 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Unveiled: Can Exposure to More In-context Examples Mitigate Uncertainty for Large Language Models?
May 27, 2025Recent advances in handling long sequences have facilitated the exploration of long-context in-context learning (ICL). While much of the existing research emphasizes performance improvements driven by additional in-context examples, the influence on the trustworthiness of generated responses remains underexplored. This paper addresses this gap by investigating how increased examples influence predictive uncertainty, an essential aspect in trustworthiness. We begin by systematically quantifying the uncertainty of ICL with varying shot counts, analyzing the impact of example quantity. Through uncertainty decomposition, we introduce a novel perspective on performance enhancement, with a focus on epistemic uncertainty (EU). Our results reveal that additional examples reduce total uncertainty in both simple and complex tasks by injecting task-specific knowledge, thereby diminishing EU and enhancing performance. For complex tasks, these advantages emerge only after addressing the increased noise and uncertainty associated with longer inputs. Finally, we explore the evolution of internal confidence across layers, unveiling the mechanisms driving the reduction in uncertainty.
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Jan 08, 2024



The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.
The RoSiD Tool: Empowering Users to Design Multimodal Signals for Human-Robot Collaboration
Jan 05, 2024



Robots that cooperate with humans must be effective at communicating with them. However, people have varied preferences for communication based on many contextual factors, such as culture, environment, and past experience. To communicate effectively, robots must take those factors into consideration. In this work, we present the Robot Signal Design (RoSiD) tool to empower people to easily self-specify communicative preferences for collaborative robots. We show through a participatory design study that the RoSiD tool enables users to create signals that align with their communicative preferences, and we illuminate how this tool can be further improved.
LDM$^2$: A Large Decision Model Imitating Human Cognition with Dynamic Memory Enhancement
Dec 13, 2023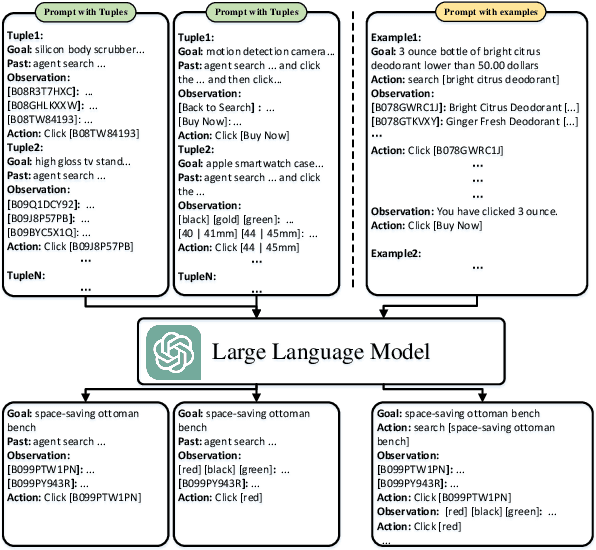
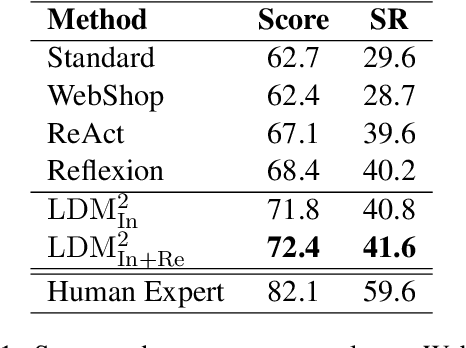
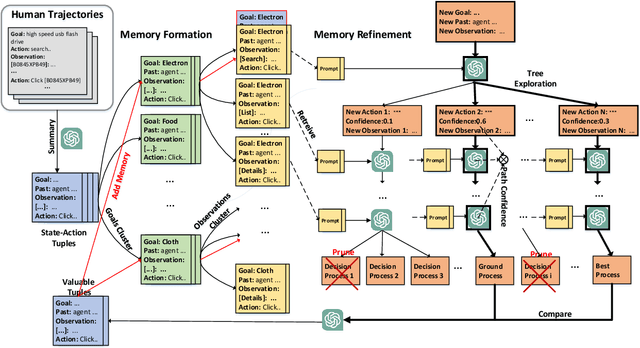
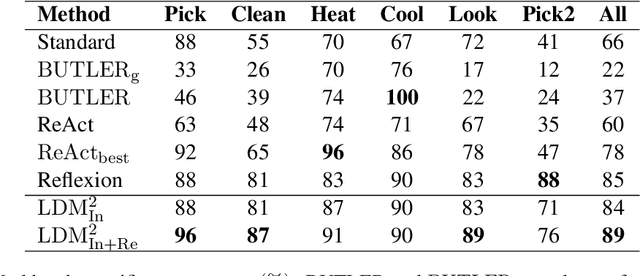
With the rapid development of large language models (LLMs), it is highly demanded that LLMs can be adopted to make decisions to enable the artificial general intelligence. Most approaches leverage manually crafted examples to prompt the LLMs to imitate the decision process of human. However, designing optimal prompts is difficult and the patterned prompts can hardly be generalized to more complex environments. In this paper, we propose a novel model named Large Decision Model with Memory (LDM$^2$), which leverages a dynamic memory mechanism to construct dynamic prompts, guiding the LLMs in making proper decisions according to the faced state. LDM$^2$ consists of two stages: memory formation and memory refinement. In the former stage, human behaviors are decomposed into state-action tuples utilizing the powerful summarizing ability of LLMs. Then, these tuples are stored in the memory, whose indices are generated by the LLMs, to facilitate the retrieval of the most relevant subset of memorized tuples based on the current state. In the latter stage, our LDM$^2$ employs tree exploration to discover more suitable decision processes and enrich the memory by adding valuable state-action tuples. The dynamic circle of exploration and memory enhancement provides LDM$^2$ a better understanding of the global environment. Extensive experiments conducted in two interactive environments have shown that our LDM$^2$ outperforms the baselines in terms of both score and success rate, which demonstrates its effectiveness.
Wasserstein Diversity-Enriched Regularizer for Hierarchical Reinforcement Learning
Aug 02, 2023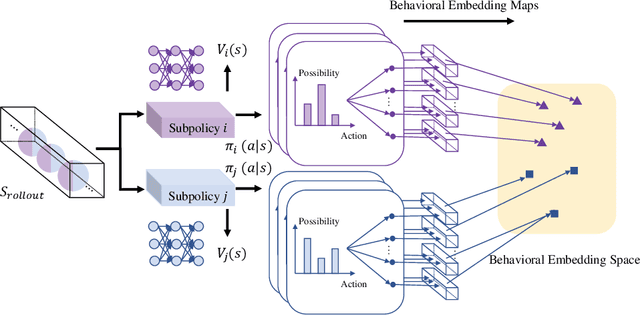



Hierarchical reinforcement learning composites subpolicies in different hierarchies to accomplish complex tasks.Automated subpolicies discovery, which does not depend on domain knowledge, is a promising approach to generating subpolicies.However, the degradation problem is a challenge that existing methods can hardly deal with due to the lack of consideration of diversity or the employment of weak regularizers. In this paper, we propose a novel task-agnostic regularizer called the Wasserstein Diversity-Enriched Regularizer (WDER), which enlarges the diversity of subpolicies by maximizing the Wasserstein distances among action distributions. The proposed WDER can be easily incorporated into the loss function of existing methods to boost their performance further.Experimental results demonstrate that our WDER improves performance and sample efficiency in comparison with prior work without modifying hyperparameters, which indicates the applicability and robustness of the WDER.
PRODIGY: Enabling In-context Learning Over Graphs
May 21, 2023In-context learning is the ability of a pretrained model to adapt to novel and diverse downstream tasks by conditioning on prompt examples, without optimizing any parameters. While large language models have demonstrated this ability, how in-context learning could be performed over graphs is unexplored. In this paper, we develop \textbf{Pr}etraining \textbf{O}ver \textbf{D}iverse \textbf{I}n-Context \textbf{G}raph S\textbf{y}stems (PRODIGY), the first pretraining framework that enables in-context learning over graphs. The key idea of our framework is to formulate in-context learning over graphs with a novel \emph{prompt graph} representation, which connects prompt examples and queries. We then propose a graph neural network architecture over the prompt graph and a corresponding family of in-context pretraining objectives. With PRODIGY, the pretrained model can directly perform novel downstream classification tasks on unseen graphs via in-context learning. We provide empirical evidence of the effectiveness of our framework by showcasing its strong in-context learning performance on tasks involving citation networks and knowledge graphs. Our approach outperforms the in-context learning accuracy of contrastive pretraining baselines with hard-coded adaptation by 18\% on average across all setups. Moreover, it also outperforms standard finetuning with limited data by 33\% on average with in-context learning.
ViRel: Unsupervised Visual Relations Discovery with Graph-level Analogy
Jul 04, 2022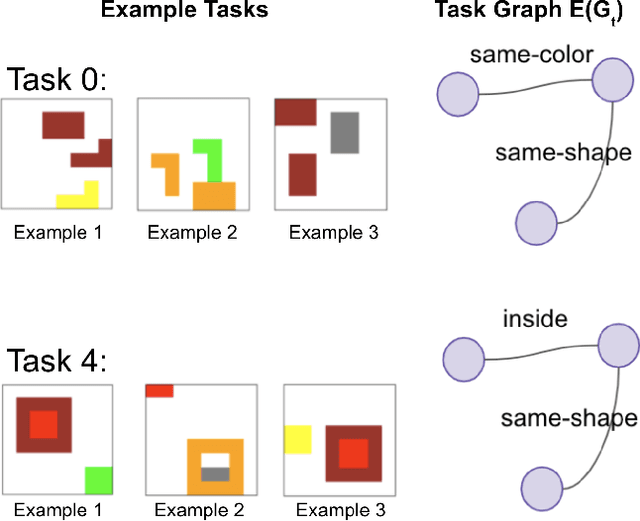

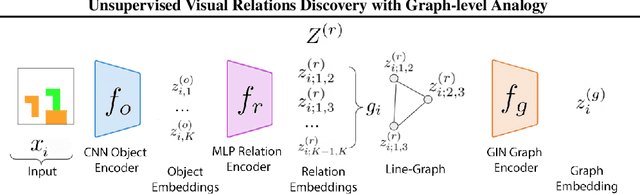
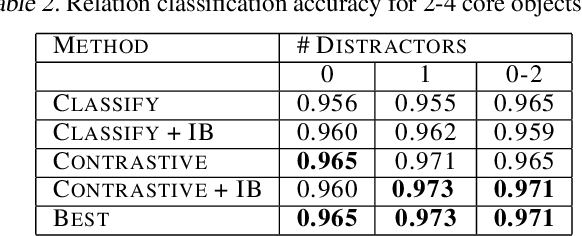
Visual relations form the basis of understanding our compositional world, as relationships between visual objects capture key information in a scene. It is then advantageous to learn relations automatically from the data, as learning with predefined labels cannot capture all possible relations. However, current relation learning methods typically require supervision, and are not designed to generalize to scenes with more complicated relational structures than those seen during training. Here, we introduce ViRel, a method for unsupervised discovery and learning of Visual Relations with graph-level analogy. In a setting where scenes within a task share the same underlying relational subgraph structure, our learning method of contrasting isomorphic and non-isomorphic graphs discovers the relations across tasks in an unsupervised manner. Once the relations are learned, ViRel can then retrieve the shared relational graph structure for each task by parsing the predicted relational structure. Using a dataset based on grid-world and the Abstract Reasoning Corpus, we show that our method achieves above 95% accuracy in relation classification, discovers the relation graph structure for most tasks, and further generalizes to unseen tasks with more complicated relational structures.
Boosting Multi-Label Image Classification with Complementary Parallel Self-Distillation
May 23, 2022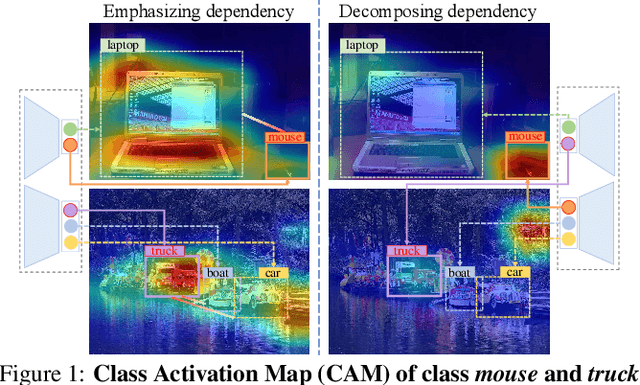
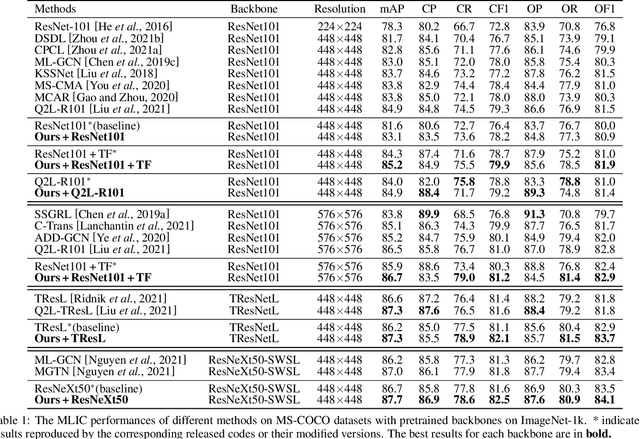
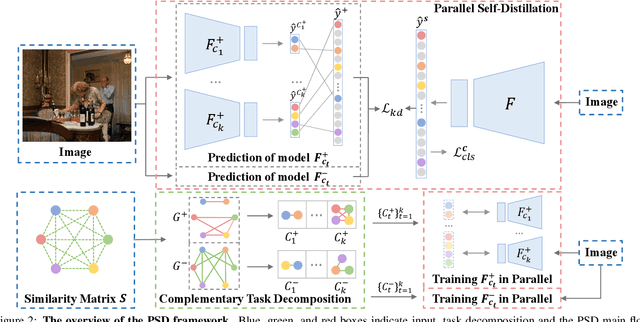
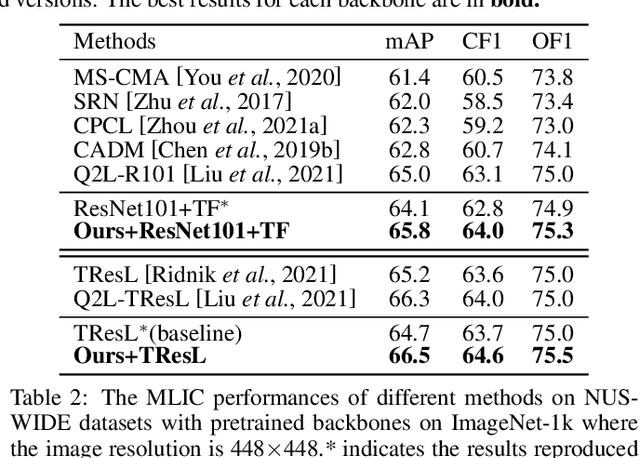
Multi-Label Image Classification (MLIC) approaches usually exploit label correlations to achieve good performance. However, emphasizing correlation like co-occurrence may overlook discriminative features of the target itself and lead to model overfitting, thus undermining the performance. In this study, we propose a generic framework named Parallel Self-Distillation (PSD) for boosting MLIC models. PSD decomposes the original MLIC task into several simpler MLIC sub-tasks via two elaborated complementary task decomposition strategies named Co-occurrence Graph Partition (CGP) and Dis-occurrence Graph Partition (DGP). Then, the MLIC models of fewer categories are trained with these sub-tasks in parallel for respectively learning the joint patterns and the category-specific patterns of labels. Finally, knowledge distillation is leveraged to learn a compact global ensemble of full categories with these learned patterns for reconciling the label correlation exploitation and model overfitting. Extensive results on MS-COCO and NUS-WIDE datasets demonstrate that our framework can be easily plugged into many MLIC approaches and improve performances of recent state-of-the-art approaches. The explainable visual study also further validates that our method is able to learn both the category-specific and co-occurring features. The source code is released at https://github.com/Robbie-Xu/CPSD.
Aggregate effects of advertising decisions: a complex systems look at search engine advertising via an experimental study
Mar 04, 2022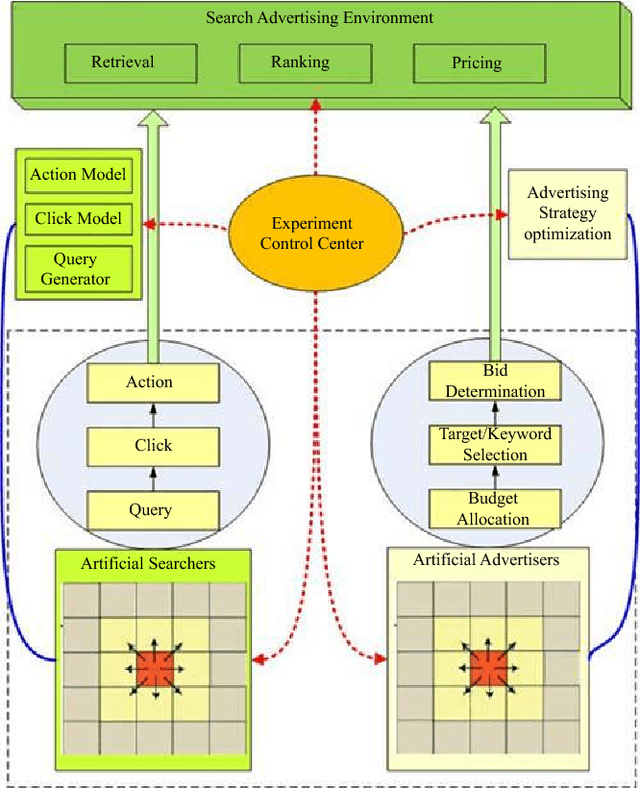
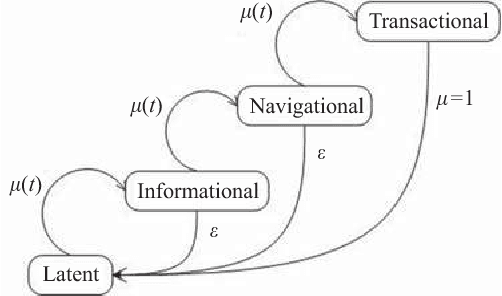
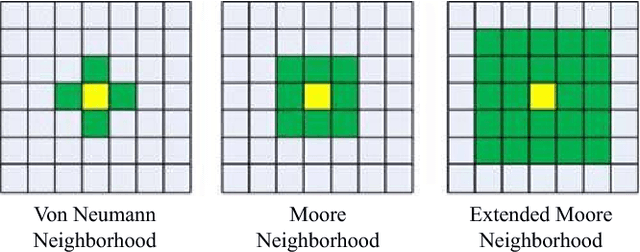
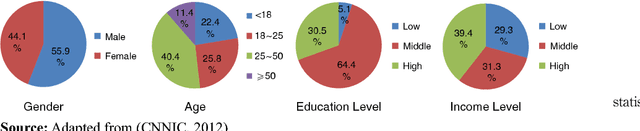
Purpose: We model group advertising decisions, which are the collective decisions of every single advertiser within the set of advertisers who are competing in the same auction or vertical industry, and examine resulting market outcomes, via a proposed simulation framework named EXP-SEA (Experimental Platform for Search Engine Advertising) supporting experimental studies of collective behaviors in the context of search engine advertising. Design: We implement the EXP-SEA to validate the proposed simulation framework, also conduct three experimental studies on the aggregate impact of electronic word-of-mouth, the competition level, and strategic bidding behaviors. EXP-SEA supports heterogeneous participants, various auction mechanisms, and also ranking and pricing algorithms. Findings: Findings from our three experiments show that (a) both the market profit and advertising indexes such as number of impressions and number of clicks are larger when the eWOM effect presents, meaning social media certainly has some effect on search engine advertising outcomes, (b) the competition level has a monotonic increasing effect on the market performance, thus search engines have an incentive to encourage both the eWOM among search users and competition among advertisers, and (c) given the market-level effect of the percentage of advertisers employing a dynamic greedy bidding strategy, there is a cut-off point for strategic bidding behaviors. Originality: This is one of the first research works to explore collective group decisions and resulting phenomena in the complex context of search engine advertising via developing and validating a simulation framework that supports assessments of various advertising strategies and estimations of the impact of mechanisms on the search market.
* 26 pages, 7 figures, 5 tables
Learning Parameters for a Generalized Vidale-Wolfe Response Model with Flexible Ad Elasticity and Word-of-Mouth
Feb 28, 2022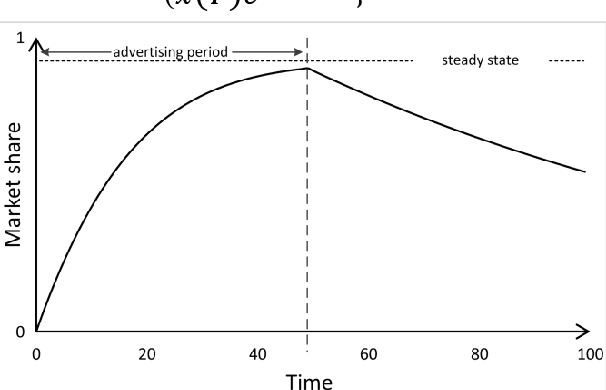
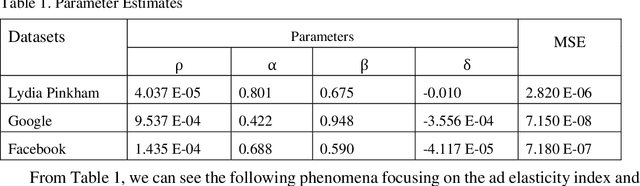
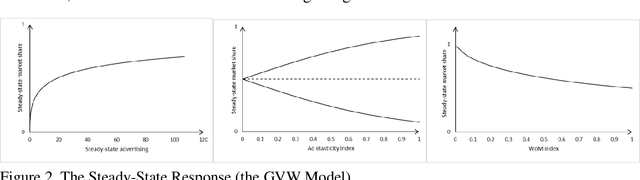
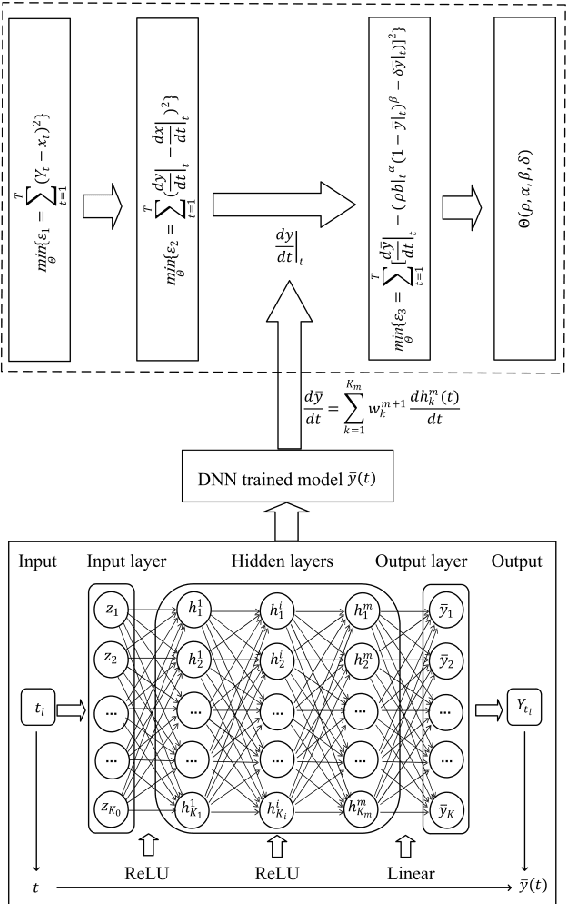
In this research, we investigate a generalized form of Vidale-Wolfe (GVW) model. One key element of our modeling work is that the GVW model contains two useful indexes representing advertiser's elasticity and the word-of-mouth (WoM) effect, respectively. Moreover, we discuss some desirable properties of the GVW model, and present a deep neural network (DNN)-based estimation method to learn its parameters. Furthermore, based on three realworld datasets, we conduct computational experiments to validate the GVW model and identified properties. In addition, we also discuss potential advantages of the GVW model over econometric models. The research outcome shows that both the ad elasticity index and the WoM index have significant influences on advertising responses, and the GVW model has potential advantages over econometric models of advertising, in terms of several interesting phenomena drawn from practical advertising situations. The GVW model and its deep learning-based estimation method provide a basis to support big data-driven advertising analytics and decision makings; in the meanwhile, identified properties and experimental findings of this research illuminate critical managerial insights for advertisers in various advertising forms.
* 20 pages, 8 figures, 1 table