 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2NIA: Privacy-Preserving Non-Iterative Auditing
Apr 01, 2025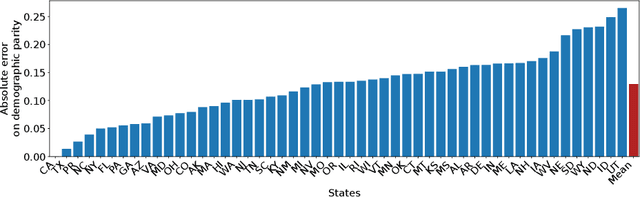
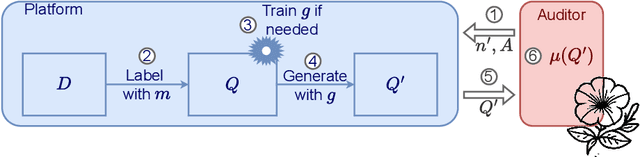
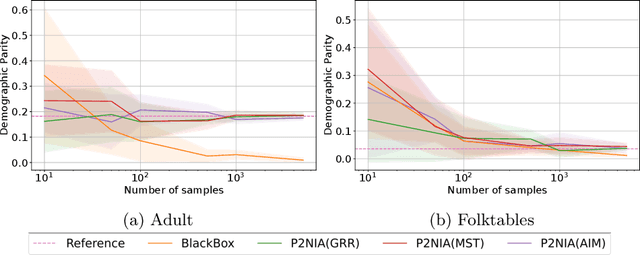
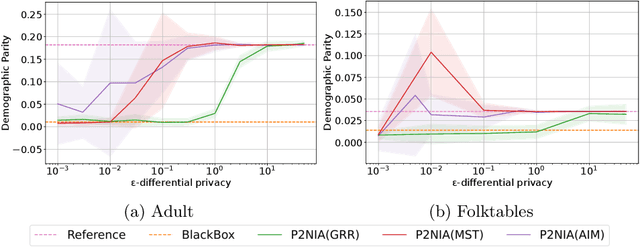
The emergence of AI legislation has increased the need to assess the ethical compliance of high-risk AI systems. Traditional auditing methods rely on platforms' application programming interfaces (APIs), where responses to queries are examined through the lens of fairness requirements. However, such approaches put a significant burden on platforms, as they are forced to maintain APIs while ensuring privacy, facing the possibility of data leaks. This lack of proper collaboration between the two parties, in turn, causes a significant challenge to the auditor, who is subject to estimation bias as they are unaware of the data distribution of the platform. To address these two issues, we present P2NIA, a novel auditing scheme that proposes a mutually beneficial collaboration for both the auditor and the platform. Extensive experiments demonstrate P2NIA's effectiveness in addressing both issues. In summary, our work introduces a privacy-preserving and non-iterative audit scheme that enhances fairness assessments using synthetic or local data, avoiding the challenges associated with traditional API-based audits.
WaKA: Data Attribution using K-Nearest Neighbors and Membership Privacy Principles
Nov 02, 2024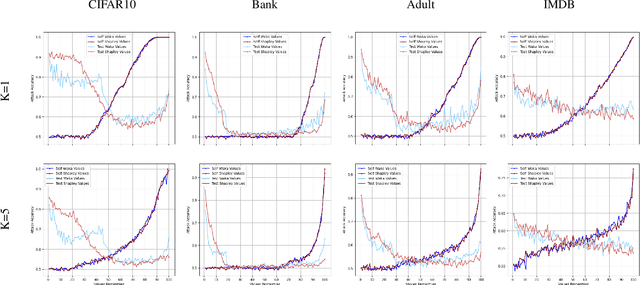
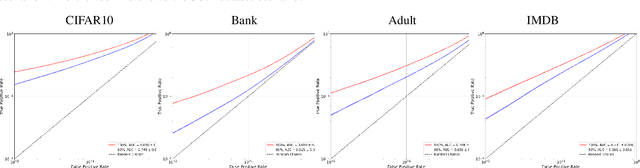
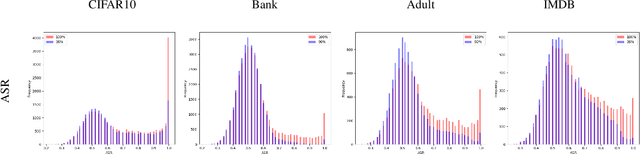
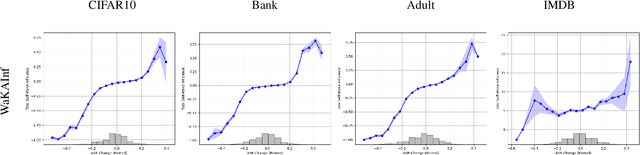
In this paper, we introduce WaKA (Wasserstein K-nearest neighbors Attribution), a novel attribution method that leverages principles from the LiRA (Likelihood Ratio Attack) framework and applies them to \( k \)-nearest neighbors classifiers (\( k \)-NN). WaKA efficiently measures the contribution of individual data points to the model's loss distribution, analyzing every possible \( k \)-NN that can be constructed using the training set, without requiring sampling or shadow model training. WaKA can be used \emph{a posteriori} as a membership inference attack (MIA) to assess privacy risks, and \emph{a priori} for data minimization and privacy influence measurement. Thus, WaKA can be seen as bridging the gap between data attribution and membership inference attack (MIA) literature by distinguishing between the value of a data point and its privacy risk. For instance, we show that self-attribution values are more strongly correlated with the attack success rate than the contribution of a point to model generalization. WaKA's different usages were also evaluated across diverse real-world datasets, demonstrating performance very close to LiRA when used as an MIA on \( k \)-NN classifiers, but with greater computational efficiency.
PANORAMIA: Privacy Auditing of Machine Learning Models without Retraining
Feb 12, 2024



We introduce a privacy auditing scheme for ML models that relies on membership inference attacks using generated data as "non-members". This scheme, which we call PANORAMIA, quantifies the privacy leakage for large-scale ML models without control of the training process or model re-training and only requires access to a subset of the training data. To demonstrate its applicability, we evaluate our auditing scheme across multiple ML domains, ranging from image and tabular data classification to large-scale language models.
Membership Inference Attack for Beluga Whales Discrimination
Feb 28, 2023To efficiently monitor the growth and evolution of a particular wildlife population, one of the main fundamental challenges to address in animal ecology is the re-identification of individuals that have been previously encountered but also the discrimination between known and unknown individuals (the so-called "open-set problem"), which is the first step to realize before re-identification. In particular, in this work, we are interested in the discrimination within digital photos of beluga whales, which are known to be among the most challenging marine species to discriminate due to their lack of distinctive features. To tackle this problem, we propose a novel approach based on the use of Membership Inference Attacks (MIAs), which are normally used to assess the privacy risks associated with releasing a particular machine learning model. More precisely, we demonstrate that the problem of discriminating between known and unknown individuals can be solved efficiently using state-of-the-art approaches for MIAs. Extensive experiments on three benchmark datasets related to whales, two different neural network architectures, and three MIA clearly demonstrate the performance of the approach. In addition, we have also designed a novel MIA strategy that we coined as ensemble MIA, which combines the outputs of different MIAs to increase the attack accuracy while diminishing the false positive rate. Overall, one of our main objectives is also to show that the research on privacy attacks can also be leveraged "for good" by helping to address practical challenges encountered in animal ecology.
Generating synthetic transactional profiles
Oct 28, 2021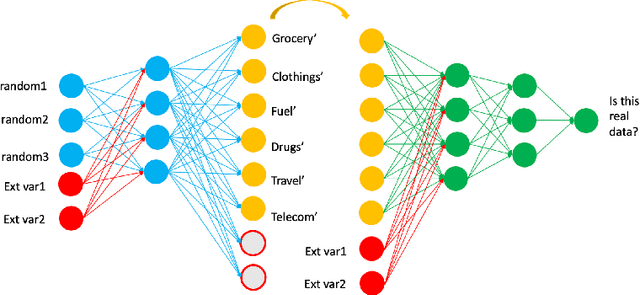



Financial institutions use clients' payment transactions in numerous banking applications. Transactions are very personal and rich in behavioural patterns, often unique to individuals, which make them equivalent to personally identifiable information in some cases. In this paper, we generate synthetic transactional profiles using machine learning techniques with the goal to preserve both data utility and privacy. A challenge we faced was to deal with sparse vectors due to the few spending categories a client uses compared to all the ones available. We measured data utility by calculating common insights used by the banking industry on both the original and the synthetic data-set. Our approach shows that neural network models can generate valuable synthetic data in such context. Finally, we tried privacy-preserving techniques and observed its effect on models' performances.
Multi-stage Clarification in Conversational AI: The case of Question-Answering Dialogue Systems
Oct 28, 2021
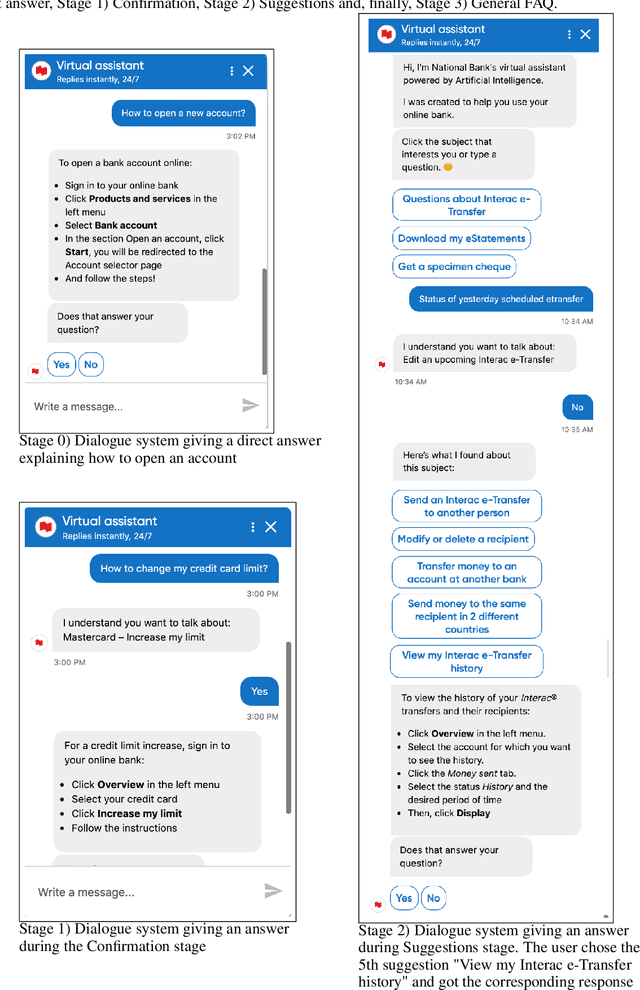
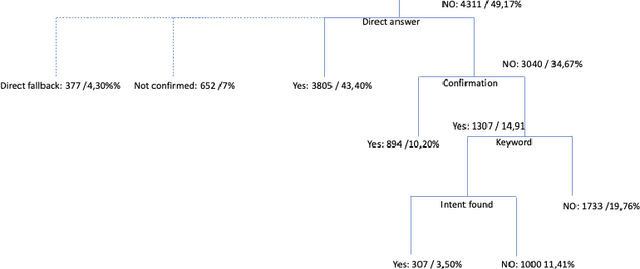

Clarification resolution plays an important role in various information retrieval tasks such as interactive question answering and conversational search. In such context, the user often formulates their information needs as short and ambiguous queries, some popular search interfaces then prompt the user to confirm her intent (e.g. "Did you mean ... ?") or to rephrase if needed. When it comes to dialogue systems, having fluid user-bot exchanges is key to good user experience. In the absence of such clarification mechanism, one of the following responses is given to the user: 1) A direct answer, which can potentially be non-relevant if the intent was not clear, 2) a generic fallback message informing the user that the retrieval tool is incapable of handling the query. Both scenarios might raise frustration and degrade the user experience. To this end, we propose a multi-stage clarification mechanism for prompting clarification and query selection in the context of a question answering dialogue system. We show that our proposed mechanism improves the overall user experience and outperforms competitive baselines with two datasets, namely the public in-scope out-of-scope dataset and a commercial dataset based on real user logs.