 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA3D: Adaptive Affordance Assembly with Dual-Arm Manipulation
Jan 16, 2026Furniture assembly is a crucial yet challenging task for robots, requiring precise dual-arm coordination where one arm manipulates parts while the other provides collaborative support and stabilization. To accomplish this task more effectively, robots need to actively adapt support strategies throughout the long-horizon assembly process, while also generalizing across diverse part geometries. We propose A3D, a framework which learns adaptive affordances to identify optimal support and stabilization locations on furniture parts. The method employs dense point-level geometric representations to model part interaction patterns, enabling generalization across varied geometries. To handle evolving assembly states, we introduce an adaptive module that uses interaction feedback to dynamically adjust support strategies during assembly based on previous interactions. We establish a simulation environment featuring 50 diverse parts across 8 furniture types, designed for dual-arm collaboration evaluation. Experiments demonstrate that our framework generalizes effectively to diverse part geometries and furniture categories in both simulation and real-world settings.
A Review of Machine Learning for Cavitation Intensity Recognition in Complex Industrial Systems
Nov 19, 2025Cavitation intensity recognition (CIR) is a critical technology for detecting and evaluating cavitation phenomena in hydraulic machinery, with significant implications for operational safety, performance optimization, and maintenance cost reduction in complex industrial systems. Despite substantial research progress, a comprehensive review that systematically traces the development trajectory and provides explicit guidance for future research is still lacking. To bridge this gap, this paper presents a thorough review and analysis of hundreds of publications on intelligent CIR across various types of mechanical equipment from 2002 to 2025, summarizing its technological evolution and offering insights for future development. The early stages are dominated by traditional machine learning approaches that relied on manually engineered features under the guidance of domain expert knowledge. The advent of deep learning has driven the development of end-to-end models capable of automatically extracting features from multi-source signals, thereby significantly improving recognition performance and robustness. Recently, physical informed diagnostic models have been proposed to embed domain knowledge into deep learning models, which can enhance interpretability and cross-condition generalization. In the future, transfer learning, multi-modal fusion, lightweight network architectures, and the deployment of industrial agents are expected to propel CIR technology into a new stage, addressing challenges in multi-source data acquisition, standardized evaluation, and industrial implementation. The paper aims to systematically outline the evolution of CIR technology and highlight the emerging trend of integrating deep learning with physical knowledge. This provides a significant reference for researchers and practitioners in the field of intelligent cavitation diagnosis in complex industrial systems.
DexGarmentLab: Dexterous Garment Manipulation Environment with Generalizable Policy
May 19, 2025Garment manipulation is a critical challenge due to the diversity in garment categories, geometries, and deformations. Despite this, humans can effortlessly handle garments, thanks to the dexterity of our hands. However, existing research in the field has struggled to replicate this level of dexterity, primarily hindered by the lack of realistic simulations of dexterous garment manipulation. Therefore, we propose DexGarmentLab, the first environment specifically designed for dexterous (especially bimanual) garment manipulation, which features large-scale high-quality 3D assets for 15 task scenarios, and refines simulation techniques tailored for garment modeling to reduce the sim-to-real gap. Previous data collection typically relies on teleoperation or training expert reinforcement learning (RL) policies, which are labor-intensive and inefficient. In this paper, we leverage garment structural correspondence to automatically generate a dataset with diverse trajectories using only a single expert demonstration, significantly reducing manual intervention. However, even extensive demonstrations cannot cover the infinite states of garments, which necessitates the exploration of new algorithms. To improve generalization across diverse garment shapes and deformations, we propose a Hierarchical gArment-manipuLation pOlicy (HALO). It first identifies transferable affordance points to accurately locate the manipulation area, then generates generalizable trajectories to complete the task. Through extensive experiments and detailed analysis of our method and baseline, we demonstrate that HALO consistently outperforms existing methods, successfully generalizing to previously unseen instances even with significant variations in shape and deformation where others fail. Our project page is available at: https://wayrise.github.io/DexGarmentLab/.
Dual Policy Reinforcement Learning for Real-time Rebalancing in Bike-sharing Systems
Jun 02, 2024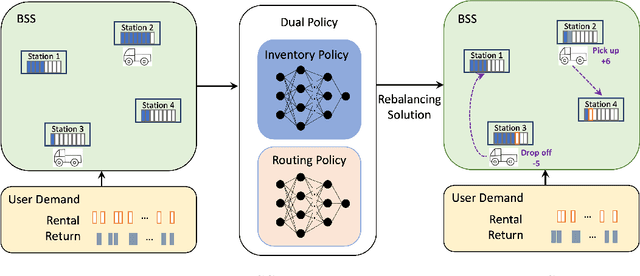


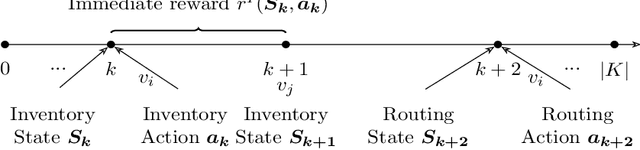
Bike-sharing systems play a crucial role in easing traffic congestion and promoting healthier lifestyles. However, ensuring their reliability and user acceptance requires effective strategies for rebalancing bikes. This study introduces a novel approach to address the real-time rebalancing problem with a fleet of vehicles. It employs a dual policy reinforcement learning algorithm that decouples inventory and routing decisions, enhancing realism and efficiency compared to previous methods where both decisions were made simultaneously. We first formulate the inventory and routing subproblems as a multi-agent Markov Decision Process within a continuous time framework. Subsequently, we propose a DQN-based dual policy framework to jointly estimate the value functions, minimizing the lost demand. To facilitate learning, a comprehensive simulator is applied to operate under a first-arrive-first-serve rule, which enables the computation of immediate rewards across diverse demand scenarios. We conduct extensive experiments on various datasets generated from historical real-world data, affected by both temporal and weather factors. Our proposed algorithm demonstrates significant performance improvements over previous baseline methods. It offers valuable practical insights for operators and further explores the incorporation of reinforcement learning into real-world dynamic programming problems, paving the way for more intelligent and robust urban mobility solutions.
A Reinforcement Learning Approach for Dynamic Rebalancing in Bike-Sharing System
Feb 05, 2024


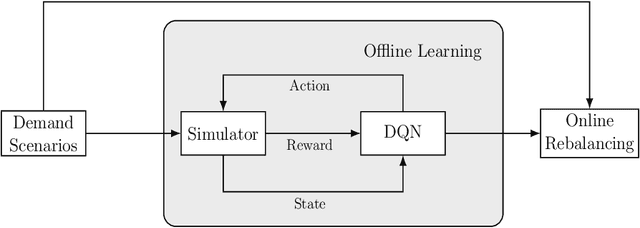
Bike-Sharing Systems provide eco-friendly urban mobility, contributing to the alleviation of traffic congestion and to healthier lifestyles. Efficiently operating such systems and maintaining high customer satisfaction is challenging due to the stochastic nature of trip demand, leading to full or empty stations. Devising effective rebalancing strategies using vehicles to redistribute bikes among stations is therefore of uttermost importance for operators. As a promising alternative to classical mathematical optimization, reinforcement learning is gaining ground to solve sequential decision-making problems. This paper introduces a spatio-temporal reinforcement learning algorithm for the dynamic rebalancing problem with multiple vehicles. We first formulate the problem as a Multi-agent Markov Decision Process in a continuous time framework. This allows for independent and cooperative vehicle rebalancing, eliminating the impractical restriction of time-discretized models where vehicle departures are synchronized. A comprehensive simulator under the first-arrive-first-serve rule is then developed to facilitate the learning process by computing immediate rewards under diverse demand scenarios. To estimate the value function and learn the rebalancing policy, various Deep Q-Network configurations are tested, minimizing the lost demand. Experiments are carried out on various datasets generated from historical data, affected by both temporal and weather factors. The proposed algorithms outperform benchmarks, including a multi-period Mixed-Integer Programming model, in terms of lost demand. Once trained, it yields immediate decisions, making it suitable for real-time applications. Our work offers practical insights for operators and enriches the integration of reinforcement learning into dynamic rebalancing problems, paving the way for more intelligent and robust urban mobility solutions.
Wasserstein Diversity-Enriched Regularizer for Hierarchical Reinforcement Learning
Aug 02, 2023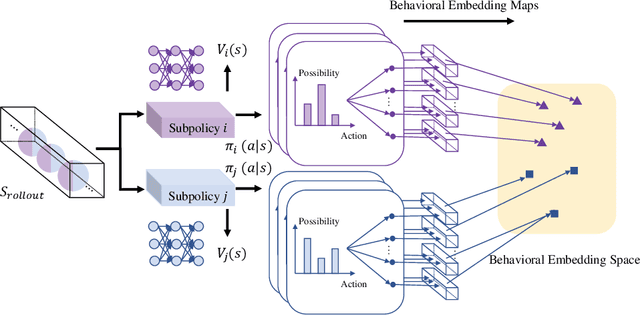



Hierarchical reinforcement learning composites subpolicies in different hierarchies to accomplish complex tasks.Automated subpolicies discovery, which does not depend on domain knowledge, is a promising approach to generating subpolicies.However, the degradation problem is a challenge that existing methods can hardly deal with due to the lack of consideration of diversity or the employment of weak regularizers. In this paper, we propose a novel task-agnostic regularizer called the Wasserstein Diversity-Enriched Regularizer (WDER), which enlarges the diversity of subpolicies by maximizing the Wasserstein distances among action distributions. The proposed WDER can be easily incorporated into the loss function of existing methods to boost their performance further.Experimental results demonstrate that our WDER improves performance and sample efficiency in comparison with prior work without modifying hyperparameters, which indicates the applicability and robustness of the WDER.