 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Adaptation for French Named Entity Recognition
Jan 12, 2023

Named Entity Recognition (NER) is the task of identifying and classifying named entities in large-scale texts into predefined classes. NER in French and other relatively limited-resource languages cannot always benefit from approaches proposed for languages like English due to a dearth of large, robust datasets. In this paper, we present our work that aims to mitigate the effects of this dearth of large, labeled datasets. We propose a Transformer-based NER approach for French, using adversarial adaptation to similar domain or general corpora to improve feature extraction and enable better generalization. Our approach allows learning better features using large-scale unlabeled corpora from the same domain or mixed domains to introduce more variations during training and reduce overfitting. Experimental results on three labeled datasets show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of Transformer models, source datasets, and target corpora. We also show that adversarial adaptation to large-scale unlabeled corpora can help mitigate the performance dip incurred on using Transformer models pre-trained on smaller corpora.
Automatic Text Simplification of News Articles in the Context of Public Broadcasting
Dec 26, 2022This report summarizes the work carried out by the authors during the Twelfth Montreal Industrial Problem Solving Workshop, held at Universit\'e de Montr\'eal in August 2022. The team tackled a problem submitted by CBC/Radio-Canada on the theme of Automatic Text Simplification (ATS).
Personalized Student Attribute Inference
Dec 26, 2022Accurately predicting their future performance can ensure students successful graduation, and help them save both time and money. However, achieving such predictions faces two challenges, mainly due to the diversity of students' background and the necessity of continuously tracking their evolving progress. The goal of this work is to create a system able to automatically detect students in difficulty, for instance predicting if they are likely to fail a course. We compare a naive approach widely used in the literature, which uses attributes available in the data set (like the grades), with a personalized approach we called Personalized Student Attribute Inference (PSAI). With our model, we create personalized attributes to capture the specific background of each student. Both approaches are compared using machine learning algorithms like decision trees, support vector machine or neural networks.
Transformer-Based Named Entity Recognition for French Using Adversarial Adaptation to Similar Domain Corpora
Dec 05, 2022
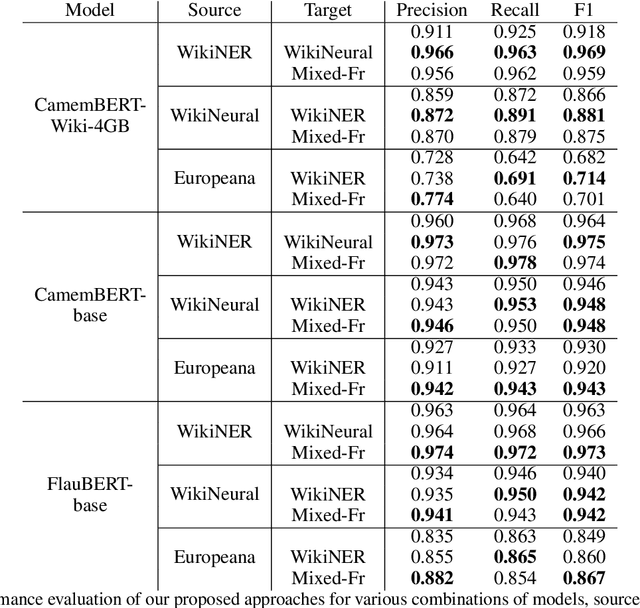
Named Entity Recognition (NER) involves the identification and classification of named entities in unstructured text into predefined classes. NER in languages with limited resources, like French, is still an open problem due to the lack of large, robust, labelled datasets. In this paper, we propose a transformer-based NER approach for French using adversarial adaptation to similar domain or general corpora for improved feature extraction and better generalization. We evaluate our approach on three labelled datasets and show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of transformer models, source datasets and target corpora.
Quick Starting Dialog Systems with Paraphrase Generation
Apr 06, 2022

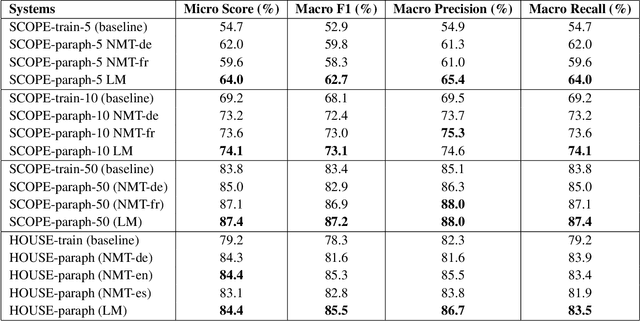
Acquiring training data to improve the robustness of dialog systems can be a painstakingly long process. In this work, we propose a method to reduce the cost and effort of creating new conversational agents by artificially generating more data from existing examples, using paraphrase generation. Our proposed approach can kick-start a dialog system with little human effort, and brings its performance to a level satisfactory enough for allowing actual interactions with real end-users. We experimented with two neural paraphrasing approaches, namely Neural Machine Translation and a Transformer-based seq2seq model. We present the results obtained with two datasets in English and in French:~a crowd-sourced public intent classification dataset and our own corporate dialog system dataset. We show that our proposed approach increased the generalization capabilities of the intent classification model on both datasets, reducing the effort required to initialize a new dialog system and helping to deploy this technology at scale within an organization.
An Iterative Contextualization Algorithm with Second-Order Attention
Mar 03, 2021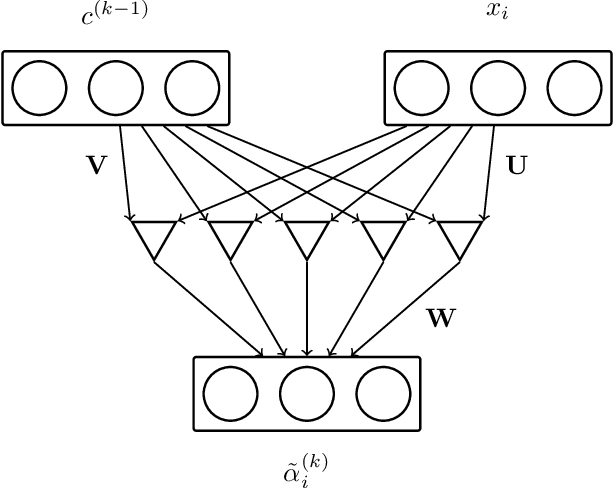
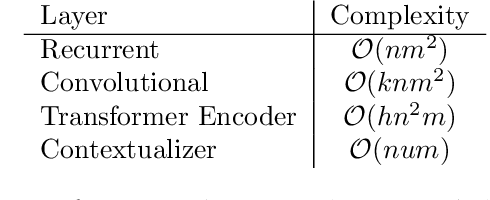

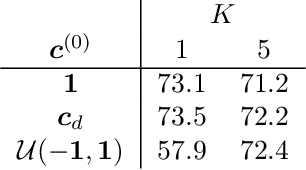
Combining the representations of the words that make up a sentence into a cohesive whole is difficult, since it needs to account for the order of words, and to establish how the words present relate to each other. The solution we propose consists in iteratively adjusting the context. Our algorithm starts with a presumably erroneous value of the context, and adjusts this value with respect to the tokens at hand. In order to achieve this, representations of words are built combining their symbolic embedding with a positional encoding into single vectors. The algorithm then iteratively weighs and aggregates these vectors using our novel second-order attention mechanism. Our models report strong results in several well-known text classification tasks.
Inter and Intra Document Attention for Depression Risk Assessment
Jun 30, 2019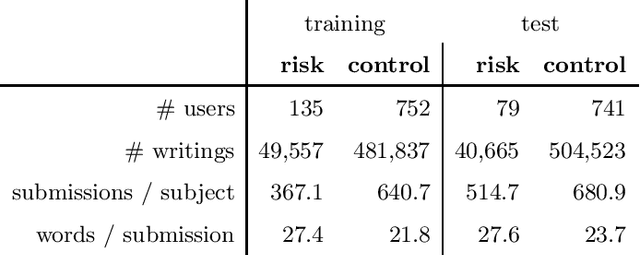
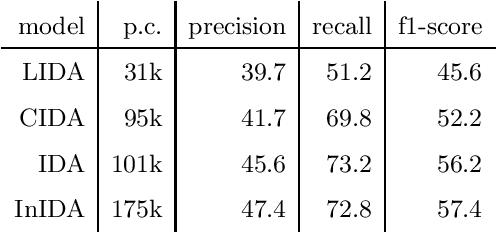
We take interest in the early assessment of risk for depression in social media users. We focus on the eRisk 2018 dataset, which represents users as a sequence of their written online contributions. We implement four RNN-based systems to classify the users. We explore several aggregations methods to combine predictions on individual posts. Our best model reads through all writings of a user in parallel but uses an attention mechanism to prioritize the most important ones at each timestep.
Multiplicative Models for Recurrent Language Modeling
Jun 30, 2019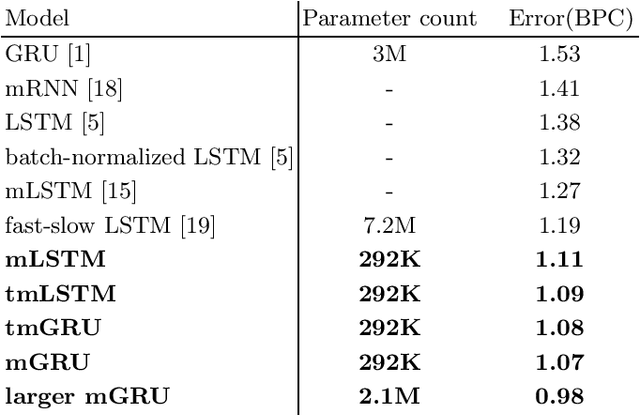
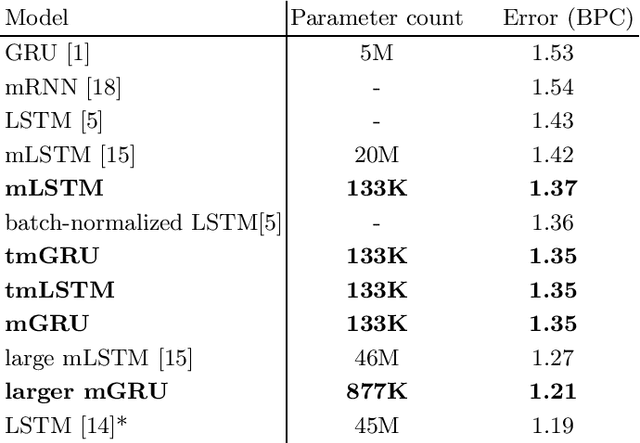
Recently, there has been interest in multiplicative recurrent neural networks for language modeling. Indeed, simple Recurrent Neural Networks (RNNs) encounter difficulties recovering from past mistakes when generating sequences due to high correlation between hidden states. These challenges can be mitigated by integrating second-order terms in the hidden-state update. One such model, multiplicative Long Short-Term Memory (mLSTM) is particularly interesting in its original formulation because of the sharing of its second-order term, referred to as the intermediate state. We explore these architectural improvements by introducing new models and testing them on character-level language modeling tasks. This allows us to establish the relevance of shared parametrization in recurrent language modeling.
Independently Controllable Factors
Aug 25, 2017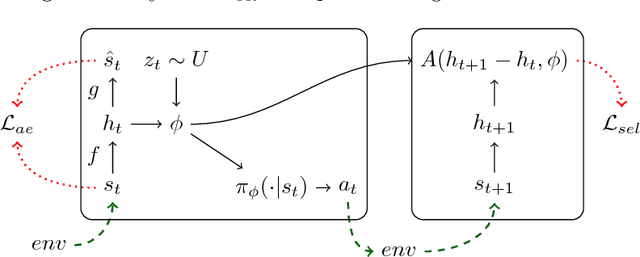
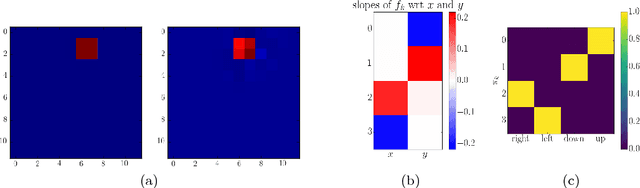
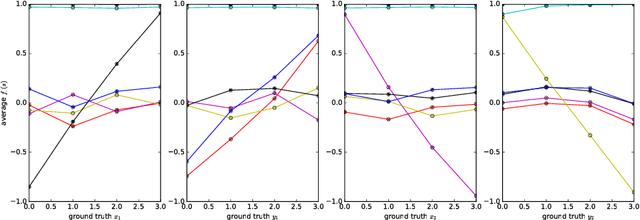
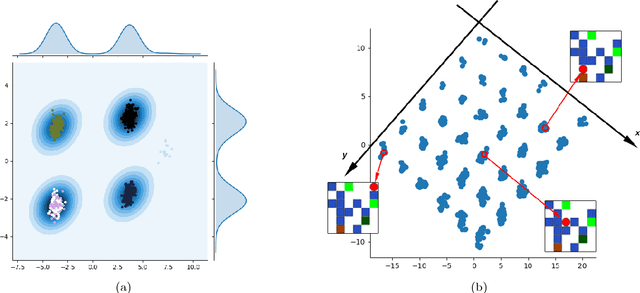
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.