 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShattering the Autoregressive Curse: Dynamic Epistemic Entropy Orchestrated Erasable Reinforcement Learning for LLMs
Jun 16, 2026Although reinforcement learning (RL) has expanded the cognitive boundaries of large language models (LLMs), it often remains vulnerable to the autoregressive curse in long-horizon logical reasoning: small epistemic perturbations introduced early in generation can propagate irreversibly along the Markov decision process flow, triggering cascading failures that drive the reasoning trajectory toward collapse. To overcome this autoregressive cascade, in which a single early mistake can compromise all subsequent reasoning steps, we propose dynamic epistemic entropy orchestrated erasable reinforcement learning ($\text{E}^3\text{RL}$). $\text{E}^3\text{RL}$ eliminates reliance on external signals by grounding the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. By introducing segment-level adaptive dynamic thresholds and advantage allocation, $\text{E}^3\text{RL}$ enables the model to precisely excise localized logical defects while reusing historical key-value (KV) cache streams, thereby endowing the reasoning process with a self-healing capability. We train $\text{E}^3\text{RL}$ on the DeepMath-103k dataset. Experimental results show that $\text{E}^3\text{RL}$ reshapes the exploration efficiency of long-sequence reasoning and improves sample efficiency while maintaining linear memory overhead. On mathematical reasoning benchmarks such as AIME, $\text{E}^3\text{RL}$ achieves substantial performance gains, with the 4B and 8B parameter models surpassing previous state-of-the-art (SOTA) results by 5.349\% and 6.514\%, respectively. These findings suggest that $\text{E}^3\text{RL}$ shatters the autoregressive curse in long-sequence reasoning and establishes a theoretical and systems-level foundation for the next generation of self-healing artificial general intelligence (AGI).
Decoupled Residual Quantization for Robust Semantic IDs in Recommendation
Jun 01, 2026Semantic IDs represent items as shared discrete token sequences and have become a practical tool for recommendation and retrieval. Yet it remains difficult to tell why a tokenizer fails: poor quality may come from codebook underutilization, unstable decision boundaries, or geometric distortion of the embedding space. This paper develops a quantitative framework for diagnosing these failures through expected codeword overlap and effective codebook capacity. The former measures expected codeword confusion under retrieval-time perturbation, while the latter converts that confusion into an effective number of usable, well-separated codes. The framework links semantic boundary confusion to both code usage imbalance and Euclidean geometric constraints. As a proof of concept, we present Decoupled Residual Quantization (DRQ), which separates continuous geometry reconstruction from discrete distribution matching. Experiments on a large-scale industrial dataset show that Semantic ID quality is multi-objective: symbolic robustness, reconstruction fidelity, and behavior-aware soft matching each stress different aspects of a tokenizer. These downstream observations are based on one proprietary industrial dataset, so they should be read as a case study rather than a universal benchmark claim.
SELF-EMO: Emotional Self-Evolution from Recognition to Consistent Expression
Apr 20, 2026Emotion Recognition in Conversation (ERC) has become a fundamental capability for large language models (LLMs) in human-centric interaction. Beyond accurate recognition, coherent emotional expression is also crucial, yet both are limited by the scarcity and static nature of high-quality annotated data. In this work, we propose SELF-EMO, a self-evolution framework grounded in the hypothesis that better emotion prediction leads to more consistent emotional responses. We introduce two auxiliary tasks, emotional understanding and emotional expression, and design a role-based self-play paradigm where the model acts as both an emotion recognizer and a dialogue responder. Through iterative interactions, the model generates diverse conversational trajectories, enabling scalable data generation. To ensure quality, we adopt a data flywheel mechanism that filters candidate predictions and responses using a smoothed IoU-based reward and feeds selected samples back for continuous self-improvement without external supervision. We further develop SELF-GRPO, a reinforcement learning algorithm that stabilizes optimization with multi-label alignment rewards and group-level consistency signals. Experiments on IEMOCAP, MELD, and EmoryNLP show that SELF-EMO achieves state-of-the-art performance, improving accuracy by +6.33% on Qwen3-4B and +8.54% on Qwen3-8B, demonstrating strong effectiveness and generalization.
UniRec: Bridging the Expressive Gap between Generative and Discriminative Recommendation via Chain-of-Attribute
Apr 14, 2026Generative Recommendation (GR) reframes retrieval and ranking as autoregressive decoding over Semantic IDs (SIDs), unifying the multi-stage pipeline into a single model. Yet a fundamental expressive gap persists: discriminative models score items with direct feature access, enabling explicit user-item crossing, whereas GR decodes over compact SID tokens without item-side signal. We formalize this via Bayes' theorem, showing ranking by p(y|f,u) is equivalent to ranking by p(f|y,u), which factorizes autoregressively over item features. This establishes that a generative model with full feature access is as expressive as its discriminative counterpart; any practical gap stems solely from incomplete feature coverage. We propose UniRec with Chain-of-Attribute (CoA) as its core mechanism. CoA prefixes each SID sequence with structured attribute tokens--category, seller, brand--before decoding the SID itself, recovering the item-side feature crossing that discriminative models exploit. Because items sharing identical attributes cluster in adjacent SID regions, attribute conditioning yields a measurable per-step entropy reduction H(s_k|s_{<k},a) < H(s_k|s_{<k}), narrowing the search space and stabilizing beam search trajectories. We further address two deployment challenges: Capacity-constrained SID introduces exposure-weighted capacity penalties into residual quantization to suppress token collapse and the Matthew effect across SID layers; Conditional Decoding Context (CDC) combines Task-Conditioned BOS with hash-based Content Summaries, injecting scenario-conditioned signals at each decoding step. A joint RFT and DPO framework aligns the model with business objectives beyond distribution matching. Experiments show UniRec outperforms the strongest baseline by +22.6% HR@50 overall and +15.5% on high-value orders, with online A/B tests confirming significant business metric gains.
MMRPT: MultiModal Reinforcement Pre-Training via Masked Vision-Dependent Reasoning
Dec 08, 2025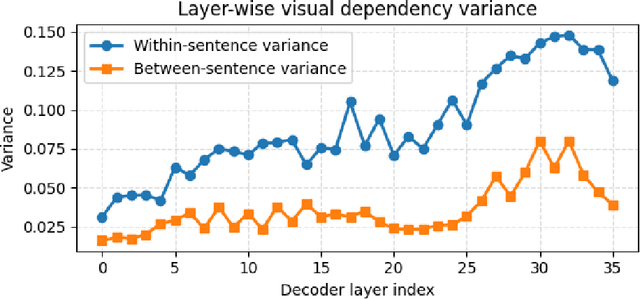
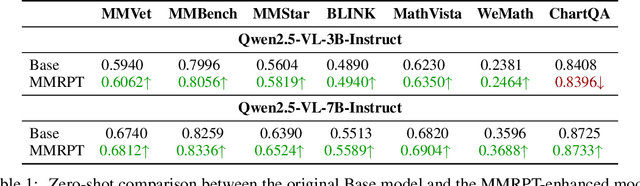

Multimodal pre-training remains constrained by the descriptive bias of image-caption pairs, leading models to favor surface linguistic cues over grounded visual understanding. We introduce MMRPT, a masked multimodal reinforcement pre-training framework that strengthens visual reasoning in MLLMs. We are the first to incorporate reinforcement learning directly into the pre-training of large vision-language models, enabling learning signals that reward visual grounding rather than caption imitation. MMRPT constructs masked multimodal data by estimating sentence-level visual dependency via attention over visual tokens and masking highly vision-dependent segments; the model reconstructs these spans through vision-grounded reasoning guided by a semantic-visual reward. Experiments show consistent zero-shot gains across diverse benchmarks and substantially improved robustness under supervised fine-tuning, demonstrating that reinforcement-driven masked reasoning provides a more reliable and generalizable pre-training objective for multimodal models.
Erase to Improve: Erasable Reinforcement Learning for Search-Augmented LLMs
Oct 01, 2025While search-augmented large language models (LLMs) exhibit impressive capabilities, their reliability in complex multi-hop reasoning remains limited. This limitation arises from three fundamental challenges: decomposition errors, where tasks are incorrectly broken down; retrieval missing, where key evidence fails to be retrieved; and reasoning errors, where flawed logic propagates through the reasoning chain. A single failure in any of these stages can derail the final answer. We propose Erasable Reinforcement Learning (ERL), a novel framework that transforms fragile reasoning into a robust process. ERL explicitly identifies faulty steps, erases them, and regenerates reasoning in place, preventing defective logic from propagating through the reasoning chain. This targeted correction mechanism turns brittle reasoning into a more resilient process. Models trained with ERL, termed ESearch, achieve substantial improvements on HotpotQA, MuSiQue, 2Wiki, and Bamboogle, with the 3B model achieving +8.48% EM and +11.56% F1, and the 7B model achieving +5.38% EM and +7.22% F1 over previous state-of-the-art(SOTA) results. These findings suggest that erasable reinforcement learning provides a powerful paradigm shift for robust multi-step reasoning in LLMs.
StepSearch: Igniting LLMs Search Ability via Step-Wise Proximal Policy Optimization
May 21, 2025Efficient multi-hop reasoning requires Large Language Models (LLMs) based agents to acquire high-value external knowledge iteratively. Previous work has explored reinforcement learning (RL) to train LLMs to perform search-based document retrieval, achieving notable improvements in QA performance, but underperform on complex, multi-hop QA resulting from the sparse rewards from global signal only. To address this gap in existing research, we introduce StepSearch, a framework for search LLMs that trained with step-wise proximal policy optimization method. It consists of richer and more detailed intermediate search rewards and token-level process supervision based on information gain and redundancy penalties to better guide each search step. We constructed a fine-grained question-answering dataset containing sub-question-level search trajectories based on open source datasets through a set of data pipeline method. On standard multi-hop QA benchmarks, it significantly outperforms global-reward baselines, achieving 11.2% and 4.2% absolute improvements for 3B and 7B models over various search with RL baselines using only 19k training data, demonstrating the effectiveness of fine-grained, stepwise supervision in optimizing deep search LLMs. Our implementation is publicly available at https://github.com/zxh20001117/StepSearch.
QoSBERT: An Uncertainty-Aware Approach based on Pre-trained Language Models for Service Quality Prediction
May 09, 2025Accurate prediction of Quality of Service (QoS) metrics is fundamental for selecting and managing cloud based services. Traditional QoS models rely on manual feature engineering and yield only point estimates, offering no insight into the confidence of their predictions. In this paper, we propose QoSBERT, the first framework that reformulates QoS prediction as a semantic regression task based on pre trained language models. Unlike previous approaches relying on sparse numerical features, QoSBERT automatically encodes user service metadata into natural language descriptions, enabling deep semantic understanding. Furthermore, we integrate a Monte Carlo Dropout based uncertainty estimation module, allowing for trustworthy and risk-aware service quality prediction, which is crucial yet underexplored in existing QoS models. QoSBERT applies attentive pooling over contextualized embeddings and a lightweight multilayer perceptron regressor, fine tuned jointly to minimize absolute error. We further exploit the resulting uncertainty estimates to select high quality training samples, improving robustness in low resource settings. On standard QoS benchmark datasets, QoSBERT achieves an average reduction of 11.7% in MAE and 6.7% in RMSE for response time prediction, and 6.9% in MAE for throughput prediction compared to the strongest baselines, while providing well calibrated confidence intervals for robust and trustworthy service quality estimation. Our approach not only advances the accuracy of service quality prediction but also delivers reliable uncertainty quantification, paving the way for more trustworthy, data driven service selection and optimization.
Point2Quad: Generating Quad Meshes from Point Clouds via Face Prediction
Apr 28, 2025Quad meshes are essential in geometric modeling and computational mechanics. Although learning-based methods for triangle mesh demonstrate considerable advancements, quad mesh generation remains less explored due to the challenge of ensuring coplanarity, convexity, and quad-only meshes. In this paper, we present Point2Quad, the first learning-based method for quad-only mesh generation from point clouds. The key idea is learning to identify quad mesh with fused pointwise and facewise features. Specifically, Point2Quad begins with a k-NN-based candidate generation considering the coplanarity and squareness. Then, two encoders are followed to extract geometric and topological features that address the challenge of quad-related constraints, especially by combining in-depth quadrilaterals-specific characteristics. Subsequently, the extracted features are fused to train the classifier with a designed compound loss. The final results are derived after the refinement by a quad-specific post-processing. Extensive experiments on both clear and noise data demonstrate the effectiveness and superiority of Point2Quad, compared to baseline methods under comprehensive metrics.
A Centralized-Distributed Transfer Model for Cross-Domain Recommendation Based on Multi-Source Heterogeneous Transfer Learning
Nov 14, 2024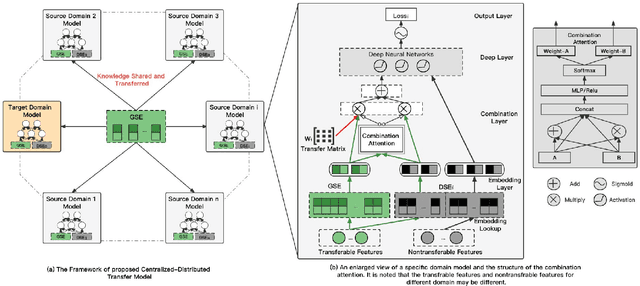
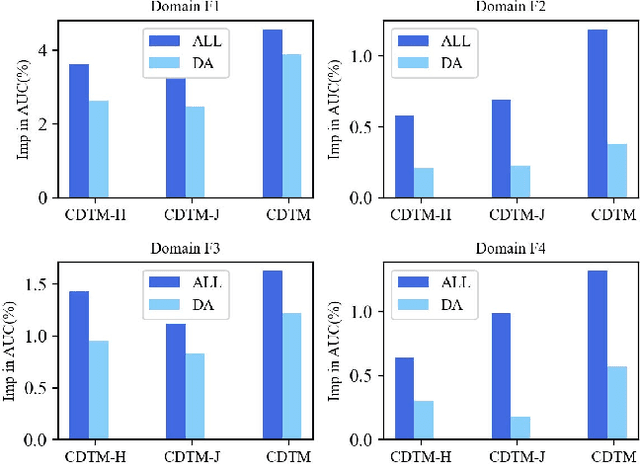
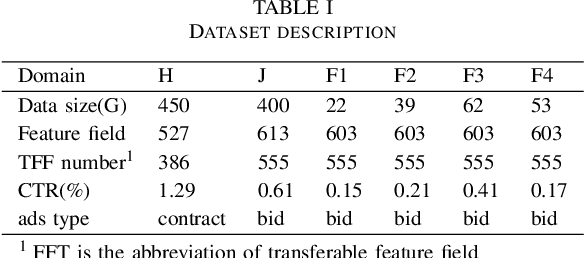

Cross-domain recommendation (CDR) methods are proposed to tackle the sparsity problem in click through rate (CTR) estimation. Existing CDR methods directly transfer knowledge from the source domains to the target domain and ignore the heterogeneities among domains, including feature dimensional heterogeneity and latent space heterogeneity, which may lead to negative transfer. Besides, most of the existing methods are based on single-source transfer, which cannot simultaneously utilize knowledge from multiple source domains to further improve the model performance in the target domain. In this paper, we propose a centralized-distributed transfer model (CDTM) for CDR based on multi-source heterogeneous transfer learning. To address the issue of feature dimension heterogeneity, we build a dual embedding structure: domain specific embedding (DSE) and global shared embedding (GSE) to model the feature representation in the single domain and the commonalities in the global space,separately. To solve the latent space heterogeneity, the transfer matrix and attention mechanism are used to map and combine DSE and GSE adaptively. Extensive offline and online experiments demonstrate the effectiveness of our model.