 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHAT: Modeling Period Heterogeneity for Multivariate Time Series Forecasting
Jan 31, 2026While existing multivariate time series forecasting models have advanced significantly in modeling periodicity, they largely neglect the periodic heterogeneity common in real-world data, where variates exhibit distinct and dynamically changing periods. To effectively capture this periodic heterogeneity, we propose PHAT (Period Heterogeneity-Aware Transformer). Specifically, PHAT arranges multivariate inputs into a three-dimensional "periodic bucket" tensor, where the dimensions correspond to variate group characteristics with similar periodicity, time steps aligned by phase, and offsets within the period. By restricting interactions within buckets and masking cross-bucket connections, PHAT effectively avoids interference from inconsistent periods. We also propose a positive-negative attention mechanism, which captures periodic dependencies from two perspectives: periodic alignment and periodic deviation. Additionally, the periodic alignment attention scores are decomposed into positive and negative components, with a modulation term encoding periodic priors. This modulation constrains the attention mechanism to more faithfully reflect the underlying periodic trends. A mathematical explanation is provided to support this property. We evaluate PHAT comprehensively on 14 real-world datasets against 18 baselines, and the results show that it significantly outperforms existing methods, achieving highly competitive forecasting performance. Our sources is available at GitHub.
A Compact Dynamic Omnidirectional Antenna
Jun 12, 2025We propose a novel omnidirectional antenna design incorporating directional modulation for secure narrow planar information transmission. The proposed antenna features a compact size and stable omnidirectional radiation performance by employing two tightly spaced, printed meander line monopole antennas, acting as a single radiating element. To achieve a narrow information secure region, the proposed antenna is fed by differential power excitation of two ports with real-time dynamic switching. This leads to phase pattern modulation only along the electrical polarization, resulting in directionally confined information recoverable region in the E-plane, while maintaining highly constant or static omnidirectional H-plane pattern, inducing a $360^\circ$ information recoverable region. The dynamic antenna is designed and fabricated on a single layer of Rogers RO4350B which provides a miniaturized planar size of $0.36 \times 0.5 , \lambda_0^2$ at 2.7 GHz and easy integration. To validate the wireless communication performance, the fabricated antenna is directly fed with a 10 dB power ratio by a radio frequency (RF) switching system and evaluated for 16-QAM and 256-QAM transmission in a high signal-to-noise ratio (SNR) environment. Experimental results demonstrate that for 16-QAM transmission, a narrow E-plane information beam (IB) of approximately $34^\circ$ and omnidirectional H-plane IB are obtained, and a narrower E-plane IB is achieved around $15^\circ$ for 256-QAM. These results confirm that the proposed antenna offers a simple yet effective approach to enhance planar physical information security with a compact dynamic antenna system.
Spatiotemporal Causal Decoupling Model for Air Quality Forecasting
May 26, 2025Due to the profound impact of air pollution on human health, livelihoods, and economic development, air quality forecasting is of paramount significance. Initially, we employ the causal graph method to scrutinize the constraints of existing research in comprehensively modeling the causal relationships between the air quality index (AQI) and meteorological features. In order to enhance prediction accuracy, we introduce a novel air quality forecasting model, AirCade, which incorporates a causal decoupling approach. AirCade leverages a spatiotemporal module in conjunction with knowledge embedding techniques to capture the internal dynamics of AQI. Subsequently, a causal decoupling module is proposed to disentangle synchronous causality from past AQI and meteorological features, followed by the dissemination of acquired knowledge to future time steps to enhance performance. Additionally, we introduce a causal intervention mechanism to explicitly represent the uncertainty of future meteorological features, thereby bolstering the model's robustness. Our evaluation of AirCade on an open-source air quality dataset demonstrates over 20\% relative improvement over state-of-the-art models.
A Compact Narrowband Antenna Design for RF Fingerprinting Applications
May 20, 2025Radio frequency (RF) fingerprinting is widely used for supporting physical layer security in various wireless applications. In this paper, we present the design and implementation of a small antenna with low-cost fabrication that can be directly integrated with nonlinear passive devices, forming a passive RF tag providing unique nonlinear signatures for RF fingerprinting. We first propose a miniaturized meander line dipole, achieved by two folded arms on two sides of the substrate. This leads to antenna with a simple feeding structure and compact size, making it ideal for planar integration. Two antennas on Rogers 4350B and ultra-thin flexible Panasonic Felios are fabricated, achieving small size at $0.21 \times 0.06 \times 0.004 \lambda_0^3$ and $0.14 \times 0.1 \times 0.0008 \lambda_0^3$ with realized gain of 1.87 dBi and 1.46 dBi. The passive tag consists of the proposed antenna structure and an integrated RF diode, and is further developed on both substrates, aiming to generate inter-modulation products (IMP) due to the nonlinearity of the diode, which can be used for device identification through classification algorithms. We investigate the nonlinearity of the designed tags for transmission at 15 dBm using two-tone signals. All tags produce a significant increased power at IMP frequencies at a range of 0.4 m. The tags on Rogers substrate provide around 23 dB IMP power increase and tags on flexible substrate embedded in lossy material provide around 16 dB power increase. These findings confirm that the proposed solution offers a simple passive tag design to support unique nonlinear signatures for RF fingerprinting applications in a simple, low-cost device.
THESAURUS: Contrastive Graph Clustering by Swapping Fused Gromov-Wasserstein Couplings
Dec 16, 2024



Graph node clustering is a fundamental unsupervised task. Existing methods typically train an encoder through selfsupervised learning and then apply K-means to the encoder output. Some methods use this clustering result directly as the final assignment, while others initialize centroids based on this initial clustering and then finetune both the encoder and these learnable centroids. However, due to their reliance on K-means, these methods inherit its drawbacks when the cluster separability of encoder output is low, facing challenges from the Uniform Effect and Cluster Assimilation. We summarize three reasons for the low cluster separability in existing methods: (1) lack of contextual information prevents discrimination between similar nodes from different clusters; (2) training tasks are not sufficiently aligned with the downstream clustering task; (3) the cluster information in the graph structure is not appropriately exploited. To address these issues, we propose conTrastive grapH clustEring by SwApping fUsed gRomov-wasserstein coUplingS (THESAURUS). Our method introduces semantic prototypes to provide contextual information, and employs a cross-view assignment prediction pretext task that aligns well with the downstream clustering task. Additionally, it utilizes Gromov-Wasserstein Optimal Transport (GW-OT) along with the proposed prototype graph to thoroughly exploit cluster information in the graph structure. To adapt to diverse real-world data, THESAURUS updates the prototype graph and the prototype marginal distribution in OT by using momentum. Extensive experiments demonstrate that THESAURUS achieves higher cluster separability than the prior art, effectively mitigating the Uniform Effect and Cluster Assimilation issues
Category-Prompt Refined Feature Learning for Long-Tailed Multi-Label Image Classification
Aug 15, 2024



Real-world data consistently exhibits a long-tailed distribution, often spanning multiple categories. This complexity underscores the challenge of content comprehension, particularly in scenarios requiring Long-Tailed Multi-Label image Classification (LTMLC). In such contexts, imbalanced data distribution and multi-object recognition pose significant hurdles. To address this issue, we propose a novel and effective approach for LTMLC, termed Category-Prompt Refined Feature Learning (CPRFL), utilizing semantic correlations between different categories and decoupling category-specific visual representations for each category. Specifically, CPRFL initializes category-prompts from the pretrained CLIP's embeddings and decouples category-specific visual representations through interaction with visual features, thereby facilitating the establishment of semantic correlations between the head and tail classes. To mitigate the visual-semantic domain bias, we design a progressive Dual-Path Back-Propagation mechanism to refine the prompts by progressively incorporating context-related visual information into prompts. Simultaneously, the refinement process facilitates the progressive purification of the category-specific visual representations under the guidance of the refined prompts. Furthermore, taking into account the negative-positive sample imbalance, we adopt the Asymmetric Loss as our optimization objective to suppress negative samples across all classes and potentially enhance the head-to-tail recognition performance. We validate the effectiveness of our method on two LTMLC benchmarks and extensive experiments demonstrate the superiority of our work over baselines. The code is available at https://github.com/jiexuanyan/CPRFL.
SAM-MIL: A Spatial Contextual Aware Multiple Instance Learning Approach for Whole Slide Image Classification
Jul 25, 2024
Multiple Instance Learning (MIL) represents the predominant framework in Whole Slide Image (WSI) classification, covering aspects such as sub-typing, diagnosis, and beyond. Current MIL models predominantly rely on instance-level features derived from pretrained models such as ResNet. These models segment each WSI into independent patches and extract features from these local patches, leading to a significant loss of global spatial context and restricting the model's focus to merely local features. To address this issue, we propose a novel MIL framework, named SAM-MIL, that emphasizes spatial contextual awareness and explicitly incorporates spatial context by extracting comprehensive, image-level information. The Segment Anything Model (SAM) represents a pioneering visual segmentation foundational model that can capture segmentation features without the need for additional fine-tuning, rendering it an outstanding tool for extracting spatial context directly from raw WSIs. Our approach includes the design of group feature extraction based on spatial context and a SAM-Guided Group Masking strategy to mitigate class imbalance issues. We implement a dynamic mask ratio for different segmentation categories and supplement these with representative group features of categories. Moreover, SAM-MIL divides instances to generate additional pseudo-bags, thereby augmenting the training set, and introduces consistency of spatial context across pseudo-bags to further enhance the model's performance. Experimental results on the CAMELYON-16 and TCGA Lung Cancer datasets demonstrate that our proposed SAM-MIL model outperforms existing mainstream methods in WSIs classification. Our open-source implementation code is is available at https://github.com/FangHeng/SAM-MIL.
Advances in Robust Federated Learning: Heterogeneity Considerations
May 16, 2024In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
Feature Re-Embedding: Towards Foundation Model-Level Performance in Computational Pathology
Feb 27, 2024Multiple instance learning (MIL) is the most widely used framework in computational pathology, encompassing sub-typing, diagnosis, prognosis, and more. However, the existing MIL paradigm typically requires an offline instance feature extractor, such as a pre-trained ResNet or a foundation model. This approach lacks the capability for feature fine-tuning within the specific downstream tasks, limiting its adaptability and performance. To address this issue, we propose a Re-embedded Regional Transformer (R$^2$T) for re-embedding the instance features online, which captures fine-grained local features and establishes connections across different regions. Unlike existing works that focus on pre-training powerful feature extractor or designing sophisticated instance aggregator, R$^2$T is tailored to re-embed instance features online. It serves as a portable module that can seamlessly integrate into mainstream MIL models. Extensive experimental results on common computational pathology tasks validate that: 1) feature re-embedding improves the performance of MIL models based on ResNet-50 features to the level of foundation model features, and further enhances the performance of foundation model features; 2) the R$^2$T can introduce more significant performance improvements to various MIL models; 3) R$^2$T-MIL, as an R$^2$T-enhanced AB-MIL, outperforms other latest methods by a large margin. The code is available at:~\href{https://github.com/DearCaat/RRT-MIL}{https://github.com/DearCaat/RRT-MIL}.
Data Distribution Distilled Generative Model for Generalized Zero-Shot Recognition
Feb 18, 2024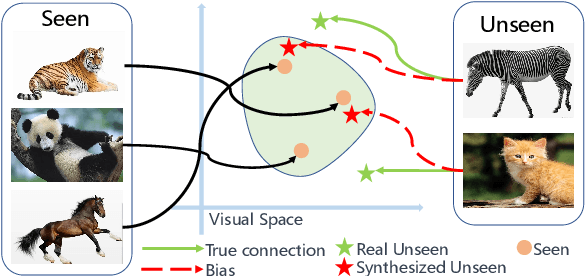
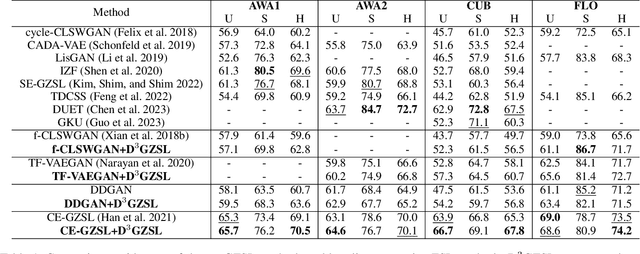
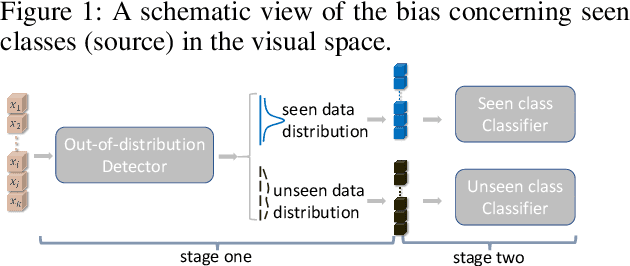

In the realm of Zero-Shot Learning (ZSL), we address biases in Generalized Zero-Shot Learning (GZSL) models, which favor seen data. To counter this, we introduce an end-to-end generative GZSL framework called D$^3$GZSL. This framework respects seen and synthesized unseen data as in-distribution and out-of-distribution data, respectively, for a more balanced model. D$^3$GZSL comprises two core modules: in-distribution dual space distillation (ID$^2$SD) and out-of-distribution batch distillation (O$^2$DBD). ID$^2$SD aligns teacher-student outcomes in embedding and label spaces, enhancing learning coherence. O$^2$DBD introduces low-dimensional out-of-distribution representations per batch sample, capturing shared structures between seen and unseen categories. Our approach demonstrates its effectiveness across established GZSL benchmarks, seamlessly integrating into mainstream generative frameworks. Extensive experiments consistently showcase that D$^3$GZSL elevates the performance of existing generative GZSL methods, underscoring its potential to refine zero-shot learning practices.The code is available at: https://github.com/PJBQ/D3GZSL.git