 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Detection with Multi-Artifact Subspace Fine-Tuning and Selective Layer Masking
Jan 03, 2026Deepfake detection still faces significant challenges in cross-dataset and real-world complex scenarios. The root cause lies in the high diversity of artifact distributions introduced by different forgery methods, while pretrained models tend to disrupt their original general semantic structures when adapting to new artifacts. Existing approaches usually rely on indiscriminate global parameter updates or introduce additional supervision signals, making it difficult to effectively model diverse forgery artifacts while preserving semantic stability. To address these issues, this paper proposes a deepfake detection method based on Multi-Artifact Subspaces and selective layer masks (MASM), which explicitly decouples semantic representations from artifact representations and constrains the fitting strength of artifact subspaces, thereby improving generalization robustness in cross-dataset scenarios. Specifically, MASM applies singular value decomposition to model weights, partitioning pretrained weights into a stable semantic principal subspace and multiple learnable artifact subspaces. This design enables decoupled modeling of different forgery artifact patterns while preserving the general semantic subspace. On this basis, a selective layer mask strategy is introduced to adaptively regulate the update behavior of corresponding network layers according to the learning state of each artifact subspace, suppressing overfitting to any single forgery characteristic. Furthermore, orthogonality constraints and spectral consistency constraints are imposed to jointly regularize multiple artifact subspaces, guiding them to learn complementary and diverse artifact representations while maintaining a stable overall spectral structure.
DGS-Net: Distillation-Guided Gradient Surgery for CLIP Fine-Tuning in AI-Generated Image Detection
Nov 17, 2025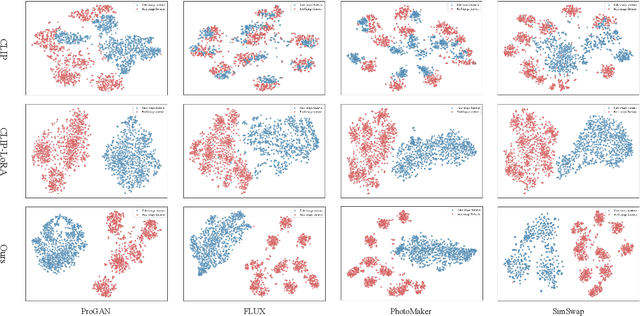
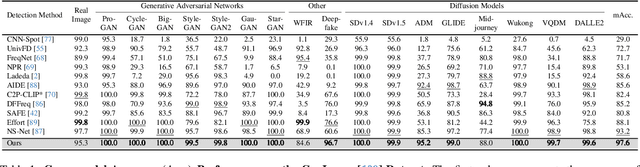
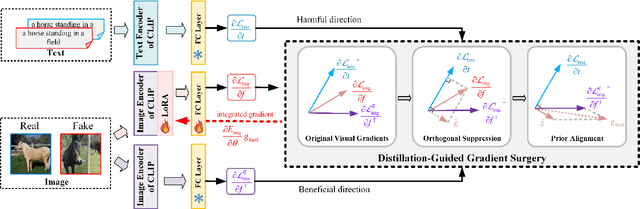
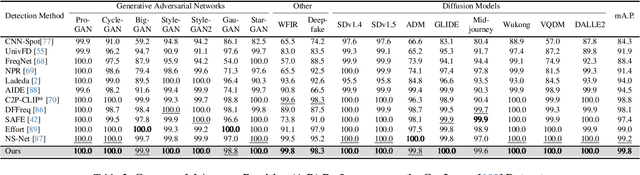
The rapid progress of generative models such as GANs and diffusion models has led to the widespread proliferation of AI-generated images, raising concerns about misinformation, privacy violations, and trust erosion in digital media. Although large-scale multimodal models like CLIP offer strong transferable representations for detecting synthetic content, fine-tuning them often induces catastrophic forgetting, which degrades pre-trained priors and limits cross-domain generalization. To address this issue, we propose the Distillation-guided Gradient Surgery Network (DGS-Net), a novel framework that preserves transferable pre-trained priors while suppressing task-irrelevant components. Specifically, we introduce a gradient-space decomposition that separates harmful and beneficial descent directions during optimization. By projecting task gradients onto the orthogonal complement of harmful directions and aligning with beneficial ones distilled from a frozen CLIP encoder, DGS-Net achieves unified optimization of prior preservation and irrelevant suppression. Extensive experiments on 50 generative models demonstrate that our method outperforms state-of-the-art approaches by an average margin of 6.6, achieving superior detection performance and generalization across diverse generation techniques.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
Is Artificial Intelligence Generated Image Detection a Solved Problem?
May 18, 2025



The rapid advancement of generative models, such as GANs and Diffusion models, has enabled the creation of highly realistic synthetic images, raising serious concerns about misinformation, deepfakes, and copyright infringement. Although numerous Artificial Intelligence Generated Image (AIGI) detectors have been proposed, often reporting high accuracy, their effectiveness in real-world scenarios remains questionable. To bridge this gap, we introduce AIGIBench, a comprehensive benchmark designed to rigorously evaluate the robustness and generalization capabilities of state-of-the-art AIGI detectors. AIGIBench simulates real-world challenges through four core tasks: multi-source generalization, robustness to image degradation, sensitivity to data augmentation, and impact of test-time pre-processing. It includes 23 diverse fake image subsets that span both advanced and widely adopted image generation techniques, along with real-world samples collected from social media and AI art platforms. Extensive experiments on 11 advanced detectors demonstrate that, despite their high reported accuracy in controlled settings, these detectors suffer significant performance drops on real-world data, limited benefits from common augmentations, and nuanced effects of pre-processing, highlighting the need for more robust detection strategies. By providing a unified and realistic evaluation framework, AIGIBench offers valuable insights to guide future research toward dependable and generalizable AIGI detection.
Structuring Multiple Simple Cycle Reservoirs with Particle Swarm Optimization
Apr 06, 2025Reservoir Computing (RC) is a time-efficient computational paradigm derived from Recurrent Neural Networks (RNNs). The Simple Cycle Reservoir (SCR) is an RC model that stands out for its minimalistic design, offering extremely low construction complexity and proven capability of universally approximating time-invariant causal fading memory filters, even in the linear dynamics regime. This paper introduces Multiple Simple Cycle Reservoirs (MSCRs), a multi-reservoir framework that extends Echo State Networks (ESNs) by replacing a single large reservoir with multiple interconnected SCRs. We demonstrate that optimizing MSCR using Particle Swarm Optimization (PSO) outperforms existing multi-reservoir models, achieving competitive predictive performance with a lower-dimensional state space. By modeling interconnections as a weighted Directed Acyclic Graph (DAG), our approach enables flexible, task-specific network topology adaptation. Numerical simulations on three benchmark time-series prediction tasks confirm these advantages over rival algorithms. These findings highlight the potential of MSCR-PSO as a promising framework for optimizing multi-reservoir systems, providing a foundation for further advancements and applications of interconnected SCRs for developing efficient AI devices.
A Comprehensive Survey on Visual Concept Mining in Text-to-image Diffusion Models
Mar 17, 2025Text-to-image diffusion models have made significant advancements in generating high-quality, diverse images from text prompts. However, the inherent limitations of textual signals often prevent these models from fully capturing specific concepts, thereby reducing their controllability. To address this issue, several approaches have incorporated personalization techniques, utilizing reference images to mine visual concept representations that complement textual inputs and enhance the controllability of text-to-image diffusion models. Despite these advances, a comprehensive, systematic exploration of visual concept mining remains limited. In this paper, we categorize existing research into four key areas: Concept Learning, Concept Erasing, Concept Decomposition, and Concept Combination. This classification provides valuable insights into the foundational principles of Visual Concept Mining (VCM) techniques. Additionally, we identify key challenges and propose future research directions to propel this important and interesting field forward.
Proxy-Tuning: Tailoring Multimodal Autoregressive Models for Subject-Driven Image Generation
Mar 13, 2025



Multimodal autoregressive (AR) models, based on next-token prediction and transformer architecture, have demonstrated remarkable capabilities in various multimodal tasks including text-to-image (T2I) generation. Despite their strong performance in general T2I tasks, our research reveals that these models initially struggle with subject-driven image generation compared to dominant diffusion models. To address this limitation, we introduce Proxy-Tuning, leveraging diffusion models to enhance AR models' capabilities in subject-specific image generation. Our method reveals a striking weak-to-strong phenomenon: fine-tuned AR models consistently outperform their diffusion model supervisors in both subject fidelity and prompt adherence. We analyze this performance shift and identify scenarios where AR models excel, particularly in multi-subject compositions and contextual understanding. This work not only demonstrates impressive results in subject-driven AR image generation, but also unveils the potential of weak-to-strong generalization in the image generation domain, contributing to a deeper understanding of different architectures' strengths and limitations.
Generalizable Deepfake Detection via Effective Local-Global Feature Extraction
Jan 25, 2025



The rapid advancement of GANs and diffusion models has led to the generation of increasingly realistic fake images, posing significant hidden dangers and threats to society. Consequently, deepfake detection has become a pressing issue in today's world. While some existing methods focus on forgery features from either a local or global perspective, they often overlook the complementary nature of these features. Other approaches attempt to incorporate both local and global features but rely on simplistic strategies, such as cropping, which fail to capture the intricate relationships between local features. To address these limitations, we propose a novel method that effectively combines local spatial-frequency domain features with global frequency domain information, capturing detailed and holistic forgery traces. Specifically, our method uses Discrete Wavelet Transform (DWT) and sliding windows to tile forged features and leverages attention mechanisms to extract local spatial-frequency domain information. Simultaneously, the phase component of the Fast Fourier Transform (FFT) is integrated with attention mechanisms to extract global frequency domain information, complementing the local features and ensuring the integrity of forgery detection. Comprehensive evaluations on open-world datasets generated by 34 distinct generative models demonstrate a significant improvement of 2.9% over existing state-of-the-art methods.
Follow-Your-MultiPose: Tuning-Free Multi-Character Text-to-Video Generation via Pose Guidance
Dec 21, 2024



Text-editable and pose-controllable character video generation is a challenging but prevailing topic with practical applications. However, existing approaches mainly focus on single-object video generation with pose guidance, ignoring the realistic situation that multi-character appear concurrently in a scenario. To tackle this, we propose a novel multi-character video generation framework in a tuning-free manner, which is based on the separated text and pose guidance. Specifically, we first extract character masks from the pose sequence to identify the spatial position for each generating character, and then single prompts for each character are obtained with LLMs for precise text guidance. Moreover, the spatial-aligned cross attention and multi-branch control module are proposed to generate fine grained controllable multi-character video. The visualized results of generating video demonstrate the precise controllability of our method for multi-character generation. We also verify the generality of our method by applying it to various personalized T2I models. Moreover, the quantitative results show that our approach achieves superior performance compared with previous works.
DAT: Dialogue-Aware Transformer with Modality-Group Fusion for Human Engagement Estimation
Oct 11, 2024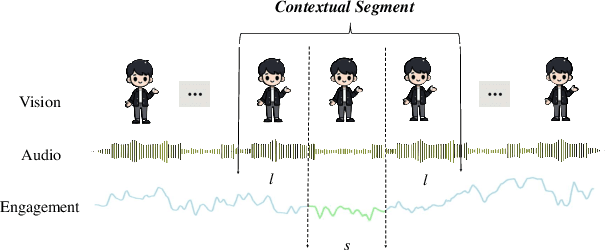
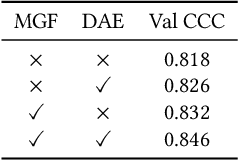
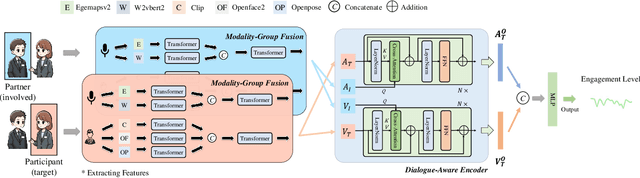

Engagement estimation plays a crucial role in understanding human social behaviors, attracting increasing research interests in fields such as affective computing and human-computer interaction. In this paper, we propose a Dialogue-Aware Transformer framework (DAT) with Modality-Group Fusion (MGF), which relies solely on audio-visual input and is language-independent, for estimating human engagement in conversations. Specifically, our method employs a modality-group fusion strategy that independently fuses audio and visual features within each modality for each person before inferring the entire audio-visual content. This strategy significantly enhances the model's performance and robustness. Additionally, to better estimate the target participant's engagement levels, the introduced Dialogue-Aware Transformer considers both the participant's behavior and cues from their conversational partners. Our method was rigorously tested in the Multi-Domain Engagement Estimation Challenge held by MultiMediate'24, demonstrating notable improvements in engagement-level regression precision over the baseline model. Notably, our approach achieves a CCC score of 0.76 on the NoXi Base test set and an average CCC of 0.64 across the NoXi Base, NoXi-Add, and MPIIGI test sets.