 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Prune-And-Compress Ensemble Models
May 07, 2026Ensemble models achieve state-of-the-art performance on prediction tasks, but usually require aggregating a large number of weak learners. This can hinder deployment, interpretability, and downstream tasks such as robustness verification. Remedies to this issue fall into two main camps: pruning, which discards redundant learners, and compression, which generates new ones from scratch. We introduce PACE, a framework that interleaves these paradigms in a two-phase strategy. First, new learners are actively generated via a theoretically grounded procedure to enhance the diversity of the initial ensemble. When no more relevant learners can be found, a second phase of pruning is performed on this enriched ensemble. During both operations, PACE allows fine control on the faithfulness to the original ensemble. Experiments show that our method outperforms prior pruning and compression methods while offering principled control of faithfulness guarantees.
Optimal Counterfactual Search in Tree Ensembles: A Study Across Modeling and Solution Paradigms
May 07, 2026Trust in counterfactual explanations depends critically on whether their recommended changes are truly minimal: suboptimal explanations may vastly overshoot the actual changes needed to alter a decision, and heuristic errors can affect individuals unevenly, giving some users relevant recourse while assigning others unnecessarily costly recommendations. Consequently, we study the problem of computing optimal counterfactual explanations for tree ensembles under plausibility and actionability constraints. This is a combinatorial problem: for a fixed model, counterfactual search boils down to selecting consistent branching decisions and threshold-defined regions under a distance objective. We exploit this structure through CPCF, a constraint programming (CP) formulation in which numerical features are encoded as interval domains induced by split thresholds, while discrete features retain native finite-domain representations. This yields a compact finite-domain formulation that supports multiple distance objectives without continuous split-boundary search. We then place CPCF in a broader comparison across mathematical programming paradigms: we extend a maximum Boolean satisfiability (MaxSAT) formulation, originally designed for hard-voting random forests, to soft-voting ensembles, and compare against the current state-of-the-art mixed-integer linear programming (MILP) optimal approach. Across ten datasets and three types of tree ensembles, we analyze scalability, anytime performance, and sensitivity to distance metrics. We observe that CP achieves the best overall performance. More importantly, our results identify regimes in which the specific strengths of each paradigm make it best suited: CP is most versatile overall, MaxSAT handles hard-voting ensembles particularly well, and MILP remains competitive in amortized inference settings with a moderate number of split levels.
Counterfactual Maps: What They Are and How to Find Them
Feb 09, 2026Counterfactual explanations are a central tool in interpretable machine learning, yet computing them exactly for complex models remains challenging. For tree ensembles, predictions are piecewise constant over a large collection of axis-aligned hyperrectangles, implying that an optimal counterfactual for a point corresponds to its projection onto the nearest rectangle with an alternative label under a chosen metric. Existing methods largely overlook this geometric structure, relying either on heuristics with no optimality guarantees or on mixed-integer programming formulations that do not scale to interactive use. In this work, we revisit counterfactual generation through the lens of nearest-region search and introduce counterfactual maps, a global representation of recourse for tree ensembles. Leveraging the fact that any tree ensemble can be compressed into an equivalent partition of labeled hyperrectangles, we cast counterfactual search as the problem of identifying the generalized Voronoi cell associated with the nearest rectangle of an alternative label. This leads to an exact, amortized algorithm based on volumetric k-dimensional (KD) trees, which performs branch-and-bound nearest-region queries with explicit optimality certificates and sublinear average query time after a one-time preprocessing phase. Our experimental analyses on several real datasets drawn from high-stakes application domains show that this approach delivers globally optimal counterfactual explanations with millisecond-level latency, achieving query times that are orders of magnitude faster than existing exact, cold-start optimization methods.
Training Set Reconstruction from Differentially Private Forests: How Effective is DP?
Feb 07, 2025



Recent research has shown that machine learning models are vulnerable to privacy attacks targeting their training data. Differential privacy (DP) has become a widely adopted countermeasure, as it offers rigorous privacy protections. In this paper, we introduce a reconstruction attack targeting state-of-the-art $\varepsilon$-DP random forests. By leveraging a constraint programming model that incorporates knowledge of the forest's structure and DP mechanism characteristics, our approach formally reconstructs the most likely dataset that could have produced a given forest. Through extensive computational experiments, we examine the interplay between model utility, privacy guarantees, and reconstruction accuracy across various configurations. Our results reveal that random forests trained with meaningful DP guarantees can still leak substantial portions of their training data. Specifically, while DP reduces the success of reconstruction attacks, the only forests fully robust to our attack exhibit predictive performance no better than a constant classifier. Building on these insights, we provide practical recommendations for the construction of DP random forests that are more resilient to reconstruction attacks and maintain non-trivial predictive performance.
Fairness and Sparsity within Rashomon sets: Enumeration-Free Exploration and Characterization
Feb 07, 2025



We introduce an enumeration-free method based on mathematical programming to precisely characterize various properties such as fairness or sparsity within the set of "good models", known as Rashomon set. This approach is generically applicable to any hypothesis class, provided that a mathematical formulation of the model learning task exists. It offers a structured framework to define the notion of business necessity and evaluate how fairness can be improved or degraded towards a specific protected group, while remaining within the Rashomon set and maintaining any desired sparsity level. We apply our approach to two hypothesis classes: scoring systems and decision diagrams, leveraging recent mathematical programming formulations for training such models. As seen in our experiments, the method comprehensively and certifiably quantifies trade-offs between predictive performance, sparsity, and fairness. We observe that a wide range of fairness values are attainable, ranging from highly favorable to significantly unfavorable for a protected group, while staying within less than 1% of the best possible training accuracy for the hypothesis class. Additionally, we observe that sparsity constraints limit these trade-offs and may disproportionately harm specific subgroups. As we evidenced, thoroughly characterizing the tensions between these key aspects is critical for an informed and accountable selection of models.
From Counterfactuals to Trees: Competitive Analysis of Model Extraction Attacks
Feb 07, 2025The advent of Machine Learning as a Service (MLaaS) has heightened the trade-off between model explainability and security. In particular, explainability techniques, such as counterfactual explanations, inadvertently increase the risk of model extraction attacks, enabling unauthorized replication of proprietary models. In this paper, we formalize and characterize the risks and inherent complexity of model reconstruction, focusing on the "oracle'' queries required for faithfully inferring the underlying prediction function. We present the first formal analysis of model extraction attacks through the lens of competitive analysis, establishing a foundational framework to evaluate their efficiency. Focusing on models based on additive decision trees (e.g., decision trees, gradient boosting, and random forests), we introduce novel reconstruction algorithms that achieve provably perfect fidelity while demonstrating strong anytime performance. Our framework provides theoretical bounds on the query complexity for extracting tree-based model, offering new insights into the security vulnerabilities of their deployment.
DistrictNet: Decision-aware learning for geographical districting
Dec 11, 2024Districting is a complex combinatorial problem that consists in partitioning a geographical area into small districts. In logistics, it is a major strategic decision determining operating costs for several years. Solving districting problems using traditional methods is intractable even for small geographical areas and existing heuristics often provide sub-optimal results. We present a structured learning approach to find high-quality solutions to real-world districting problems in a few minutes. It is based on integrating a combinatorial optimization layer, the capacitated minimum spanning tree problem, into a graph neural network architecture. To train this pipeline in a decision-aware fashion, we show how to construct target solutions embedded in a suitable space and learn from target solutions. Experiments show that our approach outperforms existing methods as it can significantly reduce costs on real-world cities.
Free Lunch in the Forest: Functionally-Identical Pruning of Boosted Tree Ensembles
Aug 28, 2024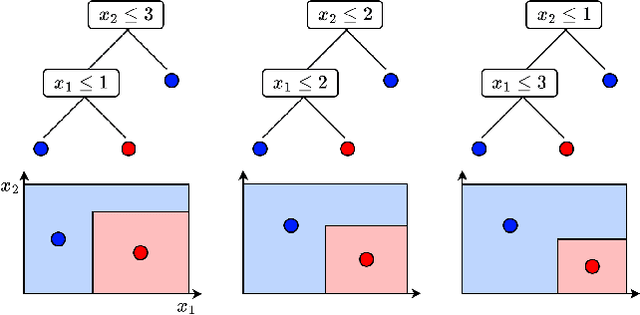
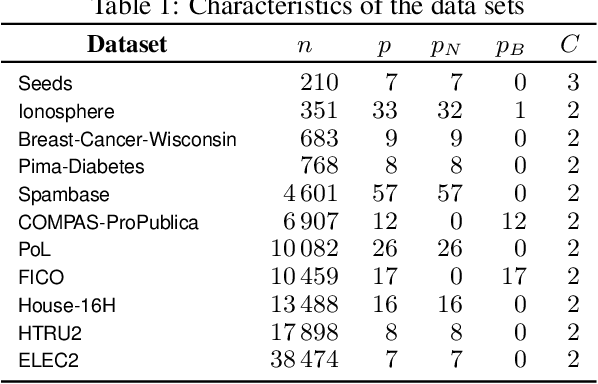
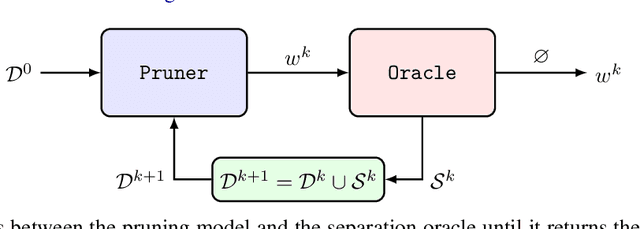
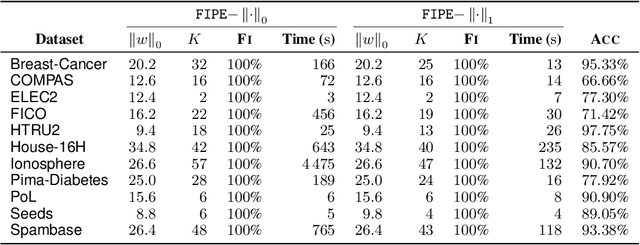
Tree ensembles, including boosting methods, are highly effective and widely used for tabular data. However, large ensembles lack interpretability and require longer inference times. We introduce a method to prune a tree ensemble into a reduced version that is "functionally identical" to the original model. In other words, our method guarantees that the prediction function stays unchanged for any possible input. As a consequence, this pruning algorithm is lossless for any aggregated metric. We formalize the problem of functionally identical pruning on ensembles, introduce an exact optimization model, and provide a fast yet highly effective method to prune large ensembles. Our algorithm iteratively prunes considering a finite set of points, which is incrementally augmented using an adversarial model. In multiple computational experiments, we show that our approach is a "free lunch", significantly reducing the ensemble size without altering the model's behavior. Thus, we can preserve state-of-the-art performance at a fraction of the original model's size.
Dual Policy Reinforcement Learning for Real-time Rebalancing in Bike-sharing Systems
Jun 02, 2024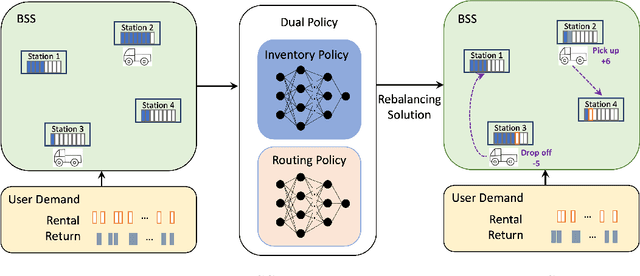


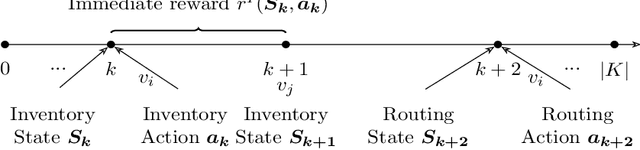
Bike-sharing systems play a crucial role in easing traffic congestion and promoting healthier lifestyles. However, ensuring their reliability and user acceptance requires effective strategies for rebalancing bikes. This study introduces a novel approach to address the real-time rebalancing problem with a fleet of vehicles. It employs a dual policy reinforcement learning algorithm that decouples inventory and routing decisions, enhancing realism and efficiency compared to previous methods where both decisions were made simultaneously. We first formulate the inventory and routing subproblems as a multi-agent Markov Decision Process within a continuous time framework. Subsequently, we propose a DQN-based dual policy framework to jointly estimate the value functions, minimizing the lost demand. To facilitate learning, a comprehensive simulator is applied to operate under a first-arrive-first-serve rule, which enables the computation of immediate rewards across diverse demand scenarios. We conduct extensive experiments on various datasets generated from historical real-world data, affected by both temporal and weather factors. Our proposed algorithm demonstrates significant performance improvements over previous baseline methods. It offers valuable practical insights for operators and further explores the incorporation of reinforcement learning into real-world dynamic programming problems, paving the way for more intelligent and robust urban mobility solutions.
CF-OPT: Counterfactual Explanations for Structured Prediction
May 28, 2024



Optimization layers in deep neural networks have enjoyed a growing popularity in structured learning, improving the state of the art on a variety of applications. Yet, these pipelines lack interpretability since they are made of two opaque layers: a highly non-linear prediction model, such as a deep neural network, and an optimization layer, which is typically a complex black-box solver. Our goal is to improve the transparency of such methods by providing counterfactual explanations. We build upon variational autoencoders a principled way of obtaining counterfactuals: working in the latent space leads to a natural notion of plausibility of explanations. We finally introduce a variant of the classic loss for VAE training that improves their performance in our specific structured context. These provide the foundations of CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. Our numerical results show that both close and plausible explanations can be obtained for problems from the recent literature.