 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Federated Learning via Byzantine Filtering over Encrypted Updates
Feb 05, 2026Federated Learning (FL) aims to train a collaborative model while preserving data privacy. However, the distributed nature of this approach still raises privacy and security issues, such as the exposure of sensitive data due to inference attacks and the influence of Byzantine behaviors on the trained model. In particular, achieving both secure aggregation and Byzantine resilience remains challenging, as existing solutions often address these aspects independently. In this work, we propose to address these challenges through a novel approach that combines homomorphic encryption for privacy-preserving aggregation with property-inference-inspired meta-classifiers for Byzantine filtering. First, following the property-inference attacks blueprint, we train a set of filtering meta-classifiers on labeled shadow updates, reproducing a diverse ensemble of Byzantine misbehaviors in FL, including backdoor, gradient-inversion, label-flipping and shuffling attacks. The outputs of these meta-classifiers are then used to cancel the Byzantine encrypted updates by reweighting. Second, we propose an automated method for selecting the optimal kernel and the dimensionality hyperparameters with respect to homomorphic inference, aggregation constraints and efficiency over the CKKS cryptosystem. Finally, we demonstrate through extensive experiments the effectiveness of our approach against Byzantine participants on the FEMNIST, CIFAR10, GTSRB, and acsincome benchmarks. More precisely, our SVM filtering achieves accuracies between $90$% and $94$% for identifying Byzantine updates at the cost of marginal losses in model utility and encrypted inference runtimes ranging from $6$ to $24$ seconds and from $9$ to $26$ seconds for an overall aggregation.
On the Usage of Gaussian Process for Efficient Data Valuation
Jun 04, 2025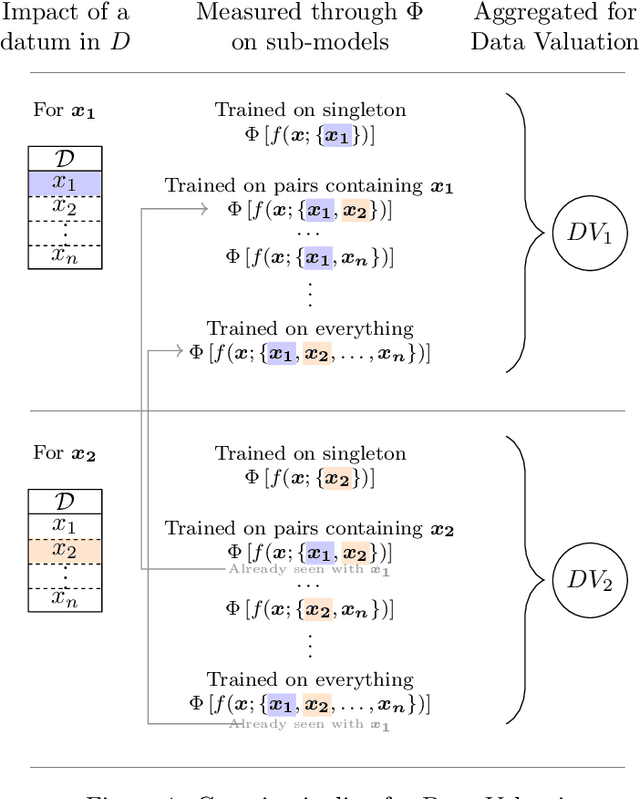
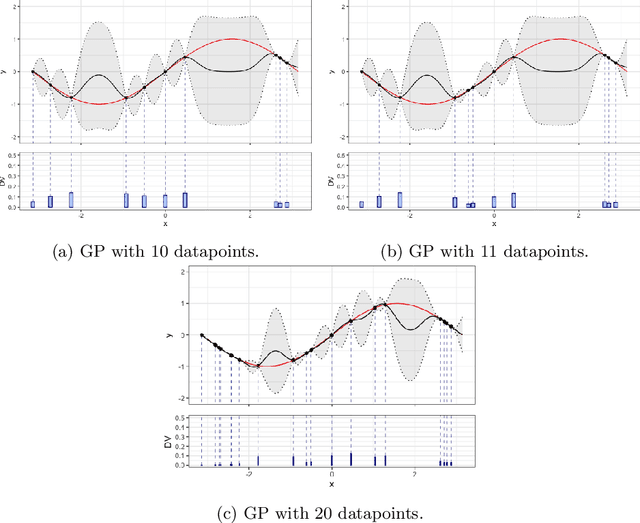
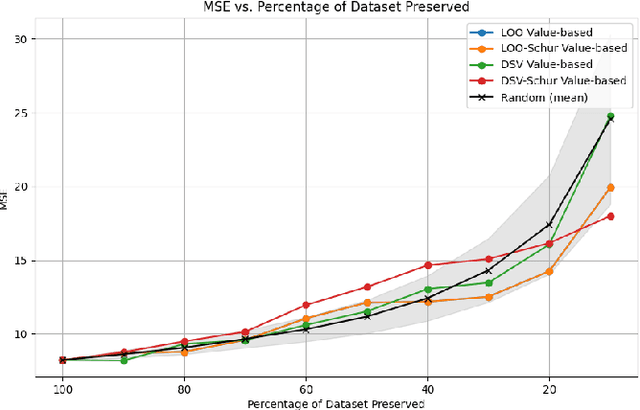
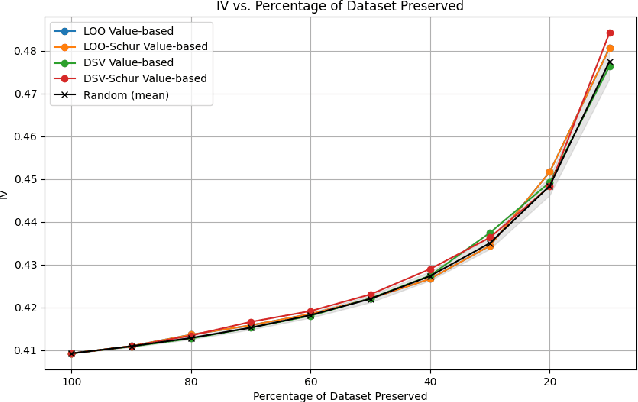
In machine learning, knowing the impact of a given datum on model training is a fundamental task referred to as Data Valuation. Building on previous works from the literature, we have designed a novel canonical decomposition allowing practitioners to analyze any data valuation method as the combination of two parts: a utility function that captures characteristics from a given model and an aggregation procedure that merges such information. We also propose to use Gaussian Processes as a means to easily access the utility function on ``sub-models'', which are models trained on a subset of the training set. The strength of our approach stems from both its theoretical grounding in Bayesian theory, and its practical reach, by enabling fast estimation of valuations thanks to efficient update formulae.
P2NIA: Privacy-Preserving Non-Iterative Auditing
Apr 01, 2025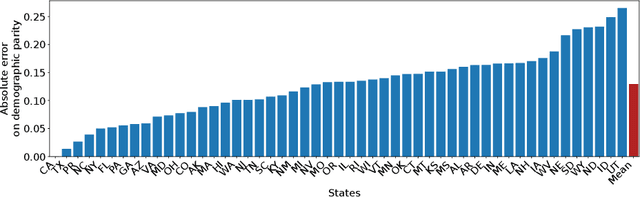
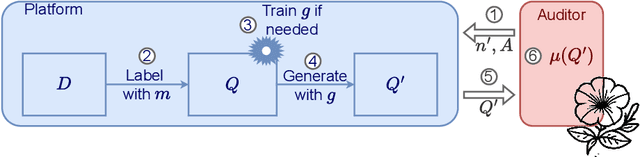
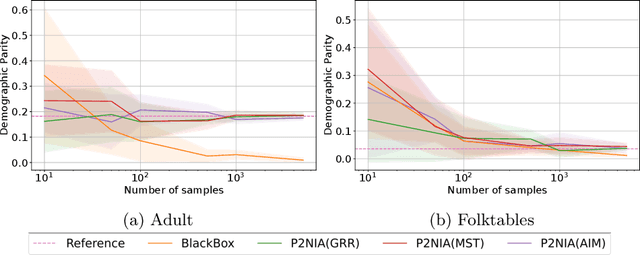
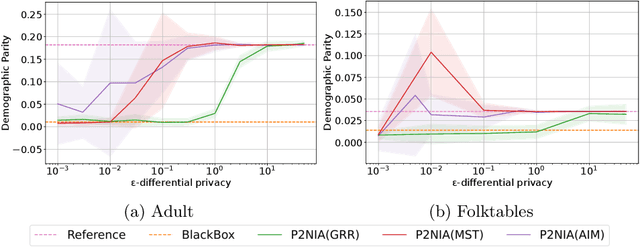
The emergence of AI legislation has increased the need to assess the ethical compliance of high-risk AI systems. Traditional auditing methods rely on platforms' application programming interfaces (APIs), where responses to queries are examined through the lens of fairness requirements. However, such approaches put a significant burden on platforms, as they are forced to maintain APIs while ensuring privacy, facing the possibility of data leaks. This lack of proper collaboration between the two parties, in turn, causes a significant challenge to the auditor, who is subject to estimation bias as they are unaware of the data distribution of the platform. To address these two issues, we present P2NIA, a novel auditing scheme that proposes a mutually beneficial collaboration for both the auditor and the platform. Extensive experiments demonstrate P2NIA's effectiveness in addressing both issues. In summary, our work introduces a privacy-preserving and non-iterative audit scheme that enhances fairness assessments using synthetic or local data, avoiding the challenges associated with traditional API-based audits.
Training Set Reconstruction from Differentially Private Forests: How Effective is DP?
Feb 07, 2025



Recent research has shown that machine learning models are vulnerable to privacy attacks targeting their training data. Differential privacy (DP) has become a widely adopted countermeasure, as it offers rigorous privacy protections. In this paper, we introduce a reconstruction attack targeting state-of-the-art $\varepsilon$-DP random forests. By leveraging a constraint programming model that incorporates knowledge of the forest's structure and DP mechanism characteristics, our approach formally reconstructs the most likely dataset that could have produced a given forest. Through extensive computational experiments, we examine the interplay between model utility, privacy guarantees, and reconstruction accuracy across various configurations. Our results reveal that random forests trained with meaningful DP guarantees can still leak substantial portions of their training data. Specifically, while DP reduces the success of reconstruction attacks, the only forests fully robust to our attack exhibit predictive performance no better than a constant classifier. Building on these insights, we provide practical recommendations for the construction of DP random forests that are more resilient to reconstruction attacks and maintain non-trivial predictive performance.
WaKA: Data Attribution using K-Nearest Neighbors and Membership Privacy Principles
Nov 02, 2024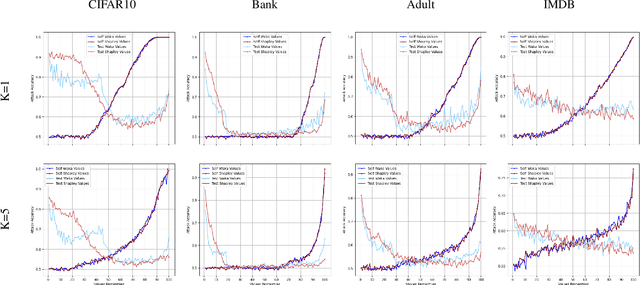
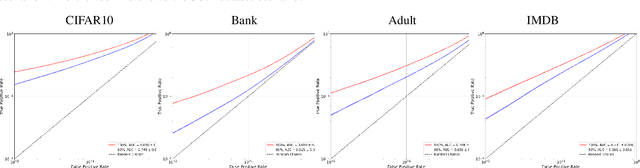
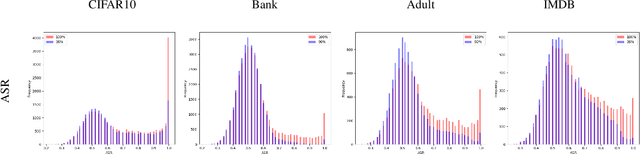
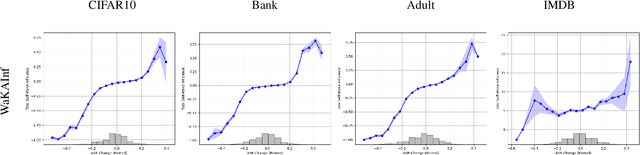
In this paper, we introduce WaKA (Wasserstein K-nearest neighbors Attribution), a novel attribution method that leverages principles from the LiRA (Likelihood Ratio Attack) framework and applies them to \( k \)-nearest neighbors classifiers (\( k \)-NN). WaKA efficiently measures the contribution of individual data points to the model's loss distribution, analyzing every possible \( k \)-NN that can be constructed using the training set, without requiring sampling or shadow model training. WaKA can be used \emph{a posteriori} as a membership inference attack (MIA) to assess privacy risks, and \emph{a priori} for data minimization and privacy influence measurement. Thus, WaKA can be seen as bridging the gap between data attribution and membership inference attack (MIA) literature by distinguishing between the value of a data point and its privacy risk. For instance, we show that self-attribution values are more strongly correlated with the attack success rate than the contribution of a point to model generalization. WaKA's different usages were also evaluated across diverse real-world datasets, demonstrating performance very close to LiRA when used as an MIA on \( k \)-NN classifiers, but with greater computational efficiency.
Smooth Sensitivity for Learning Differentially-Private yet Accurate Rule Lists
Mar 18, 2024


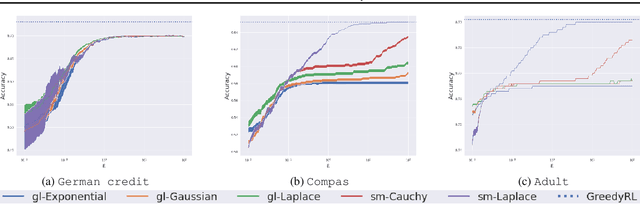
Differentially-private (DP) mechanisms can be embedded into the design of a machine learningalgorithm to protect the resulting model against privacy leakage, although this often comes with asignificant loss of accuracy. In this paper, we aim at improving this trade-off for rule lists modelsby establishing the smooth sensitivity of the Gini impurity and leveraging it to propose a DP greedyrule list algorithm. In particular, our theoretical analysis and experimental results demonstrate thatthe DP rule lists models integrating smooth sensitivity have higher accuracy that those using otherDP frameworks based on global sensitivity.
PANORAMIA: Privacy Auditing of Machine Learning Models without Retraining
Feb 12, 2024



We introduce a privacy auditing scheme for ML models that relies on membership inference attacks using generated data as "non-members". This scheme, which we call PANORAMIA, quantifies the privacy leakage for large-scale ML models without control of the training process or model re-training and only requires access to a subset of the training data. To demonstrate its applicability, we evaluate our auditing scheme across multiple ML domains, ranging from image and tabular data classification to large-scale language models.
SoK: Taming the Triangle -- On the Interplays between Fairness, Interpretability and Privacy in Machine Learning
Dec 22, 2023

Machine learning techniques are increasingly used for high-stakes decision-making, such as college admissions, loan attribution or recidivism prediction. Thus, it is crucial to ensure that the models learnt can be audited or understood by human users, do not create or reproduce discrimination or bias, and do not leak sensitive information regarding their training data. Indeed, interpretability, fairness and privacy are key requirements for the development of responsible machine learning, and all three have been studied extensively during the last decade. However, they were mainly considered in isolation, while in practice they interplay with each other, either positively or negatively. In this Systematization of Knowledge (SoK) paper, we survey the literature on the interactions between these three desiderata. More precisely, for each pairwise interaction, we summarize the identified synergies and tensions. These findings highlight several fundamental theoretical and empirical conflicts, while also demonstrating that jointly considering these different requirements is challenging when one aims at preserving a high level of utility. To solve this issue, we also discuss possible conciliation mechanisms, showing that a careful design can enable to successfully handle these different concerns in practice.
Crypto'Graph: Leveraging Privacy-Preserving Distributed Link Prediction for Robust Graph Learning
Sep 19, 2023Graphs are a widely used data structure for collecting and analyzing relational data. However, when the graph structure is distributed across several parties, its analysis is particularly challenging. In particular, due to the sensitivity of the data each party might want to keep their partial knowledge of the graph private, while still willing to collaborate with the other parties for tasks of mutual benefit, such as data curation or the removal of poisoned data. To address this challenge, we propose Crypto'Graph, an efficient protocol for privacy-preserving link prediction on distributed graphs. More precisely, it allows parties partially sharing a graph with distributed links to infer the likelihood of formation of new links in the future. Through the use of cryptographic primitives, Crypto'Graph is able to compute the likelihood of these new links on the joint network without revealing the structure of the private individual graph of each party, even though they know the number of nodes they have, since they share the same graph but not the same links. Crypto'Graph improves on previous works by enabling the computation of a certain number of similarity metrics without any additional cost. The use of Crypto'Graph is illustrated for defense against graph poisoning attacks, in which it is possible to identify potential adversarial links without compromising the privacy of the graphs of individual parties. The effectiveness of Crypto'Graph in mitigating graph poisoning attacks and achieving high prediction accuracy on a graph neural network node classification task is demonstrated through extensive experimentation on a real-world dataset.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023
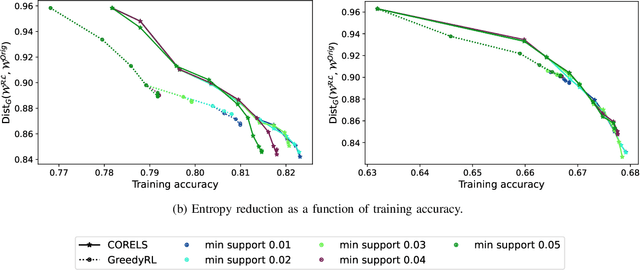
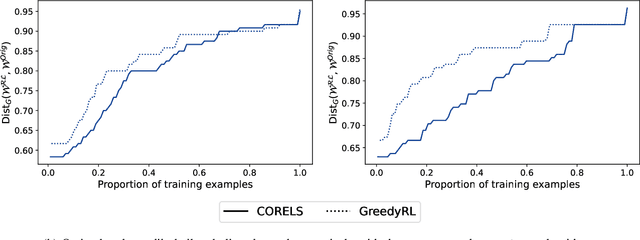
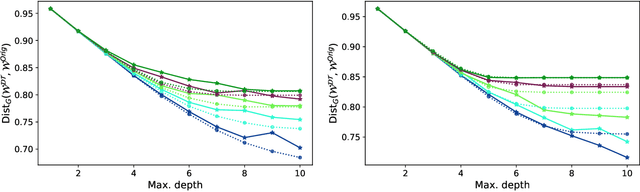
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.