 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate and Stable Test-Time Adaptation with Differential Privacy
Jun 01, 2026Test-time adaptation (TTA) can reduce error on new and different data by updating the model on these inputs during inference. However, these updates raise the issue of privacy w.r.t. the testing data, because the model parameters now depend on all past inputs. To control this privacy risk, we cast multiple popular TTA methods (Tent, EATA, SAR, DeYO, and COME) into differential privacy (DP) forms that apply per-sample gradient clipping and Gaussian noise for all updates. On ImageNet-C, our DP-TTA methods provide adequate privacy at small cost to accuracy, and in the low-privacy regime the clipping mechanism of DP can even improve the accuracy and stability of adaptation in the continual setting. These improvements to privacy and accuracy come at only modest computational overhead. These first results on private TTA raise awareness of the issue, inform the development of more private test-time updates, and identify per-sample clipping as an effective technique for improving the accuracy and stability of adaptation.
PANORAMIA: Privacy Auditing of Machine Learning Models without Retraining
Feb 12, 2024



We introduce a privacy auditing scheme for ML models that relies on membership inference attacks using generated data as "non-members". This scheme, which we call PANORAMIA, quantifies the privacy leakage for large-scale ML models without control of the training process or model re-training and only requires access to a subset of the training data. To demonstrate its applicability, we evaluate our auditing scheme across multiple ML domains, ranging from image and tabular data classification to large-scale language models.
DP-AdamBC: Your DP-Adam Is Actually DP-SGD
Dec 21, 2023The Adam optimizer is a popular choice in contemporary deep learning, due to its strong empirical performance. However we observe that in privacy sensitive scenarios, the traditional use of Differential Privacy (DP) with the Adam optimizer leads to sub-optimal performance on several tasks. We find that this performance degradation is due to a DP bias in Adam's second moment estimator, introduced by the addition of independent noise in the gradient computation to enforce DP guarantees. This DP bias leads to a different scaling for low variance parameter updates, that is inconsistent with the behavior of non-private Adam. We propose DP-AdamBC, an optimization algorithm which removes the bias in the second moment estimation and retrieves the expected behaviour of Adam. Empirically, DP-AdamBC significantly improves the optimization performance of DP-Adam by up to 3.5% in final accuracy in image, text, and graph node classification tasks.
DP-Adam: Correcting DP Bias in Adam's Second Moment Estimation
Apr 21, 2023



We observe that the traditional use of DP with the Adam optimizer introduces a bias in the second moment estimation, due to the addition of independent noise in the gradient computation. This bias leads to a different scaling for low variance parameter updates, that is inconsistent with the behavior of non-private Adam, and Adam's sign descent interpretation. Empirically, correcting the bias introduced by DP noise significantly improves the optimization performance of DP-Adam.
Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation
Jul 29, 2022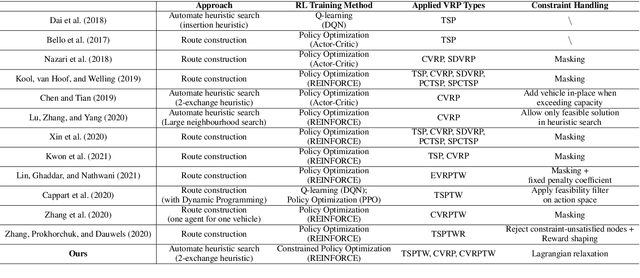

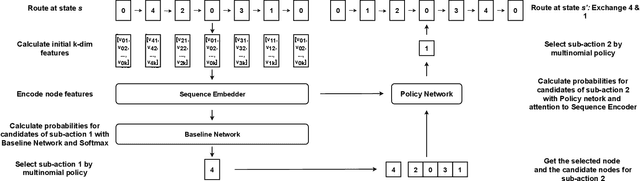
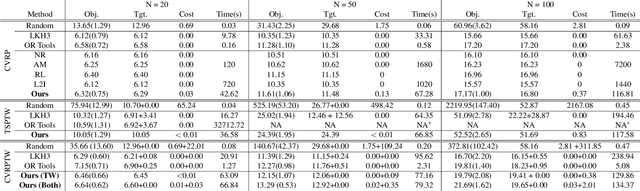
Vehicle Routing Problems (VRPs) in real-world applications often come with various constraints, therefore bring additional computational challenges to exact solution methods or heuristic search approaches. The recent idea to learn heuristic move patterns from sample data has become increasingly promising to reduce solution developing costs. However, using learning-based approaches to address more types of constrained VRP remains a challenge. The difficulty lies in controlling for constraint violations while searching for optimal solutions. To overcome this challenge, we propose a Reinforcement Learning based method to solve soft-constrained VRPs by incorporating the Lagrangian relaxation technique and using constrained policy optimization. We apply the method on three common types of VRPs, the Travelling Salesman Problem with Time Windows (TSPTW), the Capacitated VRP (CVRP) and the Capacitated VRP with Time Windows (CVRPTW), to show the generalizability of the proposed method. After comparing to existing RL-based methods and open-source heuristic solvers, we demonstrate its competitive performance in finding solutions with a good balance in travel distance, constraint violations and inference speed.