 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Phase LLM Reasoning: Self-Evolved Mathematical Frameworks
Jan 09, 2026In recent years, large language models (LLMs) have demonstrated significant potential in complex reasoning tasks like mathematical problem-solving. However, existing research predominantly relies on reinforcement learning (RL) frameworks while overlooking supervised fine-tuning (SFT) methods. This paper proposes a new two-stage training framework that enhances models' self-correction capabilities through self-generated long chain-of-thought (CoT) data. During the first stage, a multi-turn dialogue strategy guides the model to generate CoT data incorporating verification, backtracking, subgoal decomposition, and backward reasoning, with predefined rules filtering high-quality samples for supervised fine-tuning. The second stage employs a difficulty-aware rejection sampling mechanism to dynamically optimize data distribution, strengthening the model's ability to handle complex problems. The approach generates reasoning chains extended over 4 times longer while maintaining strong scalability, proving that SFT effectively activates models' intrinsic reasoning capabilities and provides a resource-efficient pathway for complex task optimization. Experimental results demonstrate performance improvements on mathematical benchmarks including GSM8K and MATH500, with the fine-tuned model achieving a substantial improvement on competition-level problems like AIME24. Code will be open-sourced.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025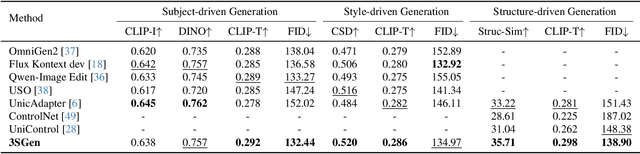
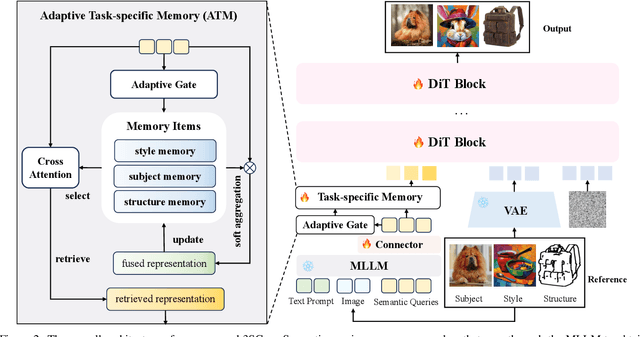
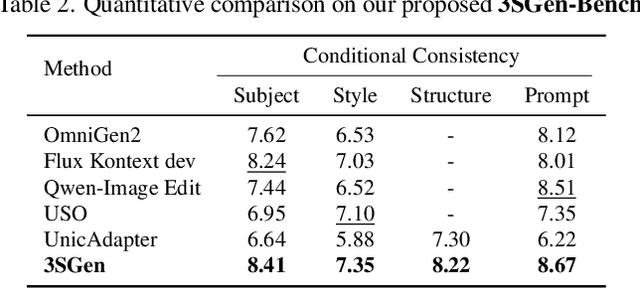
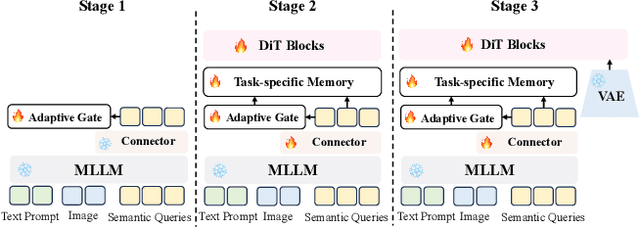
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
Follow-Your-MultiPose: Tuning-Free Multi-Character Text-to-Video Generation via Pose Guidance
Dec 21, 2024



Text-editable and pose-controllable character video generation is a challenging but prevailing topic with practical applications. However, existing approaches mainly focus on single-object video generation with pose guidance, ignoring the realistic situation that multi-character appear concurrently in a scenario. To tackle this, we propose a novel multi-character video generation framework in a tuning-free manner, which is based on the separated text and pose guidance. Specifically, we first extract character masks from the pose sequence to identify the spatial position for each generating character, and then single prompts for each character are obtained with LLMs for precise text guidance. Moreover, the spatial-aligned cross attention and multi-branch control module are proposed to generate fine grained controllable multi-character video. The visualized results of generating video demonstrate the precise controllability of our method for multi-character generation. We also verify the generality of our method by applying it to various personalized T2I models. Moreover, the quantitative results show that our approach achieves superior performance compared with previous works.