 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Green Function Convolution for Improving Saliency in Convolutional Neural Networks
Paper and Code
Aug 22, 2019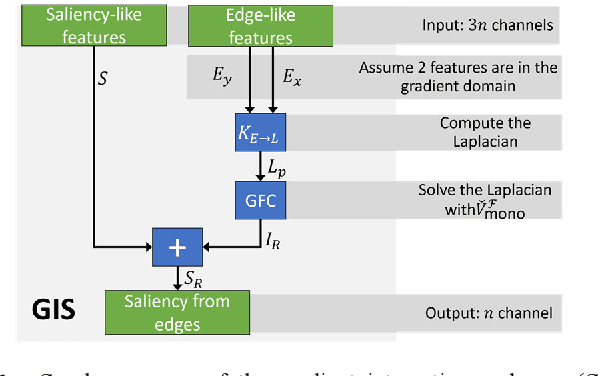
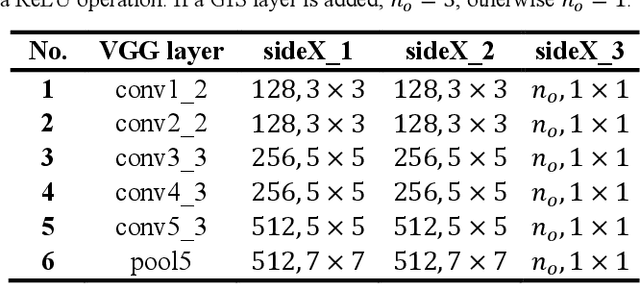
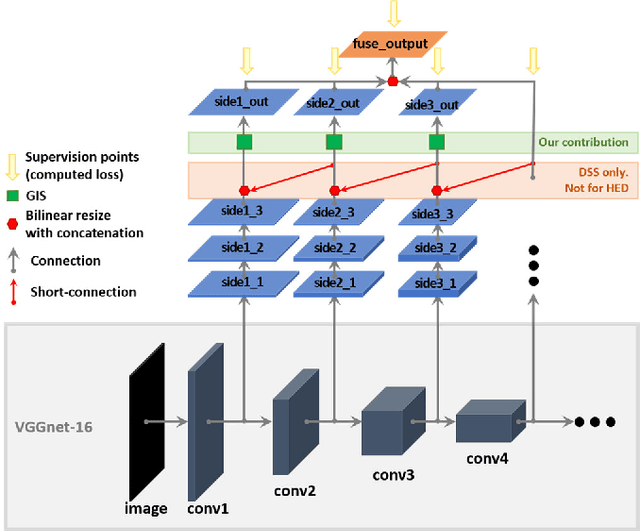
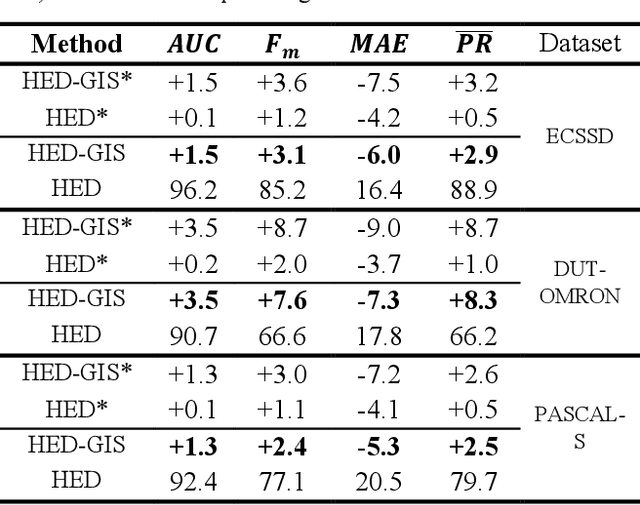
Current saliency methods require to learn large scale regional features using small convolutional kernels, which is not possible with a simple feed-forward network. Some methods solve this problem by using segmentation into superpixels while others downscale the image through the network and rescale it back to its original size. The objective of this paper is to show that saliency convolutional neural networks (CNN) can be improved by using a Green's function convolution (GFC) to extrapolate edges features into salient regions. The GFC acts as a gradient integrator, allowing to produce saliency features from thin edge-like features directly inside the CNN. Hence, we propose the gradient integration and sum (GIS) layer that combines the edges features with the saliency features. Using the HED and DSS architecture, we demonstrated that adding a GIS layer near the network's output allows to reduce the sensitivity to the parameter initialization and overfitting, thus improving the repeatability of the training. By adding a GIS layer to the state-of-the-art DSS model, there is an increase of 1.6% for the F-measure on the DUT-OMRON dataset, with only 10ms of additional computation time. The GIS layer further allows the network to perform significantly better in the case of highly noisy images or low-brightness images. In fact, we observed an F-measure improvement of 5.2% on noisy images and 2.8% on low-light images. Since the GIS layer is model agnostic, it can be implemented inside different fully convolutional networks, and it outperforms the denseCRF post-processing method and is 40 times faster. A major contribution of the current work is the first implementation of Green's function convolution inside a neural network, which allows the network, via very minor architectural changes and no additional parameters, to operate in the feature domain and in the gradient domain at the same time.