 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
InertialAR: Autoregressive 3D Molecule Generation with Inertial Frames
Oct 31, 2025Transformer-based autoregressive models have emerged as a unifying paradigm across modalities such as text and images, but their extension to 3D molecule generation remains underexplored. The gap stems from two fundamental challenges: (1) tokenizing molecules into a canonical 1D sequence of tokens that is invariant to both SE(3) transformations and atom index permutations, and (2) designing an architecture capable of modeling hybrid atom-based tokens that couple discrete atom types with continuous 3D coordinates. To address these challenges, we introduce InertialAR. InertialAR devises a canonical tokenization that aligns molecules to their inertial frames and reorders atoms to ensure SE(3) and permutation invariance. Moreover, InertialAR equips the attention mechanism with geometric awareness via geometric rotary positional encoding (GeoRoPE). In addition, it utilizes a hierarchical autoregressive paradigm to predict the next atom-based token, predicting the atom type first and then its 3D coordinates via Diffusion loss. Experimentally, InertialAR achieves state-of-the-art performance on 7 of the 10 evaluation metrics for unconditional molecule generation across QM9, GEOM-Drugs, and B3LYP. Moreover, it significantly outperforms strong baselines in controllable generation for targeted chemical functionality, attaining state-of-the-art results across all 5 metrics.
BoostDream: Efficient Refining for High-Quality Text-to-3D Generation from Multi-View Diffusion
Jan 30, 2024



Witnessing the evolution of text-to-image diffusion models, significant strides have been made in text-to-3D generation. Currently, two primary paradigms dominate the field of text-to-3D: the feed-forward generation solutions, capable of swiftly producing 3D assets but often yielding coarse results, and the Score Distillation Sampling (SDS) based solutions, known for generating high-fidelity 3D assets albeit at a slower pace. The synergistic integration of these methods holds substantial promise for advancing 3D generation techniques. In this paper, we present BoostDream, a highly efficient plug-and-play 3D refining method designed to transform coarse 3D assets into high-quality. The BoostDream framework comprises three distinct processes: (1) We introduce 3D model distillation that fits differentiable representations from the 3D assets obtained through feed-forward generation. (2) A novel multi-view SDS loss is designed, which utilizes a multi-view aware 2D diffusion model to refine the 3D assets. (3) We propose to use prompt and multi-view consistent normal maps as guidance in refinement.Our extensive experiment is conducted on different differentiable 3D representations, revealing that BoostDream excels in generating high-quality 3D assets rapidly, overcoming the Janus problem compared to conventional SDS-based methods. This breakthrough signifies a substantial advancement in both the efficiency and quality of 3D generation processes.
Wasserstein Diversity-Enriched Regularizer for Hierarchical Reinforcement Learning
Aug 02, 2023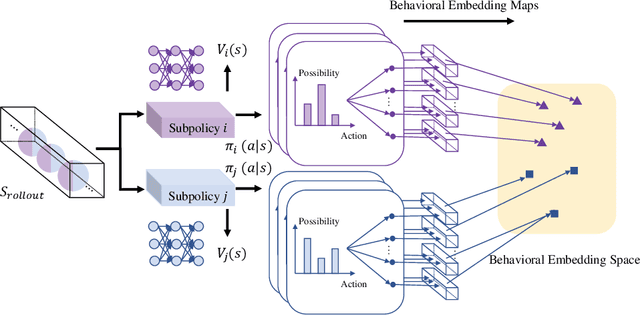



Hierarchical reinforcement learning composites subpolicies in different hierarchies to accomplish complex tasks.Automated subpolicies discovery, which does not depend on domain knowledge, is a promising approach to generating subpolicies.However, the degradation problem is a challenge that existing methods can hardly deal with due to the lack of consideration of diversity or the employment of weak regularizers. In this paper, we propose a novel task-agnostic regularizer called the Wasserstein Diversity-Enriched Regularizer (WDER), which enlarges the diversity of subpolicies by maximizing the Wasserstein distances among action distributions. The proposed WDER can be easily incorporated into the loss function of existing methods to boost their performance further.Experimental results demonstrate that our WDER improves performance and sample efficiency in comparison with prior work without modifying hyperparameters, which indicates the applicability and robustness of the WDER.