 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Text Simplification of News Articles in the Context of Public Broadcasting
Dec 26, 2022This report summarizes the work carried out by the authors during the Twelfth Montreal Industrial Problem Solving Workshop, held at Universit\'e de Montr\'eal in August 2022. The team tackled a problem submitted by CBC/Radio-Canada on the theme of Automatic Text Simplification (ATS).
An Iterative Contextualization Algorithm with Second-Order Attention
Mar 03, 2021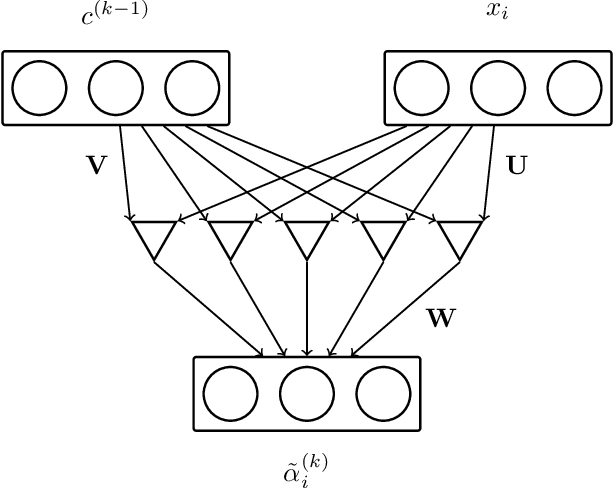
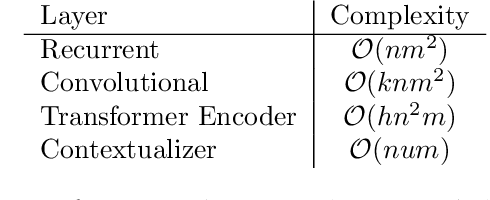

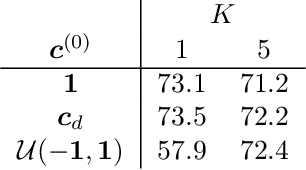
Combining the representations of the words that make up a sentence into a cohesive whole is difficult, since it needs to account for the order of words, and to establish how the words present relate to each other. The solution we propose consists in iteratively adjusting the context. Our algorithm starts with a presumably erroneous value of the context, and adjusts this value with respect to the tokens at hand. In order to achieve this, representations of words are built combining their symbolic embedding with a positional encoding into single vectors. The algorithm then iteratively weighs and aggregates these vectors using our novel second-order attention mechanism. Our models report strong results in several well-known text classification tasks.
Inter and Intra Document Attention for Depression Risk Assessment
Jun 30, 2019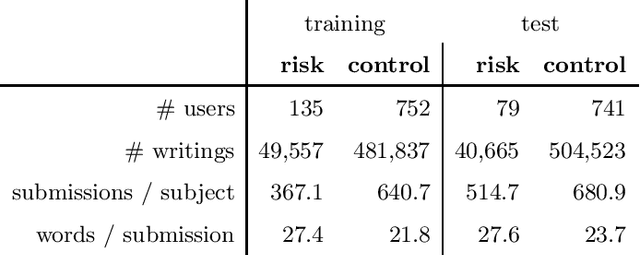
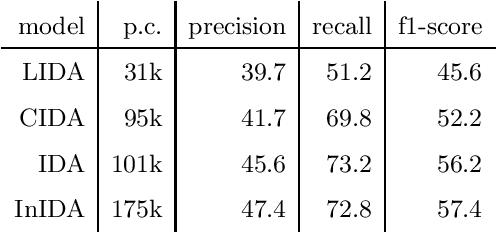
We take interest in the early assessment of risk for depression in social media users. We focus on the eRisk 2018 dataset, which represents users as a sequence of their written online contributions. We implement four RNN-based systems to classify the users. We explore several aggregations methods to combine predictions on individual posts. Our best model reads through all writings of a user in parallel but uses an attention mechanism to prioritize the most important ones at each timestep.
Multiplicative Models for Recurrent Language Modeling
Jun 30, 2019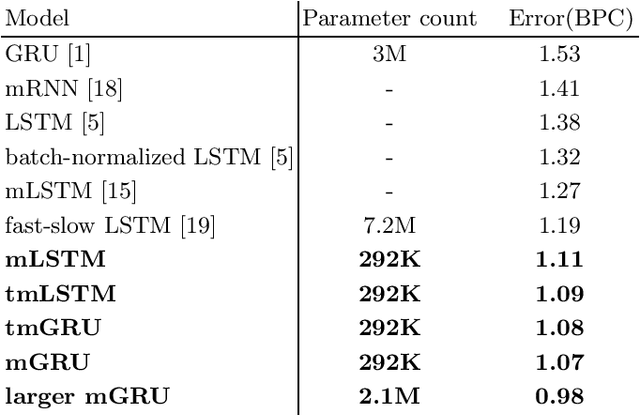
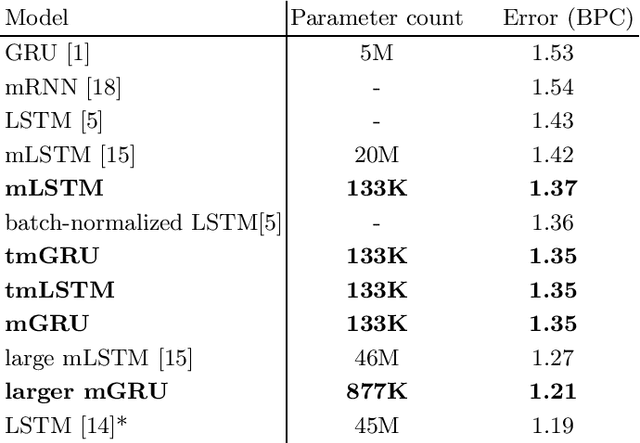
Recently, there has been interest in multiplicative recurrent neural networks for language modeling. Indeed, simple Recurrent Neural Networks (RNNs) encounter difficulties recovering from past mistakes when generating sequences due to high correlation between hidden states. These challenges can be mitigated by integrating second-order terms in the hidden-state update. One such model, multiplicative Long Short-Term Memory (mLSTM) is particularly interesting in its original formulation because of the sharing of its second-order term, referred to as the intermediate state. We explore these architectural improvements by introducing new models and testing them on character-level language modeling tasks. This allows us to establish the relevance of shared parametrization in recurrent language modeling.