 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistrictNet: Decision-aware learning for geographical districting
Dec 11, 2024Districting is a complex combinatorial problem that consists in partitioning a geographical area into small districts. In logistics, it is a major strategic decision determining operating costs for several years. Solving districting problems using traditional methods is intractable even for small geographical areas and existing heuristics often provide sub-optimal results. We present a structured learning approach to find high-quality solutions to real-world districting problems in a few minutes. It is based on integrating a combinatorial optimization layer, the capacitated minimum spanning tree problem, into a graph neural network architecture. To train this pipeline in a decision-aware fashion, we show how to construct target solutions embedded in a suitable space and learn from target solutions. Experiments show that our approach outperforms existing methods as it can significantly reduce costs on real-world cities.
The Differentiable Feasibility Pump
Nov 05, 2024



Although nearly 20 years have passed since its conception, the feasibility pump algorithm remains a widely used heuristic to find feasible primal solutions to mixed-integer linear problems. Many extensions of the initial algorithm have been proposed. Yet, its core algorithm remains centered around two key steps: solving the linear relaxation of the original problem to obtain a solution that respects the constraints, and rounding it to obtain an integer solution. This paper shows that the traditional feasibility pump and many of its follow-ups can be seen as gradient-descent algorithms with specific parameters. A central aspect of this reinterpretation is observing that the traditional algorithm differentiates the solution of the linear relaxation with respect to its cost. This reinterpretation opens many opportunities for improving the performance of the original algorithm. We study how to modify the gradient-update step as well as extending its loss function. We perform extensive experiments on MIPLIB instances and show that these modifications can substantially reduce the number of iterations needed to find a solution.
Free Lunch in the Forest: Functionally-Identical Pruning of Boosted Tree Ensembles
Aug 28, 2024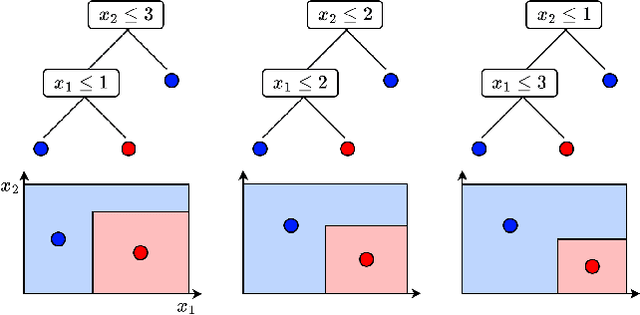
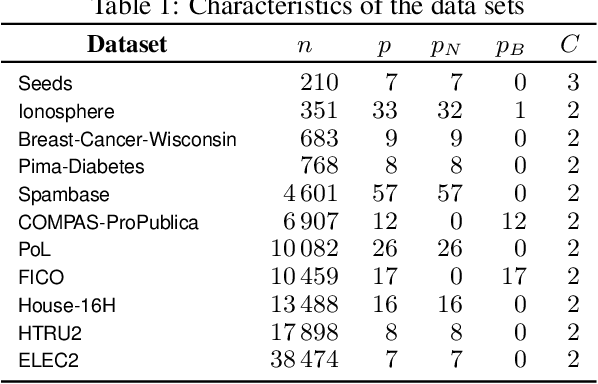
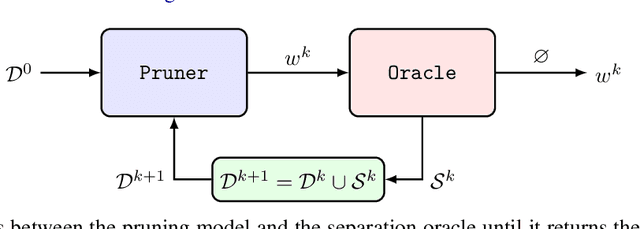
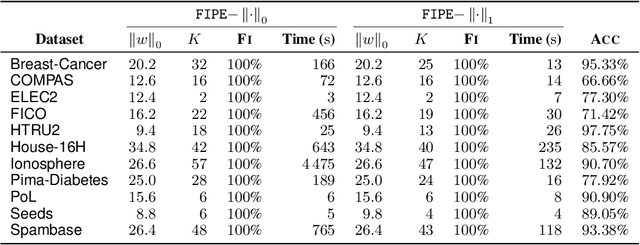
Tree ensembles, including boosting methods, are highly effective and widely used for tabular data. However, large ensembles lack interpretability and require longer inference times. We introduce a method to prune a tree ensemble into a reduced version that is "functionally identical" to the original model. In other words, our method guarantees that the prediction function stays unchanged for any possible input. As a consequence, this pruning algorithm is lossless for any aggregated metric. We formalize the problem of functionally identical pruning on ensembles, introduce an exact optimization model, and provide a fast yet highly effective method to prune large ensembles. Our algorithm iteratively prunes considering a finite set of points, which is incrementally augmented using an adversarial model. In multiple computational experiments, we show that our approach is a "free lunch", significantly reducing the ensemble size without altering the model's behavior. Thus, we can preserve state-of-the-art performance at a fraction of the original model's size.
CF-OPT: Counterfactual Explanations for Structured Prediction
May 28, 2024



Optimization layers in deep neural networks have enjoyed a growing popularity in structured learning, improving the state of the art on a variety of applications. Yet, these pipelines lack interpretability since they are made of two opaque layers: a highly non-linear prediction model, such as a deep neural network, and an optimization layer, which is typically a complex black-box solver. Our goal is to improve the transparency of such methods by providing counterfactual explanations. We build upon variational autoencoders a principled way of obtaining counterfactuals: working in the latent space leads to a natural notion of plausibility of explanations. We finally introduce a variant of the classic loss for VAE training that improves their performance in our specific structured context. These provide the foundations of CF-OPT, a first-order optimization algorithm that can find counterfactual explanations for a broad class of structured learning architectures. Our numerical results show that both close and plausible explanations can be obtained for problems from the recent literature.
A Survey of Contextual Optimization Methods for Decision Making under Uncertainty
Jun 17, 2023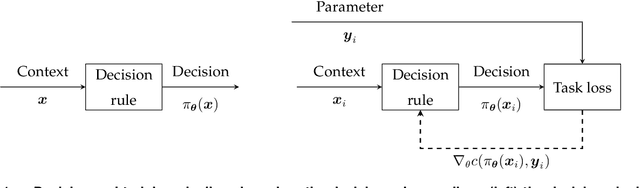



Recently there has been a surge of interest in operations research (OR) and the machine learning (ML) community in combining prediction algorithms and optimization techniques to solve decision-making problems in the face of uncertainty. This gave rise to the field of contextual optimization, under which data-driven procedures are developed to prescribe actions to the decision-maker that make the best use of the most recently updated information. A large variety of models and methods have been presented in both OR and ML literature under a variety of names, including data-driven optimization, prescriptive optimization, predictive stochastic programming, policy optimization, (smart) predict/estimate-then-optimize, decision-focused learning, (task-based) end-to-end learning/forecasting/optimization, etc. Focusing on single and two-stage stochastic programming problems, this review article identifies three main frameworks for learning policies from data and discusses their strengths and limitations. We present the existing models and methods under a uniform notation and terminology and classify them according to the three main frameworks identified. Our objective with this survey is to both strengthen the general understanding of this active field of research and stimulate further theoretical and algorithmic advancements in integrating ML and stochastic programming.
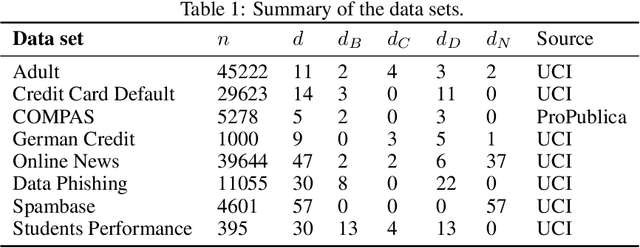
Explainable Data-Driven Optimization: From Context to Decision and Back Again
Jan 24, 2023
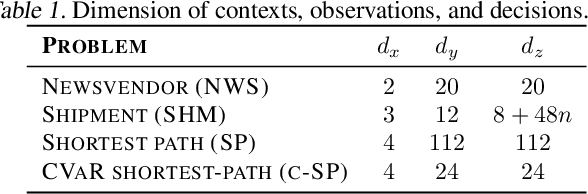


Data-driven optimization uses contextual information and machine learning algorithms to find solutions to decision problems with uncertain parameters. While a vast body of work is dedicated to interpreting machine learning models in the classification setting, explaining decision pipelines involving learning algorithms remains unaddressed. This lack of interpretability can block the adoption of data-driven solutions as practitioners may not understand or trust the recommended decisions. We bridge this gap by introducing a counterfactual explanation methodology tailored to explain solutions to data-driven problems. We introduce two classes of explanations and develop methods to find nearest explanations of random forest and nearest-neighbor predictors. We demonstrate our approach by explaining key problems in operations management such as inventory management and routing.
Robust Counterfactual Explanations for Random Forests
May 27, 2022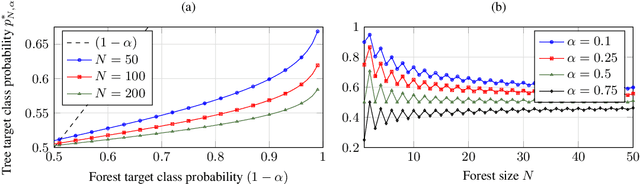
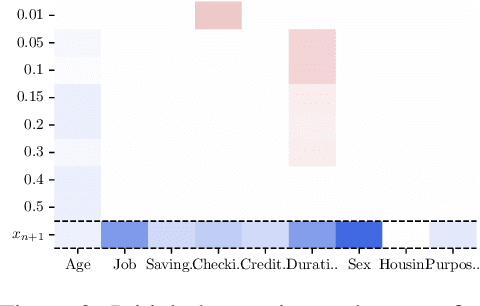
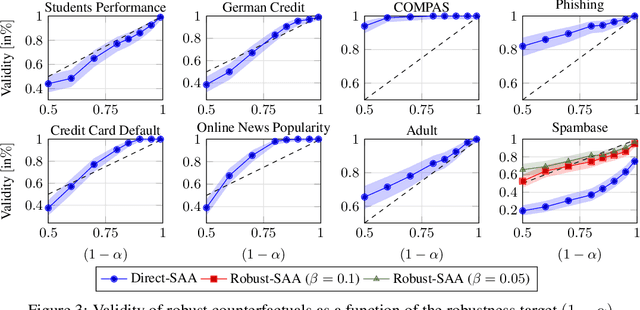
Counterfactual explanations describe how to modify a feature vector in order to flip the outcome of a trained classifier. Several heuristic and optimal methods have been proposed to generate these explanations. However, the robustness of counterfactual explanations when the classifier is re-trained has yet to be studied. Our goal is to obtain counterfactual explanations for random forests that are robust to algorithmic uncertainty. We study the link between the robustness of ensemble models and the robustness of base learners and frame the generation of robust counterfactual explanations as a chance-constrained optimization problem. We develop a practical method with good empirical performance and provide finite-sample and asymptotic guarantees for simple random forests of stumps. We show that existing methods give surprisingly low robustness: the validity of naive counterfactuals is below $50\%$ on most data sets and can fall to $20\%$ on large problem instances with many features. Even with high plausibility, counterfactual explanations often exhibit low robustness to algorithmic uncertainty. In contrast, our method achieves high robustness with only a small increase in the distance from counterfactual explanations to their initial observations. Furthermore, we highlight the connection between the robustness of counterfactual explanations and the predictive importance of features.