text sanitization and provide a detailed analysis of its empirical performance on two recently published datasets: the Text Anonymization Benchmark (Pil\'an et al., 2022) and a collection of Wikipedia biographies (Papadopoulou et al., 2022). The text sanitization process starts with a privacy-oriented entity recognizer that seeks to determine the text spans expressing identifiable personal information. This privacy-oriented entity recognizer is trained by combining a standard named entity recognition model with a gazetteer populated by person-related terms extracted from Wikidata. The second step of the text sanitization process consists in assessing the privacy risk associated with each detected text span, either isolated or in combination with other text spans. We present five distinct indicators of the re-identification risk, respectively based on language model probabilities, text span classification, sequence labelling, perturbations, and web search. We provide a contrastive analysis of each privacy indicator and highlight their benefits and limitations, notably in relation to the available labeled data.
Conversational Feedback in Scripted versus Spontaneous Dialogues: A Comparative Analysis
Sep 27, 2023
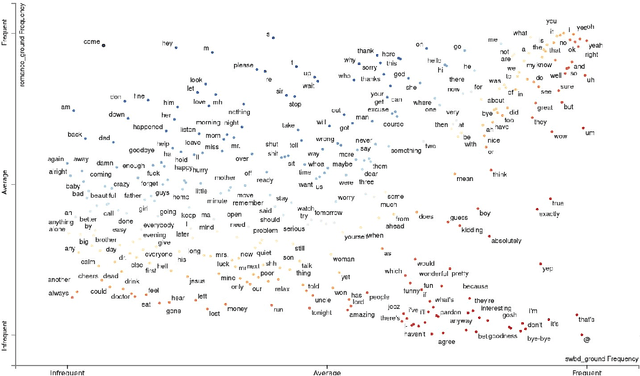

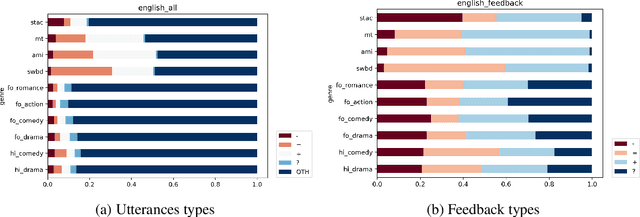
Scripted dialogues such as movie and TV subtitles constitute a widespread source of training data for conversational NLP models. However, the linguistic characteristics of those dialogues are notably different from those observed in corpora of spontaneous interactions. This difference is particularly marked for communicative feedback and grounding phenomena such as backchannels, acknowledgments, or clarification requests. Such signals are known to constitute a key part of the conversation flow and are used by the dialogue participants to provide feedback to one another on their perception of the ongoing interaction. This paper presents a quantitative analysis of such communicative feedback phenomena in both subtitles and spontaneous conversations. Based on dialogue data in English, French, German, Hungarian, Italian, Japanese, Norwegian and Chinese, we extract both lexical statistics and classification outputs obtained with a neural dialogue act tagger. Two main findings of this empirical study are that (1) conversational feedback is markedly less frequent in subtitles than in spontaneous dialogues and (2) subtitles contain a higher proportion of negative feedback. Furthermore, we show that dialogue responses generated by large language models also follow the same underlying trends and include comparatively few occurrences of communicative feedback, except when those models are explicitly fine-tuned on spontaneous dialogues.
Bootstrapping Text Anonymization Models with Distant Supervision
May 13, 2022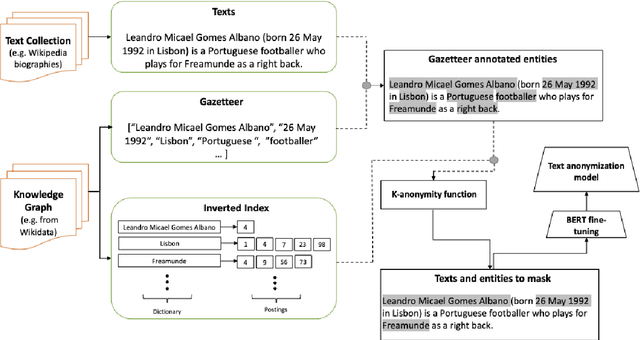



We propose a novel method to bootstrap text anonymization models based on distant supervision. Instead of requiring manually labeled training data, the approach relies on a knowledge graph expressing the background information assumed to be publicly available about various individuals. This knowledge graph is employed to automatically annotate text documents including personal data about a subset of those individuals. More precisely, the method determines which text spans ought to be masked in order to guarantee $k$-anonymity, assuming an adversary with access to both the text documents and the background information expressed in the knowledge graph. The resulting collection of labeled documents is then used as training data to fine-tune a pre-trained language model for text anonymization. We illustrate this approach using a knowledge graph extracted from Wikidata and short biographical texts from Wikipedia. Evaluation results with a RoBERTa-based model and a manually annotated collection of 553 summaries showcase the potential of the approach, but also unveil a number of issues that may arise if the knowledge graph is noisy or incomplete. The results also illustrate that, contrary to most sequence labeling problems, the text anonymization task may admit several alternative solutions.
The Text Anonymization Benchmark (TAB): A Dedicated Corpus and Evaluation Framework for Text Anonymization
Jan 25, 2022


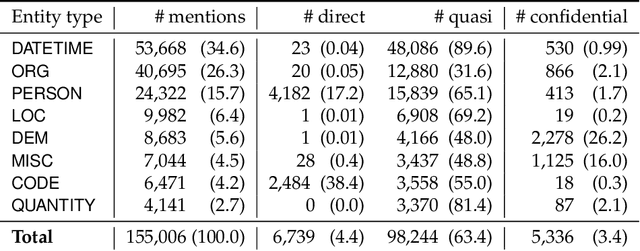
We present a novel benchmark and associated evaluation metrics for assessing the performance of text anonymization methods. Text anonymization, defined as the task of editing a text document to prevent the disclosure of personal information, currently suffers from a shortage of privacy-oriented annotated text resources, making it difficult to properly evaluate the level of privacy protection offered by various anonymization methods. This paper presents TAB (Text Anonymization Benchmark), a new, open-source annotated corpus developed to address this shortage. The corpus comprises 1,268 English-language court cases from the European Court of Human Rights (ECHR) enriched with comprehensive annotations about the personal information appearing in each document, including their semantic category, identifier type, confidential attributes, and co-reference relations. Compared to previous work, the TAB corpus is designed to go beyond traditional de-identification (which is limited to the detection of predefined semantic categories), and explicitly marks which text spans ought to be masked in order to conceal the identity of the person to be protected. Along with presenting the corpus and its annotation layers, we also propose a set of evaluation metrics that are specifically tailored towards measuring the performance of text anonymization, both in terms of privacy protection and utility preservation. We illustrate the use of the benchmark and the proposed metrics by assessing the empirical performance of several baseline text anonymization models. The full corpus along with its privacy-oriented annotation guidelines, evaluation scripts and baseline models are available on: https://github.com/NorskRegnesentral/text-anonymisation-benchmark
Building a Norwegian Lexical Resource for Medical Entity Recognition
Apr 06, 2020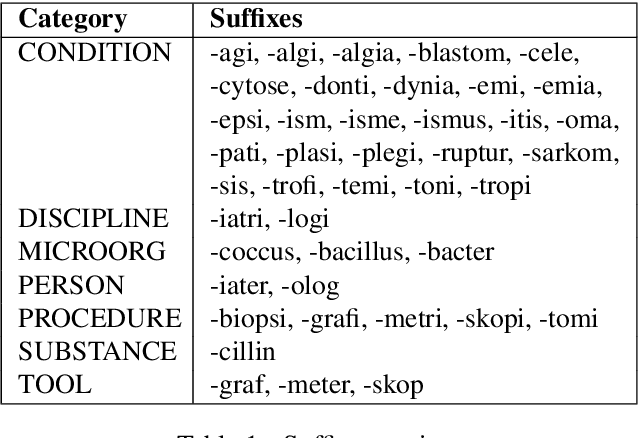

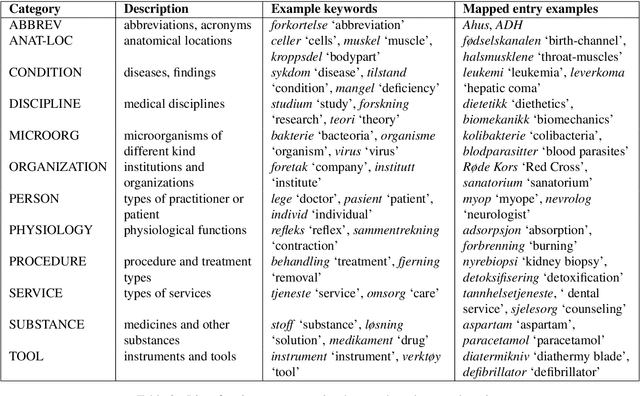
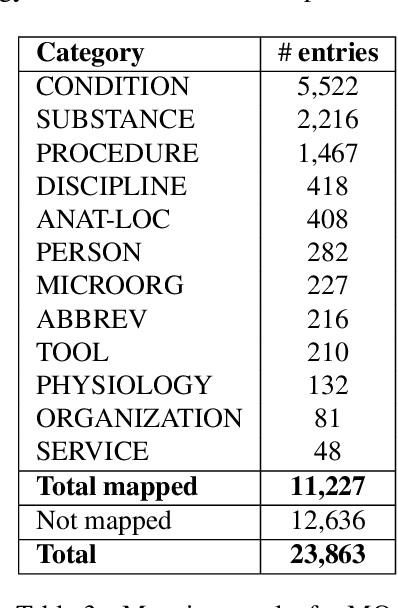
We present a large Norwegian lexical resource of categorized medical terms. The resource merges information from large medical databases, and contains over 77,000 unique entries, including automatically mapped terms from a Norwegian medical dictionary. We describe the methodology behind this automatic dictionary entry mapping based on keywords and suffixes and further present the results of a manual evaluation performed on a subset by a domain expert. The evaluation indicated that ca. 80% of the mappings were correct.
Candidate sentence selection for language learning exercises: from a comprehensive framework to an empirical evaluation
Jun 12, 2017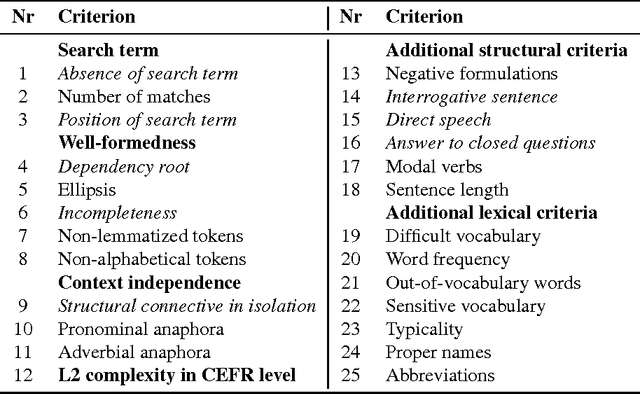
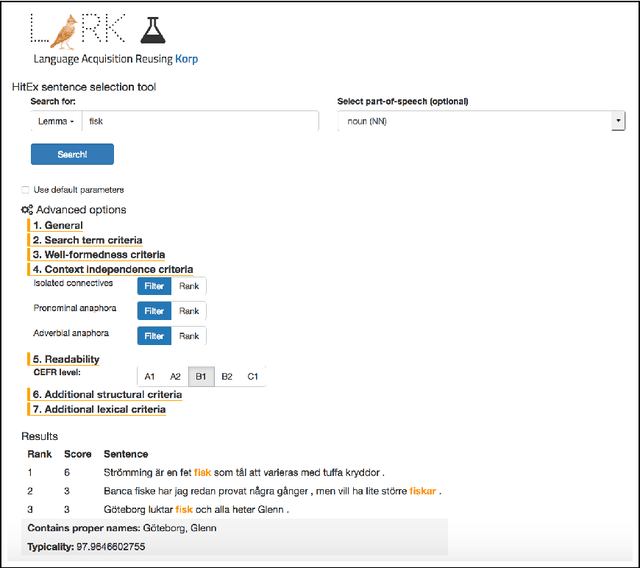
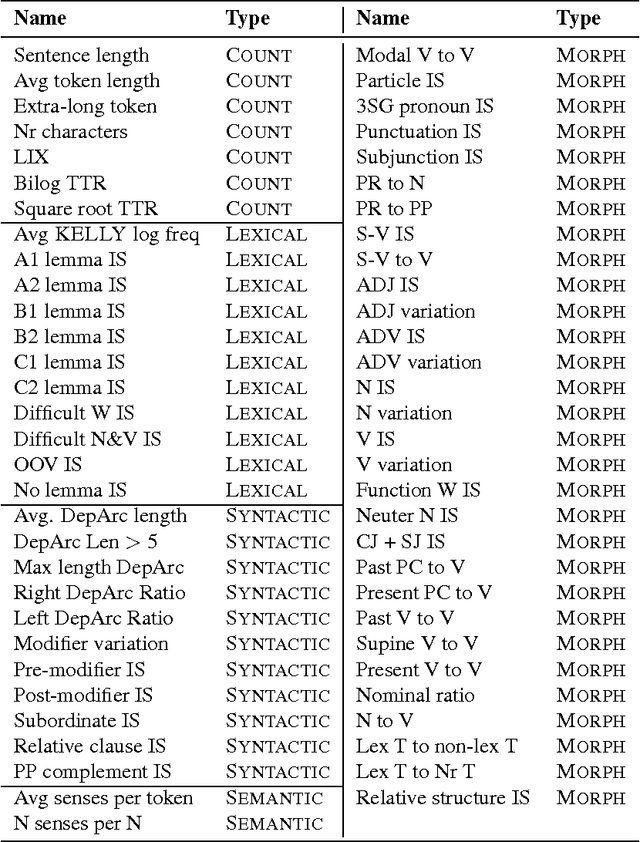

We present a framework and its implementation relying on Natural Language Processing methods, which aims at the identification of exercise item candidates from corpora. The hybrid system combining heuristics and machine learning methods includes a number of relevant selection criteria. We focus on two fundamental aspects: linguistic complexity and the dependence of the extracted sentences on their original context. Previous work on exercise generation addressed these two criteria only to a limited extent, and a refined overall candidate sentence selection framework appears also to be lacking. In addition to a detailed description of the system, we present the results of an empirical evaluation conducted with language teachers and learners which indicate the usefulness of the system for educational purposes. We have integrated our system into a freely available online learning platform.
Detecting Context Dependence in Exercise Item Candidates Selected from Corpora
May 06, 2016

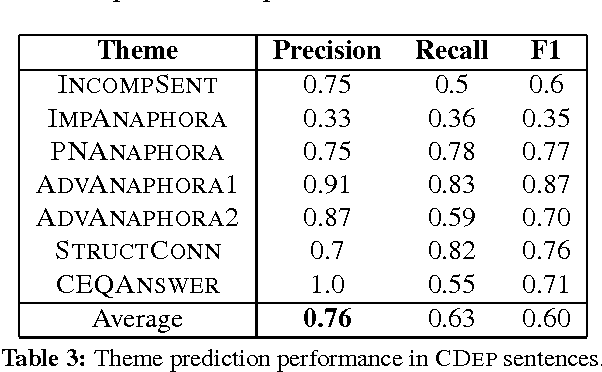
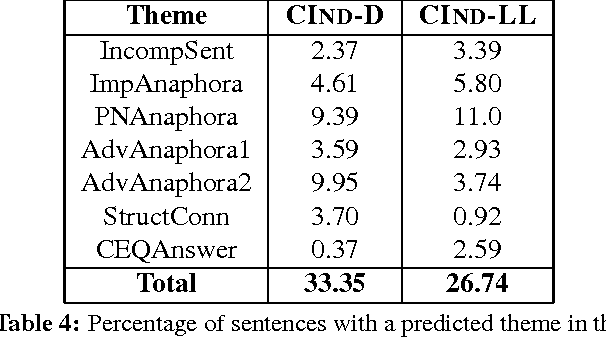
We explore the factors influencing the dependence of single sentences on their larger textual context in order to automatically identify candidate sentences for language learning exercises from corpora which are presentable in isolation. An in-depth investigation of this question has not been previously carried out. Understanding this aspect can contribute to a more efficient selection of candidate sentences which, besides reducing the time required for item writing, can also ensure a higher degree of variability and authenticity. We present a set of relevant aspects collected based on the qualitative analysis of a smaller set of context-dependent corpus example sentences. Furthermore, we implemented a rule-based algorithm using these criteria which achieved an average precision of 0.76 for the identification of different issues related to context dependence. The method has also been evaluated empirically where 80% of the sentences in which our system did not detect context-dependent elements were also considered context-independent by human raters.
SweLL on the rise: Swedish Learner Language corpus for European Reference Level studies
Apr 22, 2016
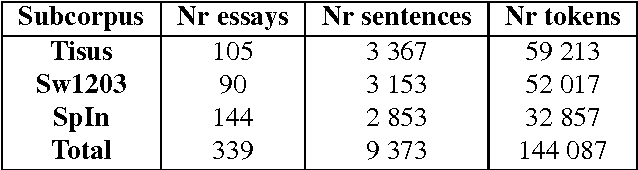
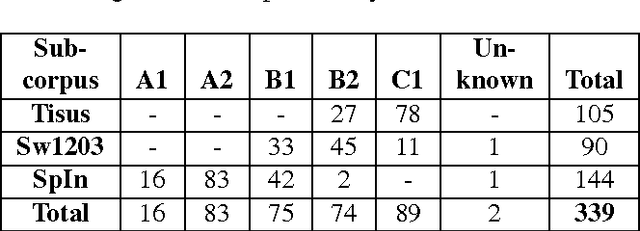
We present a new resource for Swedish, SweLL, a corpus of Swedish Learner essays linked to learners' performance according to the Common European Framework of Reference (CEFR). SweLL consists of three subcorpora - SpIn, SW1203 and Tisus, collected from three different educational establishments. The common metadata for all subcorpora includes age, gender, native languages, time of residence in Sweden, type of written task. Depending on the subcorpus, learner texts may contain additional information, such as text genres, topics, grades. Five of the six CEFR levels are represented in the corpus: A1, A2, B1, B2 and C1 comprising in total 339 essays. C2 level is not included since courses at C2 level are not offered. The work flow consists of collection of essays and permits, essay digitization and registration, meta-data annotation, automatic linguistic annotation. Inter-rater agreement is presented on the basis of SW1203 subcorpus. The work on SweLL is still ongoing with more than 100 essays waiting in the pipeline. This article both describes the resource and the "how-to" behind the compilation of SweLL.
A Readable Read: Automatic Assessment of Language Learning Materials based on Linguistic Complexity
Mar 29, 2016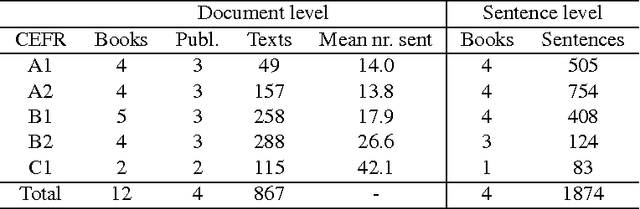
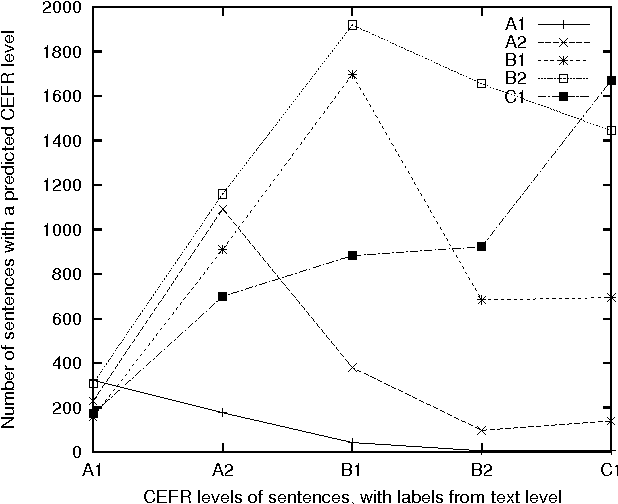
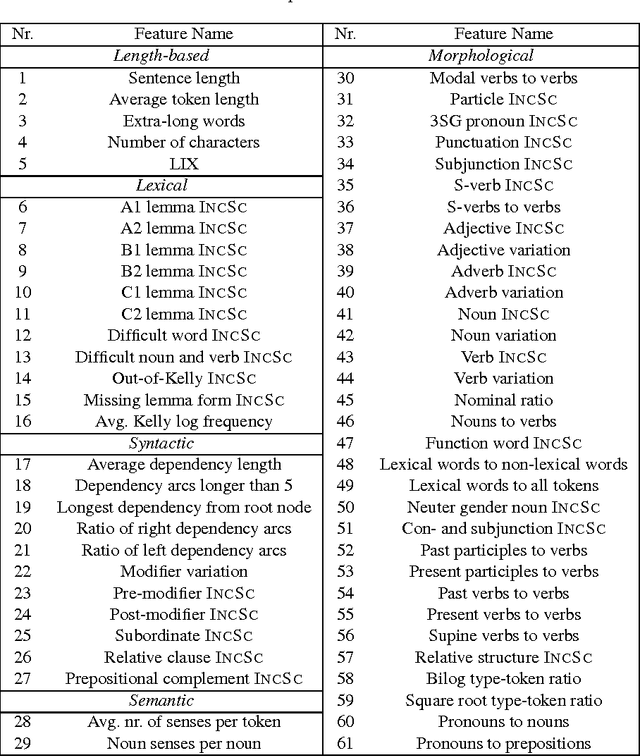

Corpora and web texts can become a rich language learning resource if we have a means of assessing whether they are linguistically appropriate for learners at a given proficiency level. In this paper, we aim at addressing this issue by presenting the first approach for predicting linguistic complexity for Swedish second language learning material on a 5-point scale. After showing that the traditional Swedish readability measure, L\"asbarhetsindex (LIX), is not suitable for this task, we propose a supervised machine learning model, based on a range of linguistic features, that can reliably classify texts according to their difficulty level. Our model obtained an accuracy of 81.3% and an F-score of 0.8, which is comparable to the state of the art in English and is considerably higher than previously reported results for other languages. We further studied the utility of our features with single sentences instead of full texts since sentences are a common linguistic unit in language learning exercises. We trained a separate model on sentence-level data with five classes, which yielded 63.4% accuracy. Although this is lower than the document level performance, we achieved an adjacent accuracy of 92%. Furthermore, we found that using a combination of different features, compared to using lexical features alone, resulted in 7% improvement in classification accuracy at the sentence level, whereas at the document level, lexical features were more dominant. Our models are intended for use in a freely accessible web-based language learning platform for the automatic generation of exercises.