 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnited we stand, Divided we fall: Handling Weak Complementary Relationships for Audio-Visual Emotion Recognition in Valence-Arousal Space
Mar 21, 2025Audio and visual modalities are two predominant contact-free channels in videos, which are often expected to carry a complementary relationship with each other. However, they may not always complement each other, resulting in poor audio-visual feature representations. In this paper, we introduce Gated Recursive Joint Cross Attention (GRJCA) using a gating mechanism that can adaptively choose the most relevant features to effectively capture the synergic relationships across audio and visual modalities. Specifically, we improve the performance of Recursive Joint Cross-Attention (RJCA) by introducing a gating mechanism to control the flow of information between the input features and the attended features of multiple iterations depending on the strength of their complementary relationship. For instance, if the modalities exhibit strong complementary relationships, the gating mechanism emphasizes cross-attended features, otherwise non-attended features. To further improve the performance of the system, we also explored a hierarchical gating approach by introducing a gating mechanism at every iteration, followed by high-level gating across the gated outputs of each iteration. The proposed approach improves the performance of RJCA model by adding more flexibility to deal with weak complementary relationships across audio and visual modalities. Extensive experiments are conducted on the challenging Affwild2 dataset to demonstrate the robustness of the proposed approach. By effectively handling the weak complementary relationships across the audio and visual modalities, the proposed model achieves a Concordance Correlation Coefficient (CCC) of 0.561 (0.623) and 0.620 (0.660) for valence and arousal respectively on the test set (validation set).
Quick Starting Dialog Systems with Paraphrase Generation
Apr 06, 2022

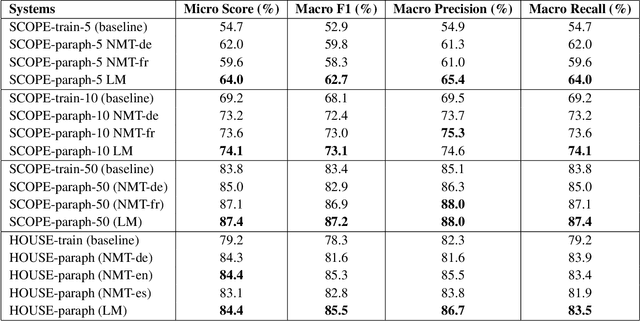
Acquiring training data to improve the robustness of dialog systems can be a painstakingly long process. In this work, we propose a method to reduce the cost and effort of creating new conversational agents by artificially generating more data from existing examples, using paraphrase generation. Our proposed approach can kick-start a dialog system with little human effort, and brings its performance to a level satisfactory enough for allowing actual interactions with real end-users. We experimented with two neural paraphrasing approaches, namely Neural Machine Translation and a Transformer-based seq2seq model. We present the results obtained with two datasets in English and in French:~a crowd-sourced public intent classification dataset and our own corporate dialog system dataset. We show that our proposed approach increased the generalization capabilities of the intent classification model on both datasets, reducing the effort required to initialize a new dialog system and helping to deploy this technology at scale within an organization.
Multi-stage Clarification in Conversational AI: The case of Question-Answering Dialogue Systems
Oct 28, 2021
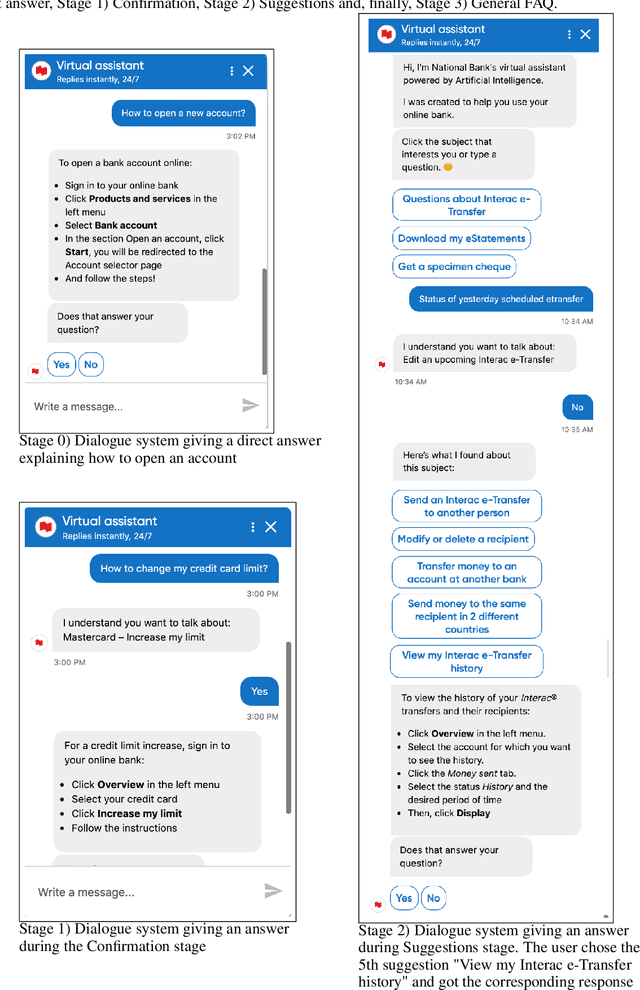
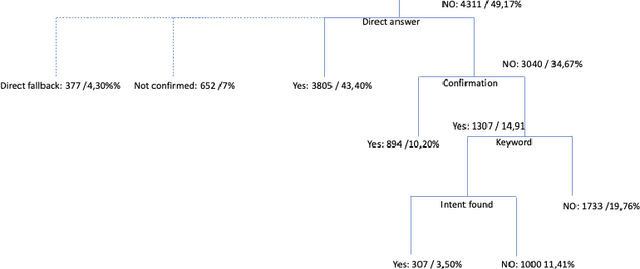

Clarification resolution plays an important role in various information retrieval tasks such as interactive question answering and conversational search. In such context, the user often formulates their information needs as short and ambiguous queries, some popular search interfaces then prompt the user to confirm her intent (e.g. "Did you mean ... ?") or to rephrase if needed. When it comes to dialogue systems, having fluid user-bot exchanges is key to good user experience. In the absence of such clarification mechanism, one of the following responses is given to the user: 1) A direct answer, which can potentially be non-relevant if the intent was not clear, 2) a generic fallback message informing the user that the retrieval tool is incapable of handling the query. Both scenarios might raise frustration and degrade the user experience. To this end, we propose a multi-stage clarification mechanism for prompting clarification and query selection in the context of a question answering dialogue system. We show that our proposed mechanism improves the overall user experience and outperforms competitive baselines with two datasets, namely the public in-scope out-of-scope dataset and a commercial dataset based on real user logs.
A comparison of Deep Learning performances with others machine learning algorithms on credit scoring unbalanced data
Jul 25, 2019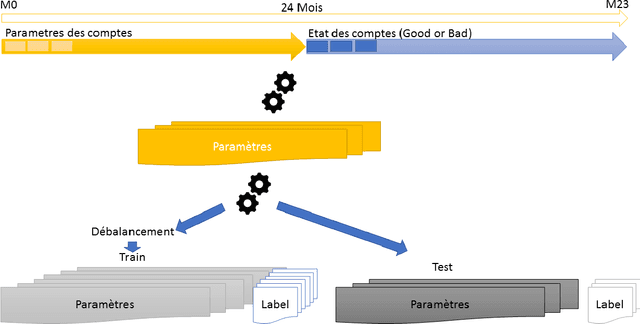
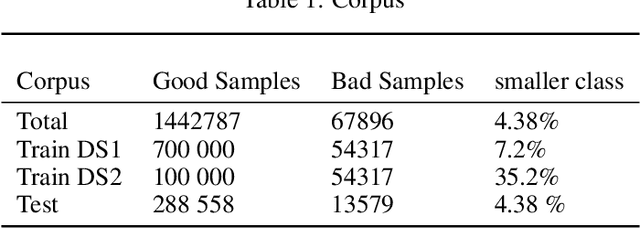
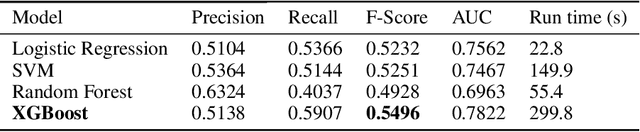
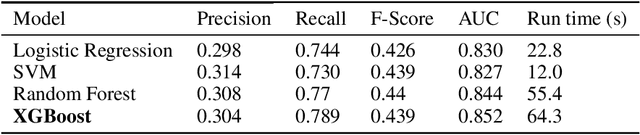
Training models on highly unbalanced data is admitted to be a challenging task for machine learning algorithms. Current studies on deep learning mainly focus on data sets with balanced class labels, or unbalanced data but with massive amount of samples available, like in speech recognition. However, the capacities of deep learning on imbalanced data with little samples is not deeply investigated in literature, while it is a very common application context, in numerous industries. To contribute to fill this gap, this paper compares the performances of several popular machine learning algorithms previously applied with success to unbalanced data set with deep learning algorithms. We conduct those experiments on an highly unbalanced data set, used for credit scoring. We evaluate various configuration including neural network optimisation techniques and try to determine their capacities when they operate with imbalanced corpora.