 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven decision-making under uncertainty with entropic risk measure
Sep 30, 2024



The entropic risk measure is widely used in high-stakes decision making to account for tail risks associated with an uncertain loss. With limited data, the empirical entropic risk estimator, i.e. replacing the expectation in the entropic risk measure with a sample average, underestimates the true risk. To debias the empirical entropic risk estimator, we propose a strongly asymptotically consistent bootstrapping procedure. The first step of the procedure involves fitting a distribution to the data, whereas the second step estimates the bias of the empirical entropic risk estimator using bootstrapping, and corrects for it. We show that naively fitting a Gaussian Mixture Model to the data using the maximum likelihood criterion typically leads to an underestimation of the risk. To mitigate this issue, we consider two alternative methods: a more computationally demanding one that fits the distribution of empirical entropic risk, and a simpler one that fits the extreme value distribution. As an application of the approach, we study a distributionally robust entropic risk minimization problem with type-$\infty$ Wasserstein ambiguity set, where debiasing the validation performance using our techniques significantly improves the calibration of the size of the ambiguity set. Furthermore, we propose a distributionally robust optimization model for a well-studied insurance contract design problem. The model considers multiple (potential) policyholders that have dependent risks and the insurer and policyholders use entropic risk measure. We show that cross validation methods can result in significantly higher out-of-sample risk for the insurer if the bias in validation performance is not corrected for. This improvement can be explained from the observation that our methods suggest a higher (and more accurate) premium to homeowners.
A Survey of Contextual Optimization Methods for Decision Making under Uncertainty
Jun 17, 2023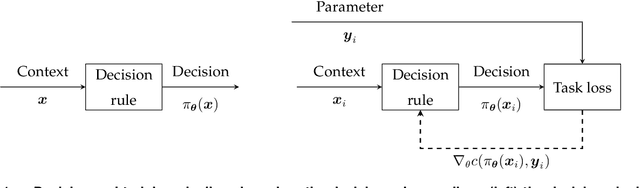



Recently there has been a surge of interest in operations research (OR) and the machine learning (ML) community in combining prediction algorithms and optimization techniques to solve decision-making problems in the face of uncertainty. This gave rise to the field of contextual optimization, under which data-driven procedures are developed to prescribe actions to the decision-maker that make the best use of the most recently updated information. A large variety of models and methods have been presented in both OR and ML literature under a variety of names, including data-driven optimization, prescriptive optimization, predictive stochastic programming, policy optimization, (smart) predict/estimate-then-optimize, decision-focused learning, (task-based) end-to-end learning/forecasting/optimization, etc. Focusing on single and two-stage stochastic programming problems, this review article identifies three main frameworks for learning policies from data and discusses their strengths and limitations. We present the existing models and methods under a uniform notation and terminology and classify them according to the three main frameworks identified. Our objective with this survey is to both strengthen the general understanding of this active field of research and stimulate further theoretical and algorithmic advancements in integrating ML and stochastic programming.