 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexityMT: Benchmarking the Interaction Between Text Complexity and Machine Translation
Jun 03, 2026When a text is translated, does the translation retain the complexity of the original? We introduce ComplexityMT, a new challenge for assessing how text complexity and machine translation interact with and influence each other, using the Common European Framework of Reference for Languages (CEFR) levels as the measure of text complexity. Across six languages, including Arabic, Dutch, English, French, Hindi, and Russian, we evaluate three open-weight models, one closed model, and a commercial machine translation system on two tasks: i) correlation of CEFR with translation difficulty, and ii) shifts in CEFR levels of the source texts. Our experiments show that higher CEFR levels make texts more difficult to translate, and that machine translation shifts the CEFR level of the target text compared to the original source, for most languages. These findings provide new insights for researchers and practitioners working on multilingual pedagogical content generation and machine translation difficulty estimation.
Translating Classical Poetry into Modern Prose
Jun 01, 2026We introduce Padyam2Gadyam, a dataset for the task of poem-to-prose translation from 13th-17th Century Telugu Classical Poetry to contemporary Telugu and English prose. The dataset consists of 600 poems and their human-verified Telugu and English prose translations. We evaluated 5 contemporary Large Language Models (LLMs) on their ability to do poem-to-prose translation into Telugu and English. Our results indicate that while there are differences across LLMs, their overall performance leave a large room for improvement in both languages. Through qualitative analysis, we discuss the the capabilities and limitations of contemporary MT evaluation approaches for this task.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Improving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
Improving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
IndicGEC: Powerful Models, or a Measurement Mirage?
Nov 19, 2025In this paper, we report the results of the TeamNRC's participation in the BHASHA-Task 1 Grammatical Error Correction shared task https://github.com/BHASHA-Workshop/IndicGEC2025/ for 5 Indian languages. Our approach, focusing on zero/few-shot prompting of language models of varying sizes (4B to large proprietary models) achieved a Rank 4 in Telugu and Rank 2 in Hindi with GLEU scores of 83.78 and 84.31 respectively. In this paper, we extend the experiments to the other three languages of the shared task - Tamil, Malayalam and Bangla, and take a closer look at the data quality and evaluation metric used. Our results primarily highlight the potential of small language models, and summarize the concerns related to creating good quality datasets and appropriate metrics for this task that are suitable for Indian language scripts.
Opportunities and Challenges of LLMs in Education: An NLP Perspective
Jul 30, 2025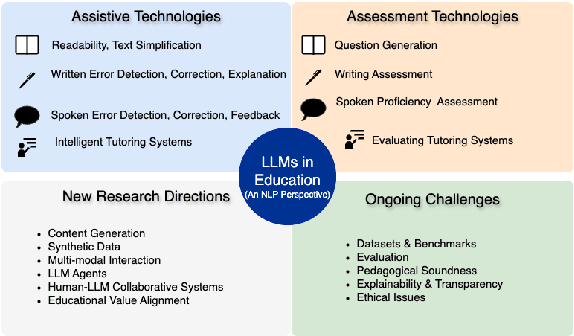


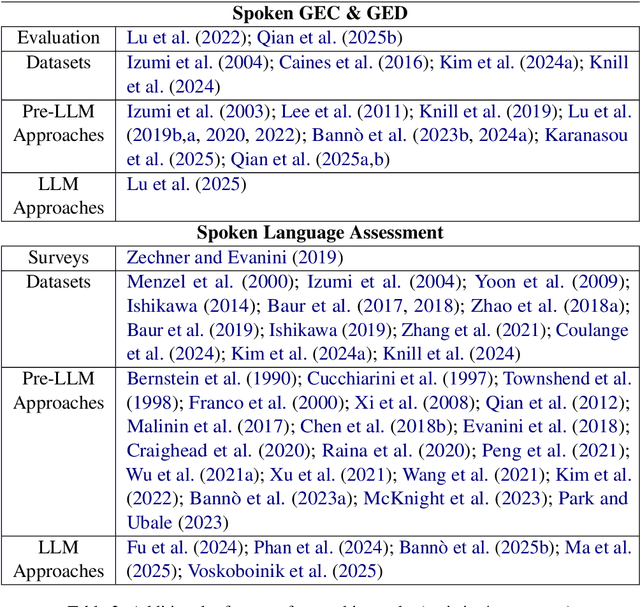
Interest in the role of large language models (LLMs) in education is increasing, considering the new opportunities they offer for teaching, learning, and assessment. In this paper, we examine the impact of LLMs on educational NLP in the context of two main application scenarios: {\em assistance} and {\em assessment}, grounding them along the four dimensions -- reading, writing, speaking, and tutoring. We then present the new directions enabled by LLMs, and the key challenges to address. We envision that this holistic overview would be useful for NLP researchers and practitioners interested in exploring the role of LLMs in developing language-focused and NLP-enabled educational applications of the future.
The Problem with Safety Classification is not just the Models
Jul 29, 2025Studying the robustness of Large Language Models (LLMs) to unsafe behaviors is an important topic of research today. Building safety classification models or guard models, which are fine-tuned models for input/output safety classification for LLMs, is seen as one of the solutions to address the issue. Although there is a lot of research on the safety testing of LLMs themselves, there is little research on evaluating the effectiveness of such safety classifiers or the evaluation datasets used for testing them, especially in multilingual scenarios. In this position paper, we demonstrate how multilingual disparities exist in 5 safety classification models by considering datasets covering 18 languages. At the same time, we identify potential issues with the evaluation datasets, arguing that the shortcomings of current safety classifiers are not only because of the models themselves. We expect that these findings will contribute to the discussion on developing better methods to identify harmful content in LLM inputs across languages.
Does Synthetic Data Help Named Entity Recognition for Low-Resource Languages?
May 22, 2025



Named Entity Recognition(NER) for low-resource languages aims to produce robust systems for languages where there is limited labeled training data available, and has been an area of increasing interest within NLP. Data augmentation for increasing the amount of low-resource labeled data is a common practice. In this paper, we explore the role of synthetic data in the context of multilingual, low-resource NER, considering 11 languages from diverse language families. Our results suggest that synthetic data does in fact hold promise for low-resource language NER, though we see significant variation between languages.
Text Classification in the LLM Era - Where do we stand?
Feb 17, 2025Large Language Models revolutionized NLP and showed dramatic performance improvements across several tasks. In this paper, we investigated the role of such language models in text classification and how they compare with other approaches relying on smaller pre-trained language models. Considering 32 datasets spanning 8 languages, we compared zero-shot classification, few-shot fine-tuning and synthetic data based classifiers with classifiers built using the complete human labeled dataset. Our results show that zero-shot approaches do well for sentiment classification, but are outperformed by other approaches for the rest of the tasks, and synthetic data sourced from multiple LLMs can build better classifiers than zero-shot open LLMs. We also see wide performance disparities across languages in all the classification scenarios. We expect that these findings would guide practitioners working on developing text classification systems across languages.