 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention-Based Deep Learning Architecture for Real-Time Monocular Visual Odometry: Applications to GPS-free Drone Navigation
Apr 27, 2024Drones are increasingly used in fields like industry, medicine, research, disaster relief, defense, and security. Technical challenges, such as navigation in GPS-denied environments, hinder further adoption. Research in visual odometry is advancing, potentially solving GPS-free navigation issues. Traditional visual odometry methods use geometry-based pipelines which, while popular, often suffer from error accumulation and high computational demands. Recent studies utilizing deep neural networks (DNNs) have shown improved performance, addressing these drawbacks. Deep visual odometry typically employs convolutional neural networks (CNNs) and sequence modeling networks like recurrent neural networks (RNNs) to interpret scenes and deduce visual odometry from video sequences. This paper presents a novel real-time monocular visual odometry model for drones, using a deep neural architecture with a self-attention module. It estimates the ego-motion of a camera on a drone, using consecutive video frames. An inference utility processes the live video feed, employing deep learning to estimate the drone's trajectory. The architecture combines a CNN for image feature extraction and a long short-term memory (LSTM) network with a multi-head attention module for video sequence modeling. Tested on two visual odometry datasets, this model converged 48% faster than a previous RNN model and showed a 22% reduction in mean translational drift and a 12% improvement in mean translational absolute trajectory error, demonstrating enhanced robustness to noise.
Automatic Text Simplification of News Articles in the Context of Public Broadcasting
Dec 26, 2022This report summarizes the work carried out by the authors during the Twelfth Montreal Industrial Problem Solving Workshop, held at Universit\'e de Montr\'eal in August 2022. The team tackled a problem submitted by CBC/Radio-Canada on the theme of Automatic Text Simplification (ATS).
Fast and Optimal Laplacian Solver for Gradient-Domain Image Editing using Green Function Convolution
Feb 01, 2019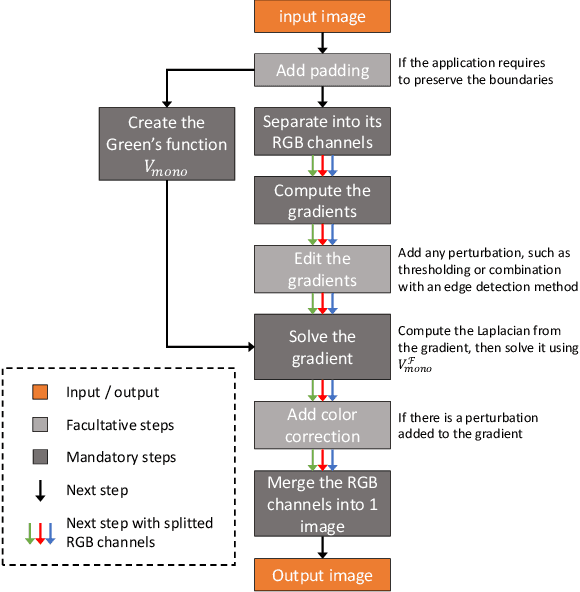
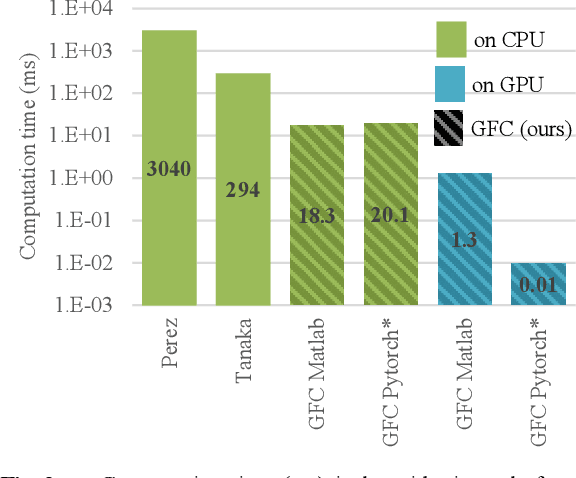
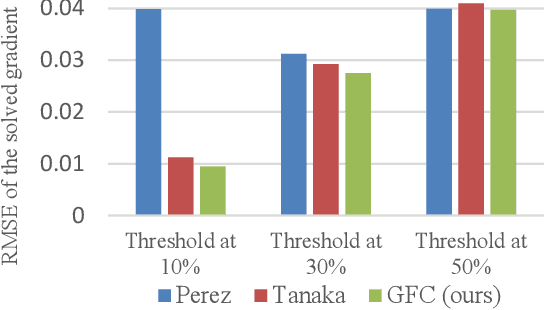
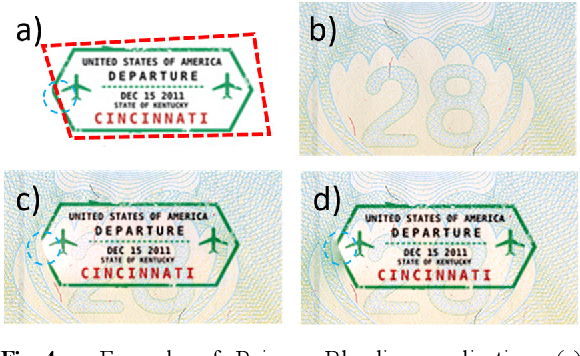
In computer vision, the gradient and Laplacian of an image are used in many different applications, such as edge detection, feature extraction and seamless image cloning. To obtain the gradient of an image, it requires the use of numerical derivatives, which are available in most computer vision toolboxes. However, the reverse problem is more difficult, since computing an image from its gradient requires to solve the Laplacian differential equation. The problem with the current existing methods is that they provide a solution that is prone to high numerical errors, and that they are either slow or require heavy parallel computing. The objective of this paper is to present a novel fast and robust method of computing the image from its gradient or Laplacian with minimal error, which can be used for gradient-domain editing. By using a single convolution based on Green's function, the whole process is faster and easier to implement. It can also be optimized on a GPU using fast Fourier transforms and can easily be generalized for an n-dimension image. The tests show that the gradient solver takes around 2 milliseconds (ms) to reconstruct an image of 801x1200 pixels compared to between 6ms and 3000ms for competing methods. Furthermore, it is proven mathematically that the proposed method gives the optimal result when a perturbation is added, meaning that it always produces the least-error solution for gradient-domain editing. Finally, the developed method is validated with examples of Poisson blending, gradient removal, edge preserving blurring and edge-preserving painting effect.