 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Differentiable Feasibility Pump
Nov 05, 2024



Although nearly 20 years have passed since its conception, the feasibility pump algorithm remains a widely used heuristic to find feasible primal solutions to mixed-integer linear problems. Many extensions of the initial algorithm have been proposed. Yet, its core algorithm remains centered around two key steps: solving the linear relaxation of the original problem to obtain a solution that respects the constraints, and rounding it to obtain an integer solution. This paper shows that the traditional feasibility pump and many of its follow-ups can be seen as gradient-descent algorithms with specific parameters. A central aspect of this reinterpretation is observing that the traditional algorithm differentiates the solution of the linear relaxation with respect to its cost. This reinterpretation opens many opportunities for improving the performance of the original algorithm. We study how to modify the gradient-update step as well as extending its loss function. We perform extensive experiments on MIPLIB instances and show that these modifications can substantially reduce the number of iterations needed to find a solution.
Structured Pruning of Neural Networks for Constraints Learning
Jul 14, 2023In recent years, the integration of Machine Learning (ML) models with Operation Research (OR) tools has gained popularity across diverse applications, including cancer treatment, algorithmic configuration, and chemical process optimization. In this domain, the combination of ML and OR often relies on representing the ML model output using Mixed Integer Programming (MIP) formulations. Numerous studies in the literature have developed such formulations for many ML predictors, with a particular emphasis on Artificial Neural Networks (ANNs) due to their significant interest in many applications. However, ANNs frequently contain a large number of parameters, resulting in MIP formulations that are impractical to solve, thereby impeding scalability. In fact, the ML community has already introduced several techniques to reduce the parameter count of ANNs without compromising their performance, since the substantial size of modern ANNs presents challenges for ML applications as it significantly impacts computational efforts during training and necessitates significant memory resources for storage. In this paper, we showcase the effectiveness of pruning, one of these techniques, when applied to ANNs prior to their integration into MIPs. By pruning the ANN, we achieve significant improvements in the speed of the solution process. We discuss why pruning is more suitable in this context compared to other ML compression techniques, and we identify the most appropriate pruning strategies. To highlight the potential of this approach, we conduct experiments using feed-forward neural networks with multiple layers to construct adversarial examples. Our results demonstrate that pruning offers remarkable reductions in solution times without hindering the quality of the final decision, enabling the resolution of previously unsolvable instances.
On the Convergence of Stochastic Gradient Descent in Low-precision Number Formats
Jan 09, 2023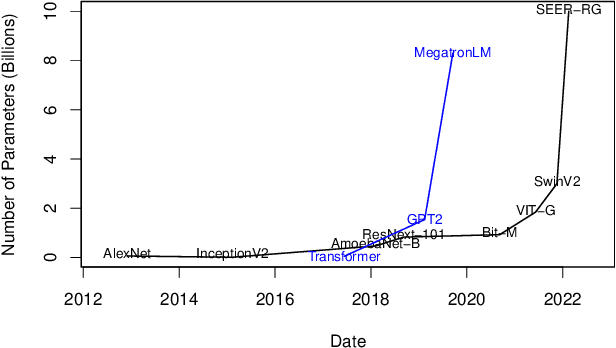
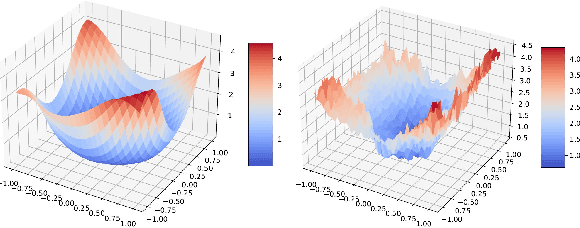
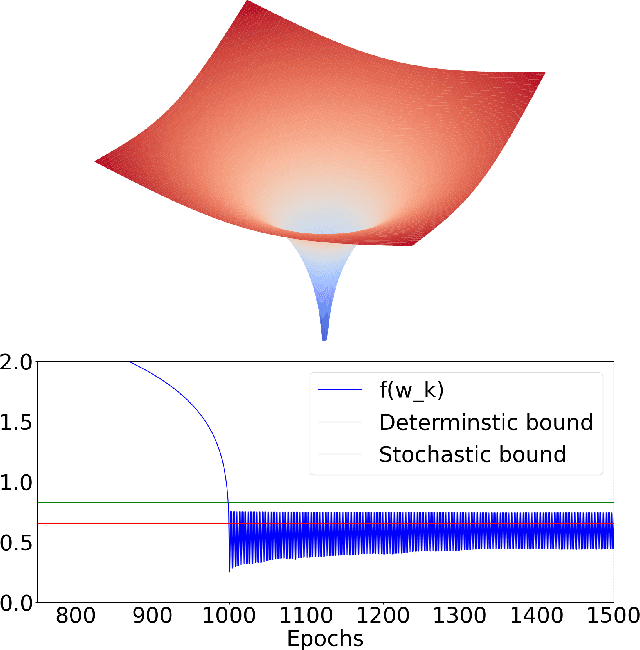
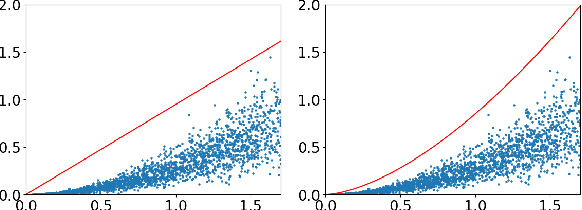
Deep learning models are dominating almost all artificial intelligence tasks such as vision, text, and speech processing. Stochastic Gradient Descent (SGD) is the main tool for training such models, where the computations are usually performed in single-precision floating-point number format. The convergence of single-precision SGD is normally aligned with the theoretical results of real numbers since they exhibit negligible error. However, the numerical error increases when the computations are performed in low-precision number formats. This provides compelling reasons to study the SGD convergence adapted for low-precision computations. We present both deterministic and stochastic analysis of the SGD algorithm, obtaining bounds that show the effect of number format. Such bounds can provide guidelines as to how SGD convergence is affected when constraints render the possibility of performing high-precision computations remote.
Deep Neural Networks pruning via the Structured Perspective Regularization
Jun 28, 2022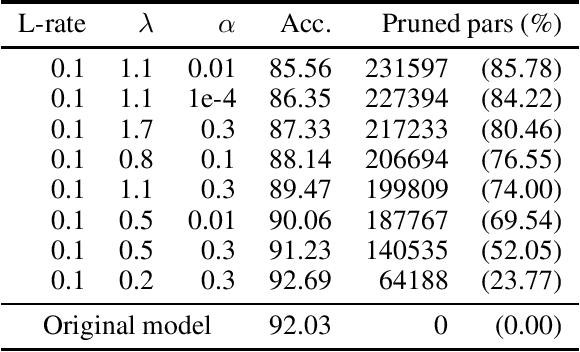
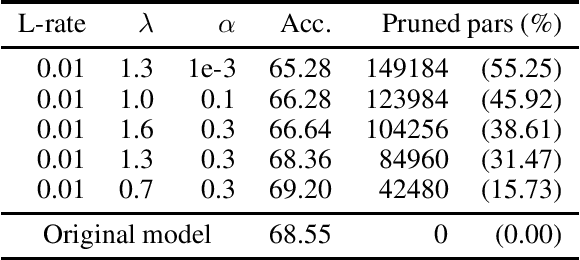
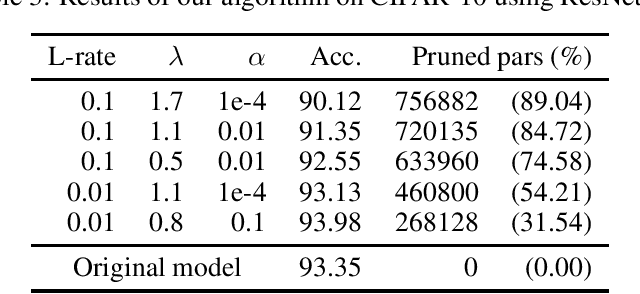
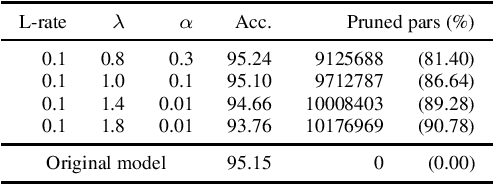
In Machine Learning, Artificial Neural Networks (ANNs) are a very powerful tool, broadly used in many applications. Often, the selected (deep) architectures include many layers, and therefore a large amount of parameters, which makes training, storage and inference expensive. This motivated a stream of research about compressing the original networks into smaller ones without excessively sacrificing performances. Among the many proposed compression approaches, one of the most popular is \emph{pruning}, whereby entire elements of the ANN (links, nodes, channels, \ldots) and the corresponding weights are deleted. Since the nature of the problem is inherently combinatorial (what elements to prune and what not), we propose a new pruning method based on Operational Research tools. We start from a natural Mixed-Integer-Programming model for the problem, and we use the Perspective Reformulation technique to strengthen its continuous relaxation. Projecting away the indicator variables from this reformulation yields a new regularization term, which we call the Structured Perspective Regularization, that leads to structured pruning of the initial architecture. We test our method on some ResNet architectures applied to CIFAR-10, CIFAR-100 and ImageNet datasets, obtaining competitive performances w.r.t.~the state of the art for structured pruning.