 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Policy Reinforcement Learning for Real-time Rebalancing in Bike-sharing Systems
Jun 02, 2024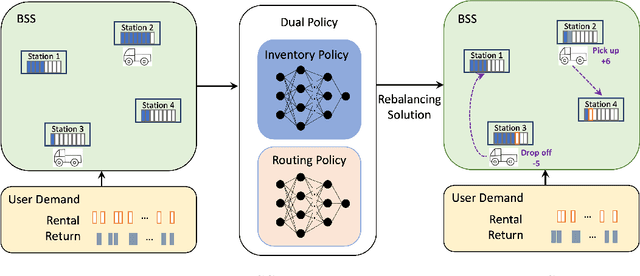


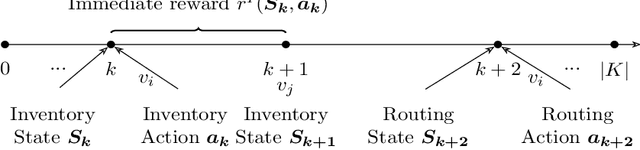
Bike-sharing systems play a crucial role in easing traffic congestion and promoting healthier lifestyles. However, ensuring their reliability and user acceptance requires effective strategies for rebalancing bikes. This study introduces a novel approach to address the real-time rebalancing problem with a fleet of vehicles. It employs a dual policy reinforcement learning algorithm that decouples inventory and routing decisions, enhancing realism and efficiency compared to previous methods where both decisions were made simultaneously. We first formulate the inventory and routing subproblems as a multi-agent Markov Decision Process within a continuous time framework. Subsequently, we propose a DQN-based dual policy framework to jointly estimate the value functions, minimizing the lost demand. To facilitate learning, a comprehensive simulator is applied to operate under a first-arrive-first-serve rule, which enables the computation of immediate rewards across diverse demand scenarios. We conduct extensive experiments on various datasets generated from historical real-world data, affected by both temporal and weather factors. Our proposed algorithm demonstrates significant performance improvements over previous baseline methods. It offers valuable practical insights for operators and further explores the incorporation of reinforcement learning into real-world dynamic programming problems, paving the way for more intelligent and robust urban mobility solutions.
A Reinforcement Learning Approach for Dynamic Rebalancing in Bike-Sharing System
Feb 05, 2024


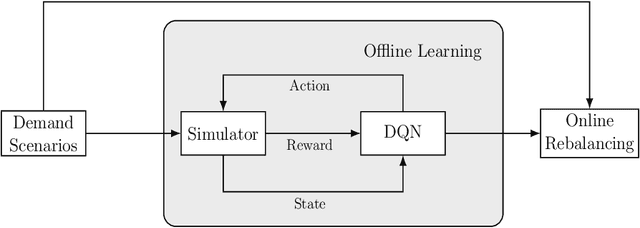
Bike-Sharing Systems provide eco-friendly urban mobility, contributing to the alleviation of traffic congestion and to healthier lifestyles. Efficiently operating such systems and maintaining high customer satisfaction is challenging due to the stochastic nature of trip demand, leading to full or empty stations. Devising effective rebalancing strategies using vehicles to redistribute bikes among stations is therefore of uttermost importance for operators. As a promising alternative to classical mathematical optimization, reinforcement learning is gaining ground to solve sequential decision-making problems. This paper introduces a spatio-temporal reinforcement learning algorithm for the dynamic rebalancing problem with multiple vehicles. We first formulate the problem as a Multi-agent Markov Decision Process in a continuous time framework. This allows for independent and cooperative vehicle rebalancing, eliminating the impractical restriction of time-discretized models where vehicle departures are synchronized. A comprehensive simulator under the first-arrive-first-serve rule is then developed to facilitate the learning process by computing immediate rewards under diverse demand scenarios. To estimate the value function and learn the rebalancing policy, various Deep Q-Network configurations are tested, minimizing the lost demand. Experiments are carried out on various datasets generated from historical data, affected by both temporal and weather factors. The proposed algorithms outperform benchmarks, including a multi-period Mixed-Integer Programming model, in terms of lost demand. Once trained, it yields immediate decisions, making it suitable for real-time applications. Our work offers practical insights for operators and enriches the integration of reinforcement learning into dynamic rebalancing problems, paving the way for more intelligent and robust urban mobility solutions.
On the estimation of discrete choice models to capture irrational customer behaviors
Sep 08, 2021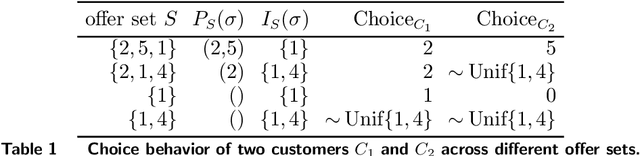


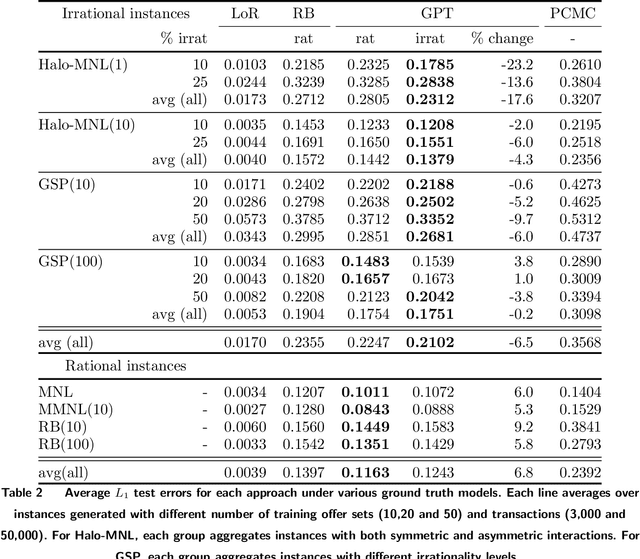
The Random Utility Maximization model is by far the most adopted framework to estimate consumer choice behavior. However, behavioral economics has provided strong empirical evidence of irrational choice behavior, such as halo effects, that are incompatible with this framework. Models belonging to the Random Utility Maximization family may therefore not accurately capture such irrational behavior. Hence, more general choice models, overcoming such limitations, have been proposed. However, the flexibility of such models comes at the price of increased risk of overfitting. As such, estimating such models remains a challenge. In this work, we propose an estimation method for the recently proposed Generalized Stochastic Preference choice model, which subsumes the family of Random Utility Maximization models and is capable of capturing halo effects. Specifically, we show how to use partially-ranked preferences to efficiently model rational and irrational customer types from transaction data. Our estimation procedure is based on column generation, where relevant customer types are efficiently extracted by expanding a tree-like data structure containing the customer behaviors. Further, we propose a new dominance rule among customer types whose effect is to prioritize low orders of interactions among products. An extensive set of experiments assesses the predictive accuracy of the proposed approach. Our results show that accounting for irrational preferences can boost predictive accuracy by 12.5% on average, when tested on a real-world dataset from a large chain of grocery and drug stores.