 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Machine learning algorithms to identify the Cobb angle in adolescents with idiopathic scoliosis based on lumbosacral joint efforts during gait (Case study)
Jan 29, 2023Objectives: To quantify the magnitude of spinal deformity in adolescent idiopathic scoliosis (AIS), the Cobb angle is measured on X-ray images of the spine. Continuous exposure to X-ray radiation to follow-up the progression of scoliosis may lead to negative side effects on patients. Furthermore, manual measurement of the Cobb angle could lead to up to 10{\deg} or more of a difference due to intra/inter observer variation. Therefore, the objective of this study is to identify the Cobb angle by developing an automated radiation-free model, using Machine learning algorithms. Methods: Thirty participants with lumbar/thoracolumbar AIS (15{\deg} < Cobb angle < 66{\deg}) performed gait cycles. The lumbosacral (L5-S1) joint efforts during six gait cycles of participants were used as features to feed training algorithms. Various regression algorithms were implemented and run. Results: The decision tree regression algorithm achieved the best result with the mean absolute error equal to 4.6{\deg} of averaged 10-fold cross-validation. Conclusions: This study shows that the lumbosacral joint efforts during gait as radiation-free data are capable to identify the Cobb angle by using Machine learning algorithms. The proposed model can be considered as an alternative, radiation-free method to X-ray radiography to assist clinicians in following-up the progression of AIS.
A Test Bench For Evaluating Exoskeletons For Upper Limb Rehabilitation
Dec 30, 2021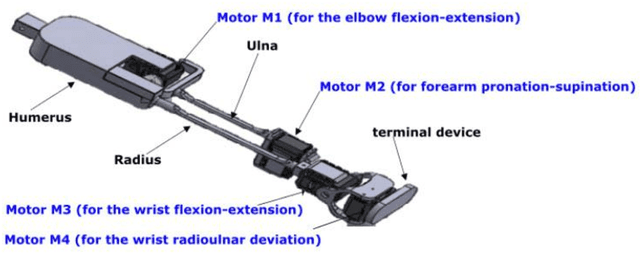
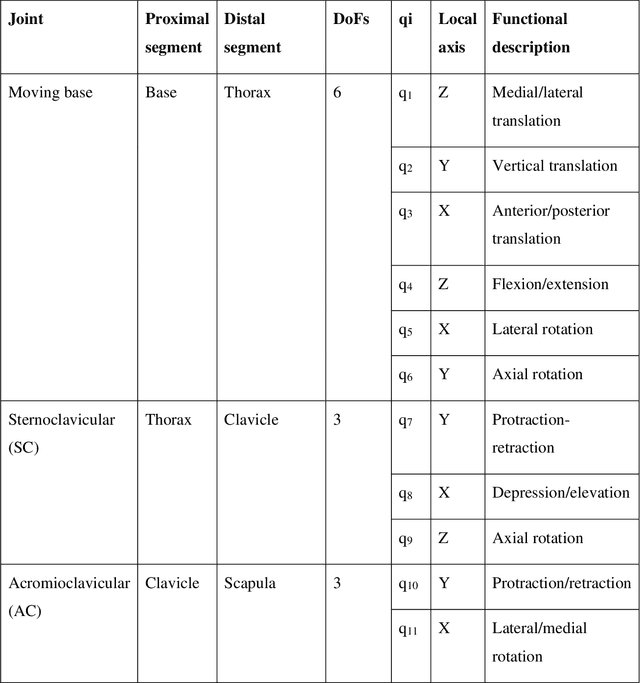
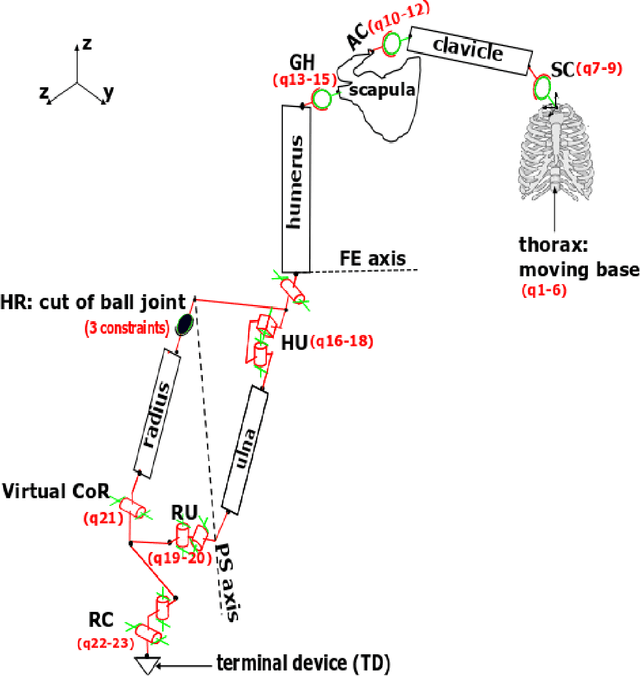
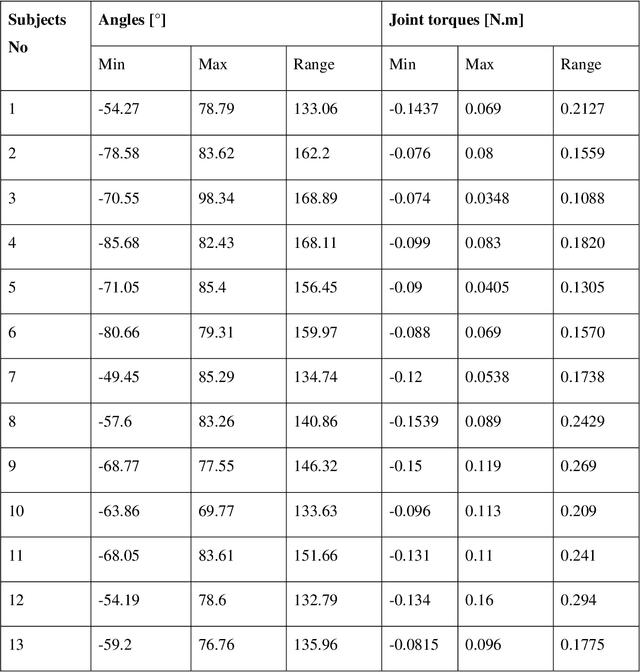
The potential of wearable robotics technology is undeniable. However, quantifying its value is difficult. Various types of exoskeleton robots have already been developed and tested for upper limb rehabilitation but, evaluations are not standardized, particularly in pediatric rehabilitation. This paper proposes a methodology for the quantitative evaluation of upper limb exoskeletons that, like a test bench, would serve for replicable testing. We determined the range of motion (ROM) and joint torques using both kinematic modeling and experimental measurements (using sensors integrated into Dynamixel actuators). The proposed test bench can provide an accurate range of motion (ROM) and joint torques during the pronation-supination (PS) task. The range of motion obtained with the physical prototype was approximately 156.26 +- 4.71{\deg} during the PS task, while it was approximately 146.84 +- 14.32{\deg} for the multibody model. The results show that the average range of experimental torques (0.28 +- 0.06 N.m) was overestimated by 40% and just 3.4%, respectively, when compared to the average range of simulated torques (0.2 +- 0.05 N.m) and to the highest range of simulated torques (0.29 N.m). For the experimental measurements, test-retest reliability was excellent (0.96-0.98) within sessions and excellent (0.93) or good (0.81-0.86) between sessions. Finally, the suggested approach provides a ROM close to the normal ROM necessary during PS tasks. These results validate the measurements' accuracy and underline the proposed methodology's relevance. The proposed test bench could become a reference standard for evaluating exoskeletons. This study also addresses a methodological aspect on the accurate assessment of joint torques that can serve in applications such as the sizing of actuators in exoskeletons or the non-invasive evaluation of muscle forces in the human body.
Improving Convolutional Neural Networks Via Conservative Field Regularisation and Integration
Mar 11, 2020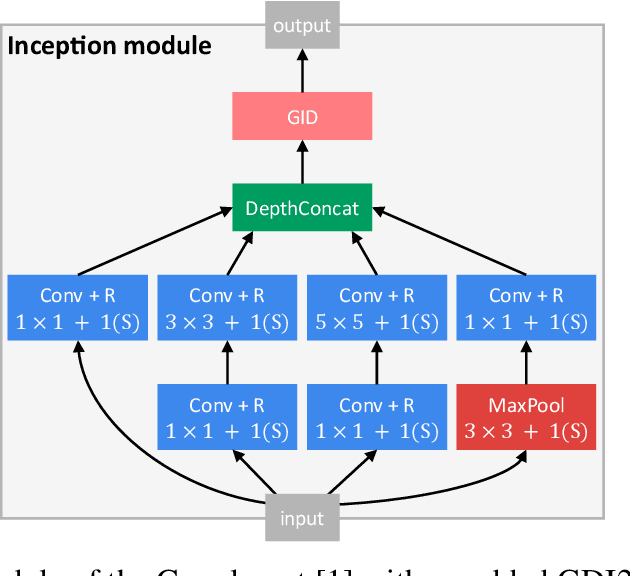
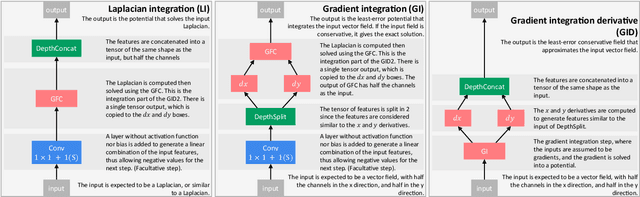
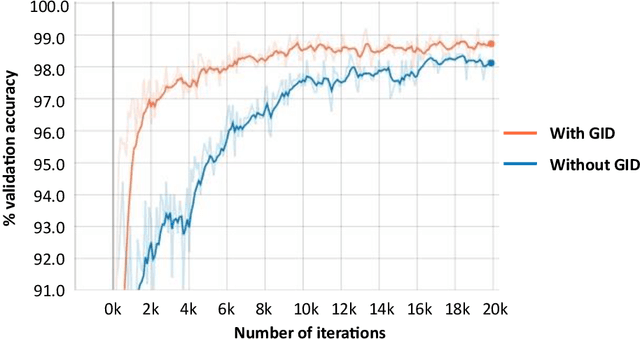
Current research in convolutional neural networks (CNN) focuses mainly on changing the architecture of the networks, optimizing the hyper-parameters and improving the gradient descent. However, most work use only 3 standard families of operations inside the CNN, the convolution, the activation function, and the pooling. In this work, we propose a new family of operations based on the Green's function of the Laplacian, which allows the network to solve the Laplacian, to integrate any vector field and to regularize the field by forcing it to be conservative. Hence, the Green's function (GF) is the first operation that regularizes the 2D or 3D feature space by forcing it to be conservative and physically interpretable, instead of regularizing the norm of the weights. Our results show that such regularization allows the network to learn faster, to have smoother training curves and to better generalize, without any additional parameter. The current manuscript presents early results, more work is required to benchmark the proposed method.
Saliency Enhancement using Gradient Domain Edges Merging
Feb 11, 2020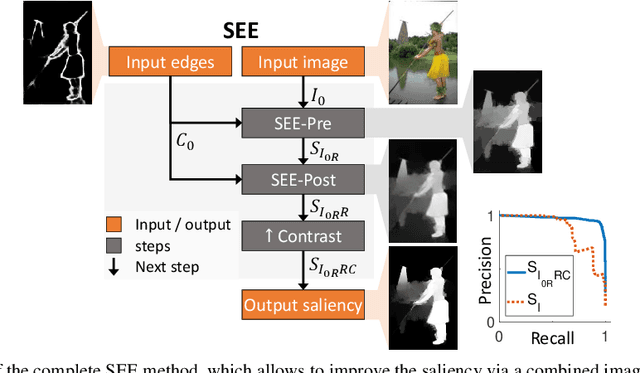
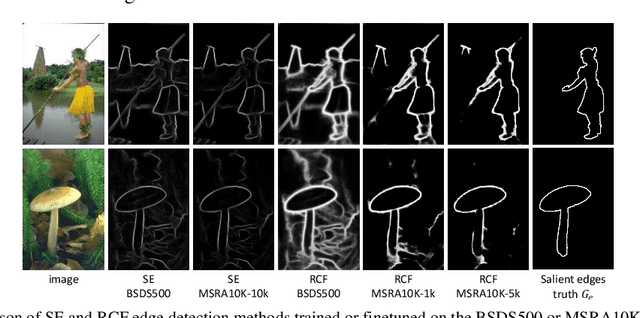
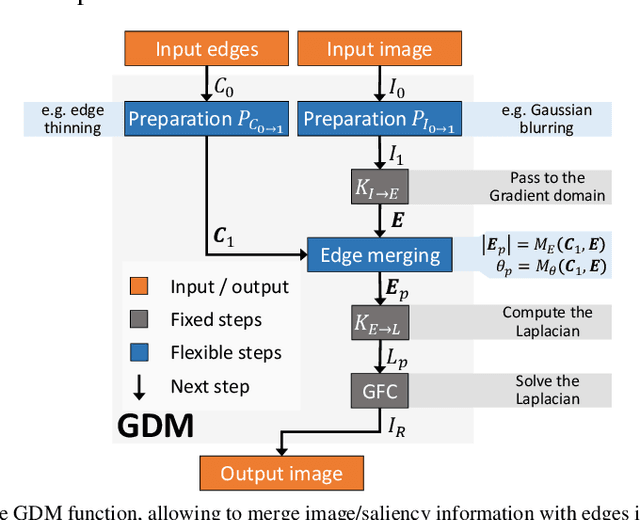
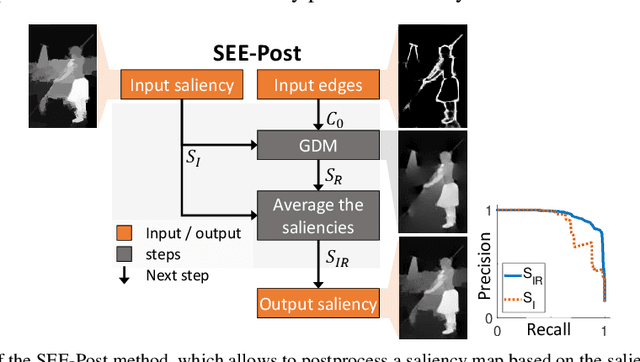
In recent years, there has been a rapid progress in solving the binary problems in computer vision, such as edge detection which finds the boundaries of an image and salient object detection which finds the important object in an image. This progress happened thanks to the rise of deep-learning and convolutional neural networks (CNN) which allow to extract complex and abstract features. However, edge detection and saliency are still two different fields and do not interact together, although it is intuitive for a human to detect salient objects based on its boundaries. Those features are not well merged in a CNN because edges and surfaces do not intersect since one feature represents a region while the other represents boundaries between different regions. In the current work, the main objective is to develop a method to merge the edges with the saliency maps to improve the performance of the saliency. Hence, we developed the gradient-domain merging (GDM) which can be used to quickly combine the image-domain information of salient object detection with the gradient-domain information of the edge detection. This leads to our proposed saliency enhancement using edges (SEE) with an average improvement of the F-measure of at least 3.4 times higher on the DUT-OMRON dataset and 6.6 times higher on the ECSSD dataset, when compared to competing algorithm such as denseCRF and BGOF. The SEE algorithm is split into 2 parts, SEE-Pre for preprocessing and SEE-Post pour postprocessing.
Design of an assistive trunk exoskeleton based on multibody dynamic modelling
Oct 02, 2019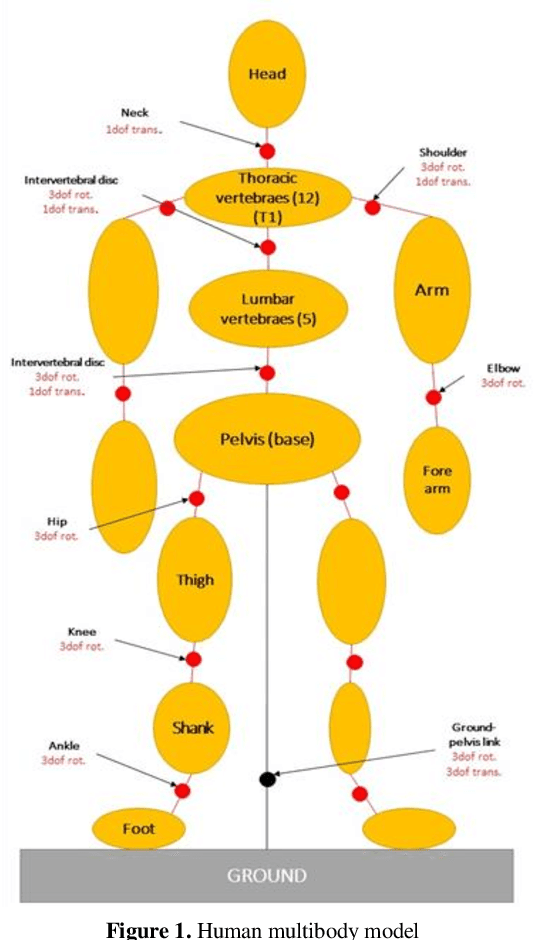
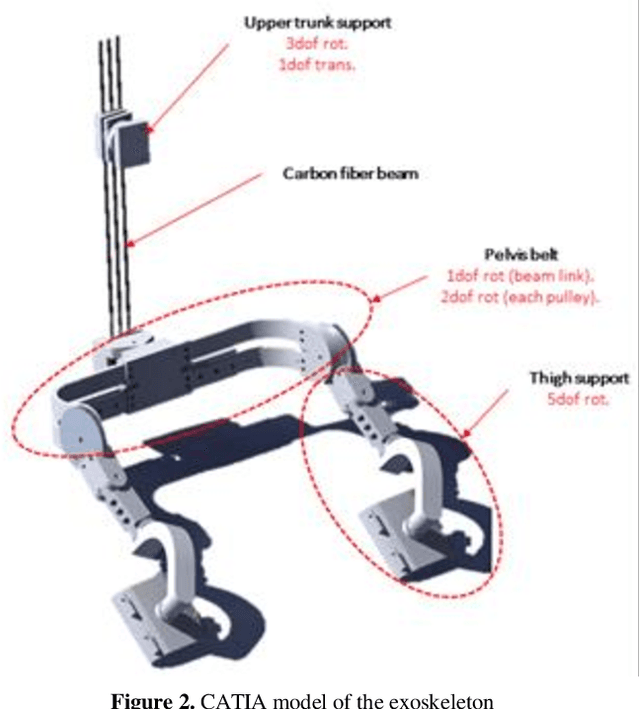
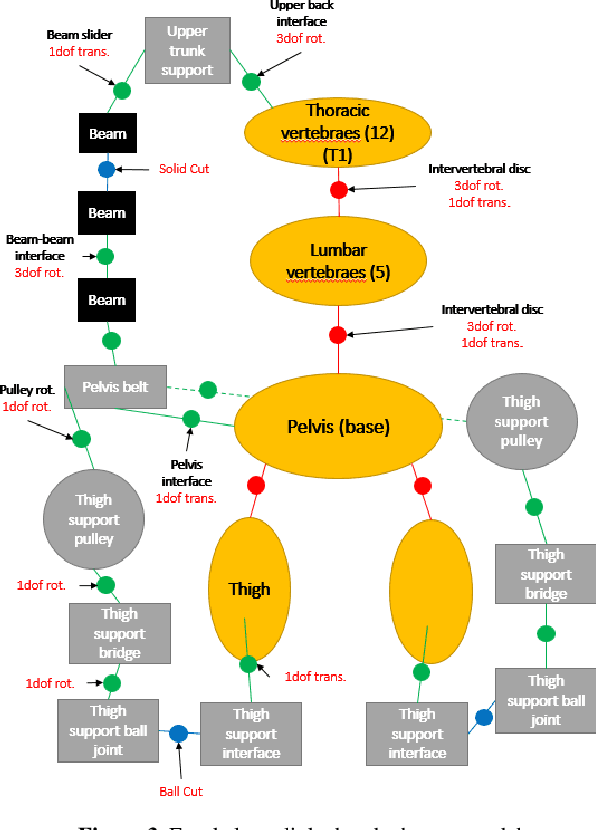
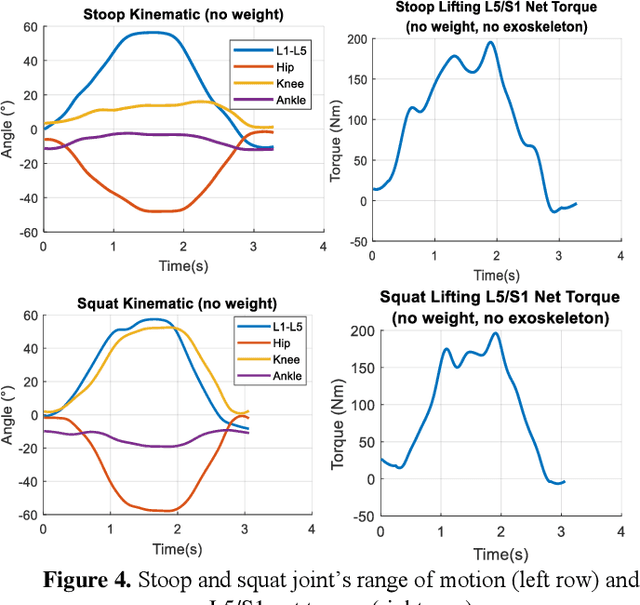
Low back pain is one of the most common musculoskeletal disorder. To reduce its incidences, some back exoskeletons have been designed and already commercialized. However, there is a gap between the phases of device and testing on subjects. In fact, the main unsolved problem is the lack of realistic simulation of human-device interaction. Consequently, the objective of this paper is to design a 3D multibody model of the human body that includes the full thoracic and lumbar spine combined with a low back exoskeleton, enabling to analyze the interactions between them. The results highlight that the use of the exoskeleton reduces the net torque in the lower lumbar spine but creates normal forces transmitted through the thighs and the pelvis, which should also be considered for low back pain. As a perspective, this model would enable to redesign low back exoskeletons reducing both torques and forces in the human joints in a realistic dynamic context.
Deep Green Function Convolution for Improving Saliency in Convolutional Neural Networks
Aug 22, 2019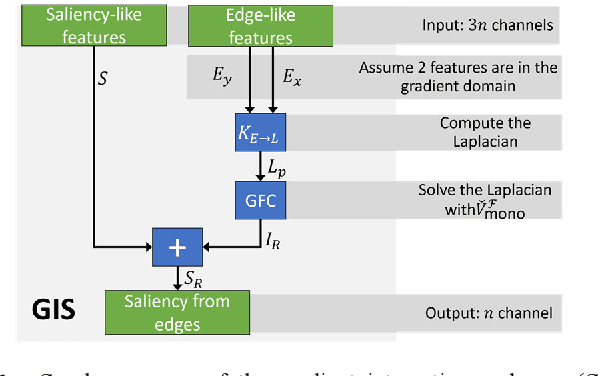
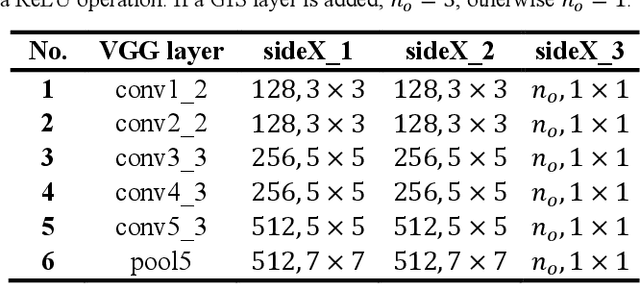
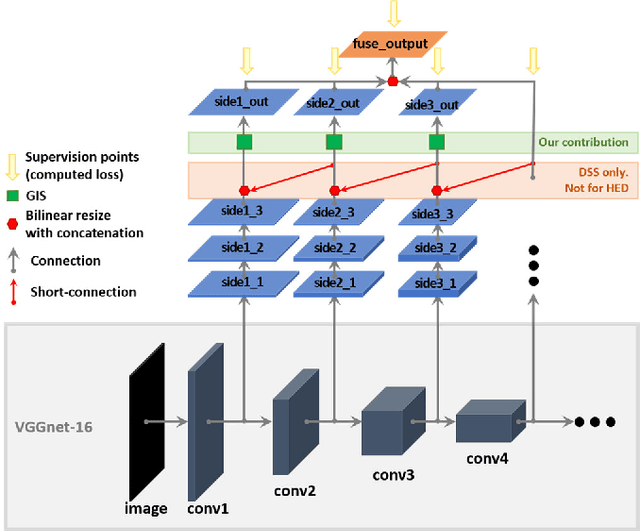
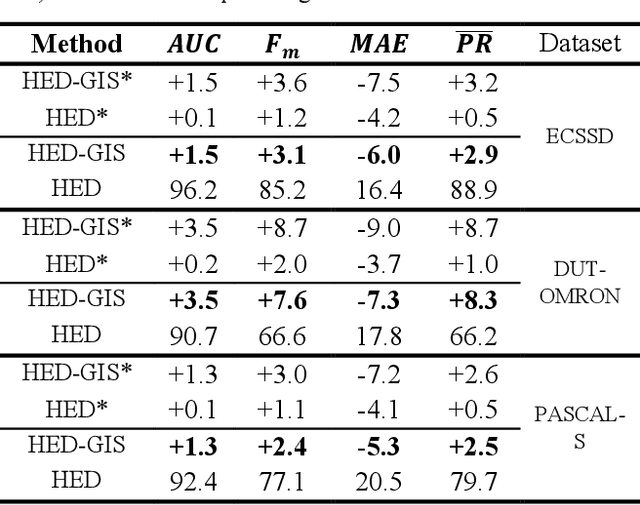
Current saliency methods require to learn large scale regional features using small convolutional kernels, which is not possible with a simple feed-forward network. Some methods solve this problem by using segmentation into superpixels while others downscale the image through the network and rescale it back to its original size. The objective of this paper is to show that saliency convolutional neural networks (CNN) can be improved by using a Green's function convolution (GFC) to extrapolate edges features into salient regions. The GFC acts as a gradient integrator, allowing to produce saliency features from thin edge-like features directly inside the CNN. Hence, we propose the gradient integration and sum (GIS) layer that combines the edges features with the saliency features. Using the HED and DSS architecture, we demonstrated that adding a GIS layer near the network's output allows to reduce the sensitivity to the parameter initialization and overfitting, thus improving the repeatability of the training. By adding a GIS layer to the state-of-the-art DSS model, there is an increase of 1.6% for the F-measure on the DUT-OMRON dataset, with only 10ms of additional computation time. The GIS layer further allows the network to perform significantly better in the case of highly noisy images or low-brightness images. In fact, we observed an F-measure improvement of 5.2% on noisy images and 2.8% on low-light images. Since the GIS layer is model agnostic, it can be implemented inside different fully convolutional networks, and it outperforms the denseCRF post-processing method and is 40 times faster. A major contribution of the current work is the first implementation of Green's function convolution inside a neural network, which allows the network, via very minor architectural changes and no additional parameters, to operate in the feature domain and in the gradient domain at the same time.
Fast and Optimal Laplacian Solver for Gradient-Domain Image Editing using Green Function Convolution
Feb 01, 2019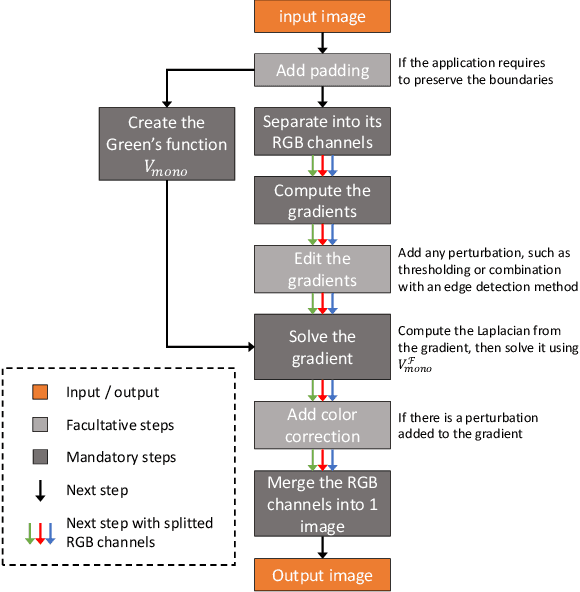
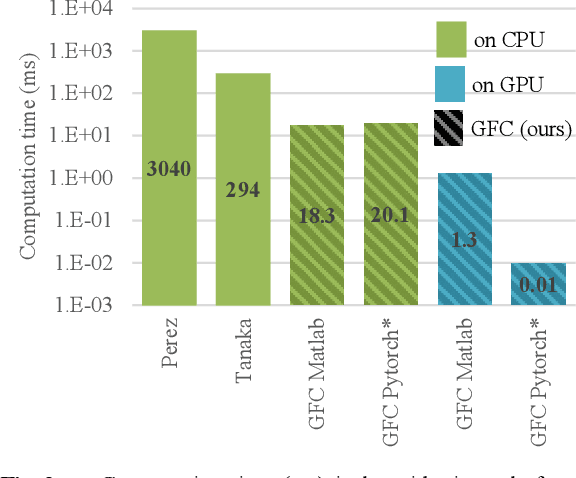
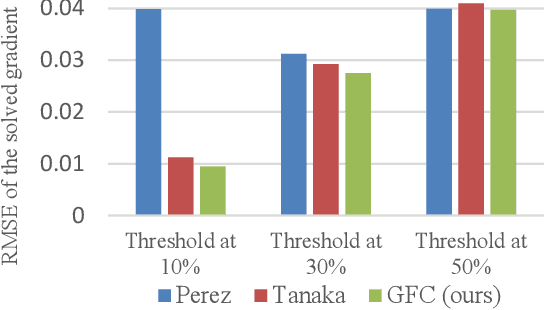
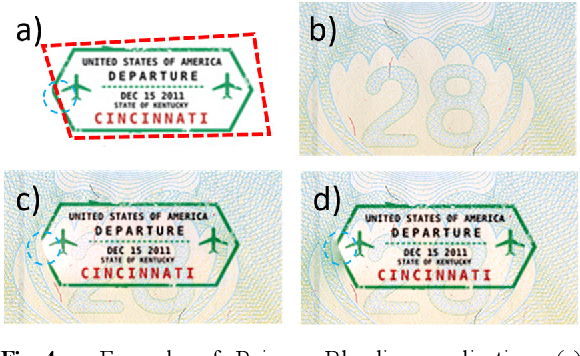
In computer vision, the gradient and Laplacian of an image are used in many different applications, such as edge detection, feature extraction and seamless image cloning. To obtain the gradient of an image, it requires the use of numerical derivatives, which are available in most computer vision toolboxes. However, the reverse problem is more difficult, since computing an image from its gradient requires to solve the Laplacian differential equation. The problem with the current existing methods is that they provide a solution that is prone to high numerical errors, and that they are either slow or require heavy parallel computing. The objective of this paper is to present a novel fast and robust method of computing the image from its gradient or Laplacian with minimal error, which can be used for gradient-domain editing. By using a single convolution based on Green's function, the whole process is faster and easier to implement. It can also be optimized on a GPU using fast Fourier transforms and can easily be generalized for an n-dimension image. The tests show that the gradient solver takes around 2 milliseconds (ms) to reconstruct an image of 801x1200 pixels compared to between 6ms and 3000ms for competing methods. Furthermore, it is proven mathematically that the proposed method gives the optimal result when a perturbation is added, meaning that it always produces the least-error solution for gradient-domain editing. Finally, the developed method is validated with examples of Poisson blending, gradient removal, edge preserving blurring and edge-preserving painting effect.
Novel Convolution Kernels for Computer Vision and Shape Analysis based on Electromagnetism
Jun 20, 2018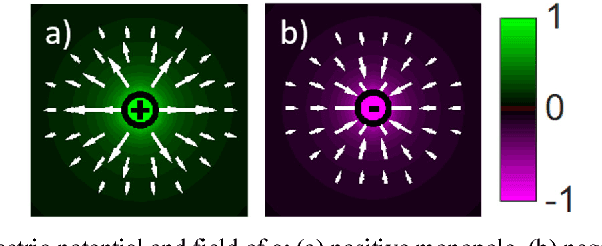

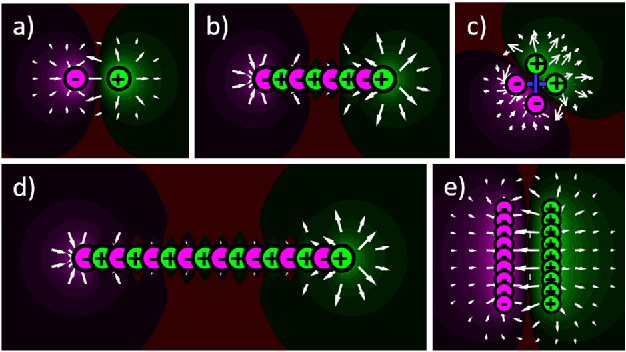
Computer vision is a growing field with a lot of new applications in automation and robotics, since it allows the analysis of images and shapes for the generation of numerical or analytical information. One of the most used method of information extraction is image filtering through convolution kernels, with each kernel specialized for specific applications. The objective of this paper is to present a novel convolution kernels, based on principles of electromagnetic potentials and fields, for a general use in computer vision and to demonstrate its usage for shape and stroke analysis. Such filtering possesses unique geometrical properties that can be interpreted using well understood physics theorems. Therefore, this paper focuses on the development of the electromagnetic kernels and on their application on images for shape and stroke analysis. It also presents several interesting features of electromagnetic kernels, such as resolution, size and orientation independence, robustness to noise and deformation, long distance stroke interaction and ability to work with 3D images
* Keywords: Shape analysis; Stroke analysis; Computer vision; Electromagnetic potential field; Feature extraction; Image filtering; Image convolution Published in PolyPublie: https://publications.polymtl.ca/3162/
Computing the Spatial Probability of Inclusion inside Partial Contours for Computer Vision Applications
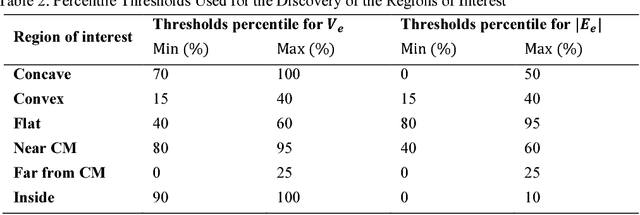
Jun 04, 2018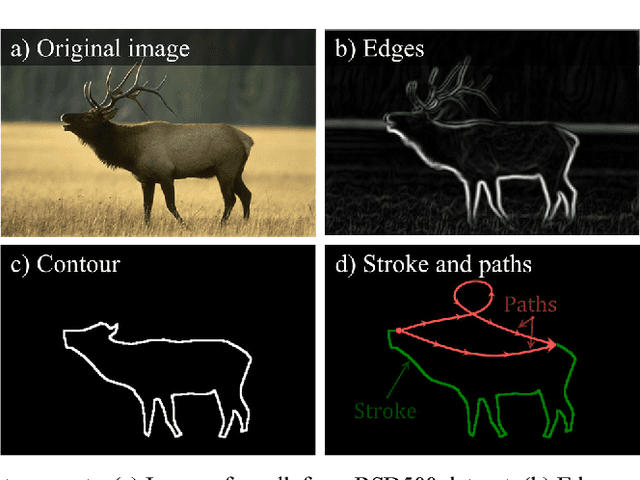

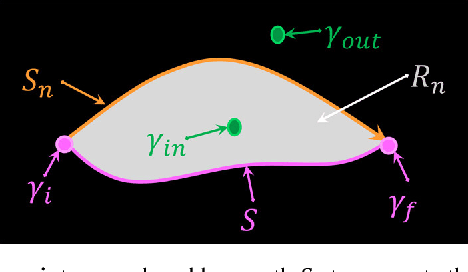
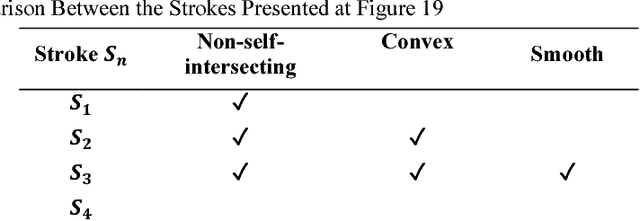
In Computer Vision, edge detection is one of the favored approaches for feature and object detection in images since it provides information about their objects boundaries. Other region-based approaches use probabilistic analysis such as clustering and Markov random fields, but those methods cannot be used to analyze edges and their interaction. In fact, only image segmentation can produce regions based on edges, but it requires thresholding by simply separating the regions into binary in-out information. Hence, there is currently a gap between edge-based and region-based algorithms, since edges cannot be used to study the properties of a region and vice versa. The objective of this paper is to present a novel spatial probability analysis that allows determining the probability of inclusion inside a set of partial contours (strokes). To answer this objective, we developed a new approach that uses electromagnetic convolutions and repulsion optimization to compute the required probabilities. Hence, it becomes possible to generate a continuous space of probability based only on the edge information, thus bridging the gap between the edge-based methods and the region-based methods. The developed method is consistent with the fundamental properties of inclusion probabilities and its results are validated by comparing an image with the probability-based estimation given by our algorithm. The method can also be generalized to take into consideration the intensity of the edges or to be used for 3D shapes. This is the first documented method that allows computing a space of probability based on interacting edges, which opens the path to broader applications such as image segmentation and contour completion.