 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-MultiPose: Tuning-Free Multi-Character Text-to-Video Generation via Pose Guidance
Dec 21, 2024



Text-editable and pose-controllable character video generation is a challenging but prevailing topic with practical applications. However, existing approaches mainly focus on single-object video generation with pose guidance, ignoring the realistic situation that multi-character appear concurrently in a scenario. To tackle this, we propose a novel multi-character video generation framework in a tuning-free manner, which is based on the separated text and pose guidance. Specifically, we first extract character masks from the pose sequence to identify the spatial position for each generating character, and then single prompts for each character are obtained with LLMs for precise text guidance. Moreover, the spatial-aligned cross attention and multi-branch control module are proposed to generate fine grained controllable multi-character video. The visualized results of generating video demonstrate the precise controllability of our method for multi-character generation. We also verify the generality of our method by applying it to various personalized T2I models. Moreover, the quantitative results show that our approach achieves superior performance compared with previous works.
A Probability Distribution and Location-aware ResNet Approach for QoS Prediction
Nov 16, 2020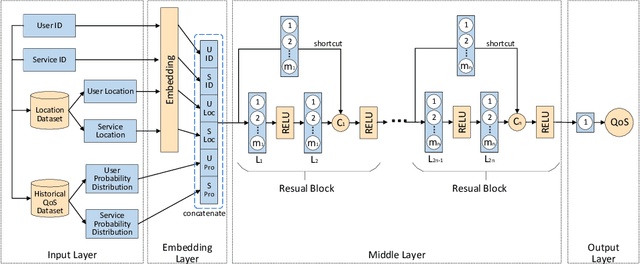
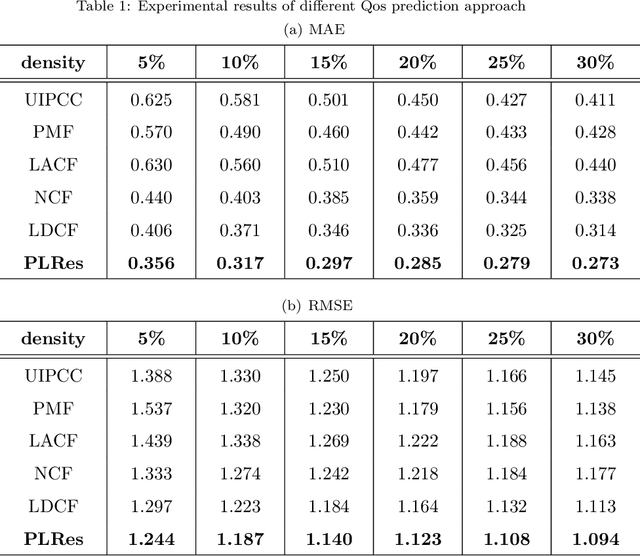

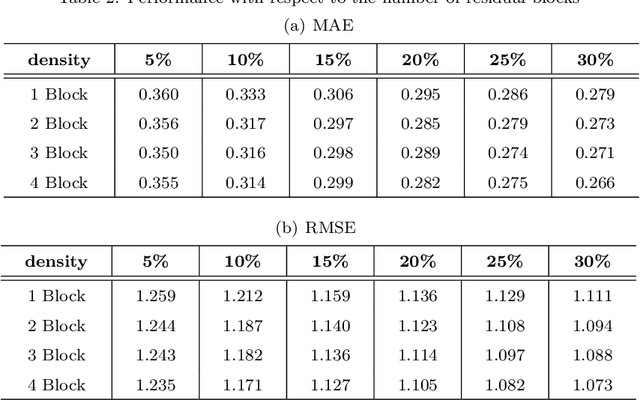
In recent years, the number of online services has grown rapidly, invoke the required services through the cloud platform has become the primary trend. How to help users choose and recommend high-quality services among huge amounts of unused services has become a hot issue in research. Among the existing QoS prediction methods, the collaborative filtering(CF) method can only learn low-dimensional linear characteristics, and its effect is limited by sparse data. Although existing deep learning methods could capture high-dimensional nonlinear features better, most of them only use the single feature of identity, and the problem of network deepening gradient disappearance is serious, so the effect of QoS prediction is unsatisfactory. To address these problems, we propose an advanced probability distribution and location-aware ResNet approach for QoS Prediction(PLRes). This approach considers the historical invocations probability distribution and location characteristics of users and services, and first use the ResNet in QoS prediction to reuses the features, which alleviates the problems of gradient disappearance and model degradation. A series of experiments are conducted on a real-world web service dataset WS-DREAM. The results indicate that PLRes model is effective for QoS prediction and at the density of 5%-30%, which means the data is sparse, it significantly outperforms a state-of-the-art approach LDCF by 12.35%-15.37% in terms of MAE.