 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
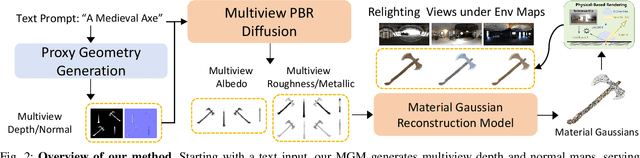
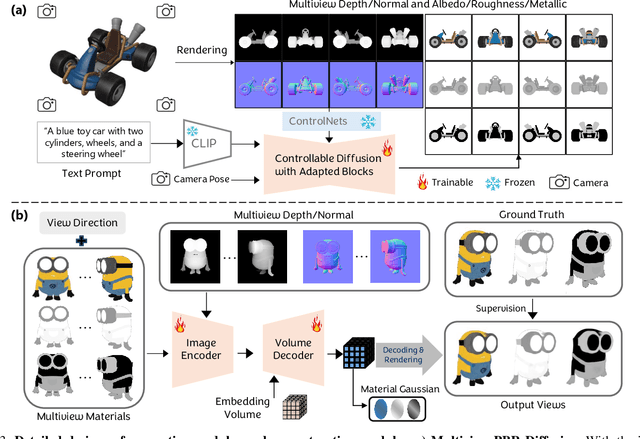

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
AssetDropper: Asset Extraction via Diffusion Models with Reward-Driven Optimization
Jun 06, 2025Recent research on generative models has primarily focused on creating product-ready visual outputs; however, designers often favor access to standardized asset libraries, a domain that has yet to be significantly enhanced by generative capabilities. Although open-world scenes provide ample raw materials for designers, efficiently extracting high-quality, standardized assets remains a challenge. To address this, we introduce AssetDropper, the first framework designed to extract assets from reference images, providing artists with an open-world asset palette. Our model adeptly extracts a front view of selected subjects from input images, effectively handling complex scenarios such as perspective distortion and subject occlusion. We establish a synthetic dataset of more than 200,000 image-subject pairs and a real-world benchmark with thousands more for evaluation, facilitating the exploration of future research in downstream tasks. Furthermore, to ensure precise asset extraction that aligns well with the image prompts, we employ a pre-trained reward model to fulfill a closed-loop with feedback. We design the reward model to perform an inverse task that pastes the extracted assets back into the reference sources, which assists training with additional consistency and mitigates hallucination. Extensive experiments show that, with the aid of reward-driven optimization, AssetDropper achieves the state-of-the-art results in asset extraction. Project page: AssetDropper.github.io.
StyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
May 26, 2025
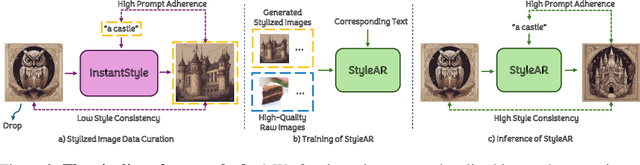

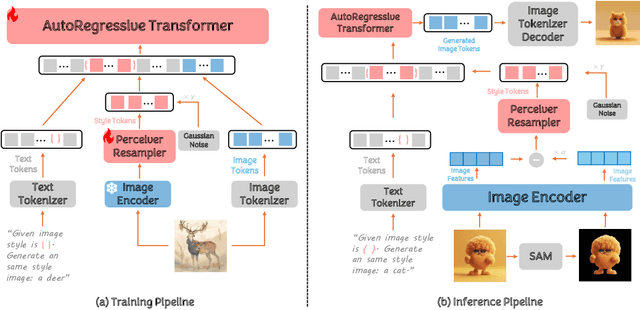
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.
DanceGRPO: Unleashing GRPO on Visual Generation
May 12, 2025
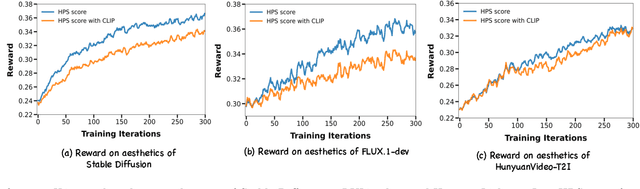
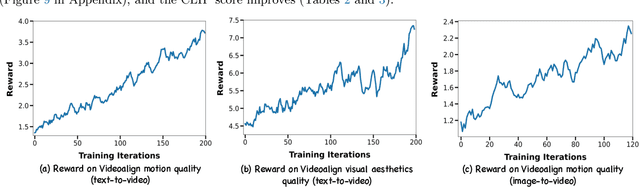

Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
GarmentX: Autoregressive Parametric Representations for High-Fidelity 3D Garment Generation
Apr 29, 2025This work presents GarmentX, a novel framework for generating diverse, high-fidelity, and wearable 3D garments from a single input image. Traditional garment reconstruction methods directly predict 2D pattern edges and their connectivity, an overly unconstrained approach that often leads to severe self-intersections and physically implausible garment structures. In contrast, GarmentX introduces a structured and editable parametric representation compatible with GarmentCode, ensuring that the decoded sewing patterns always form valid, simulation-ready 3D garments while allowing for intuitive modifications of garment shape and style. To achieve this, we employ a masked autoregressive model that sequentially predicts garment parameters, leveraging autoregressive modeling for structured generation while mitigating inconsistencies in direct pattern prediction. Additionally, we introduce GarmentX dataset, a large-scale dataset of 378,682 garment parameter-image pairs, constructed through an automatic data generation pipeline that synthesizes diverse and high-quality garment images conditioned on parametric garment representations. Through integrating our method with GarmentX dataset, we achieve state-of-the-art performance in geometric fidelity and input image alignment, significantly outperforming prior approaches. We will release GarmentX dataset upon publication.
MAR-3D: Progressive Masked Auto-regressor for High-Resolution 3D Generation
Mar 27, 2025Recent advances in auto-regressive transformers have revolutionized generative modeling across different domains, from language processing to visual generation, demonstrating remarkable capabilities. However, applying these advances to 3D generation presents three key challenges: the unordered nature of 3D data conflicts with sequential next-token prediction paradigm, conventional vector quantization approaches incur substantial compression loss when applied to 3D meshes, and the lack of efficient scaling strategies for higher resolution latent prediction. To address these challenges, we introduce MAR-3D, which integrates a pyramid variational autoencoder with a cascaded masked auto-regressive transformer (Cascaded MAR) for progressive latent upscaling in the continuous space. Our architecture employs random masking during training and auto-regressive denoising in random order during inference, naturally accommodating the unordered property of 3D latent tokens. Additionally, we propose a cascaded training strategy with condition augmentation that enables efficiently up-scale the latent token resolution with fast convergence. Extensive experiments demonstrate that MAR-3D not only achieves superior performance and generalization capabilities compared to existing methods but also exhibits enhanced scaling capabilities compared to joint distribution modeling approaches (e.g., diffusion transformers).
Proxy-Tuning: Tailoring Multimodal Autoregressive Models for Subject-Driven Image Generation
Mar 13, 2025



Multimodal autoregressive (AR) models, based on next-token prediction and transformer architecture, have demonstrated remarkable capabilities in various multimodal tasks including text-to-image (T2I) generation. Despite their strong performance in general T2I tasks, our research reveals that these models initially struggle with subject-driven image generation compared to dominant diffusion models. To address this limitation, we introduce Proxy-Tuning, leveraging diffusion models to enhance AR models' capabilities in subject-specific image generation. Our method reveals a striking weak-to-strong phenomenon: fine-tuned AR models consistently outperform their diffusion model supervisors in both subject fidelity and prompt adherence. We analyze this performance shift and identify scenarios where AR models excel, particularly in multi-subject compositions and contextual understanding. This work not only demonstrates impressive results in subject-driven AR image generation, but also unveils the potential of weak-to-strong generalization in the image generation domain, contributing to a deeper understanding of different architectures' strengths and limitations.
Large Images are Gaussians: High-Quality Large Image Representation with Levels of 2D Gaussian Splatting
Feb 13, 2025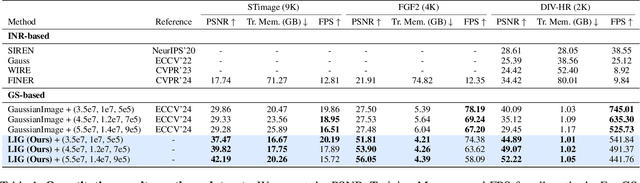
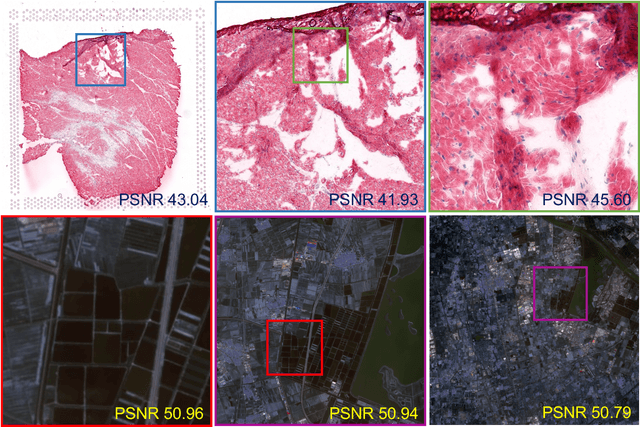
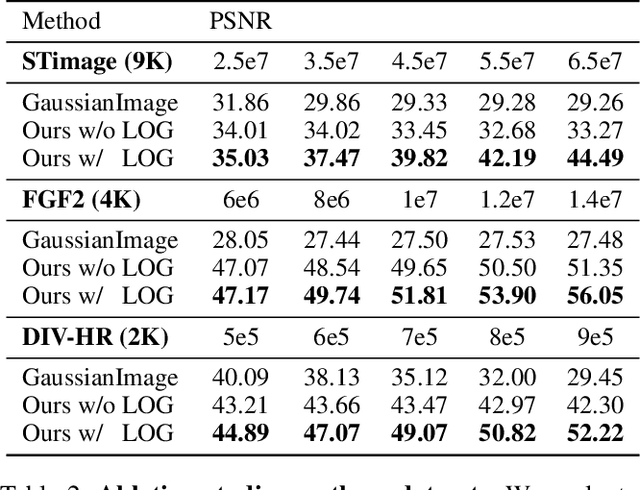
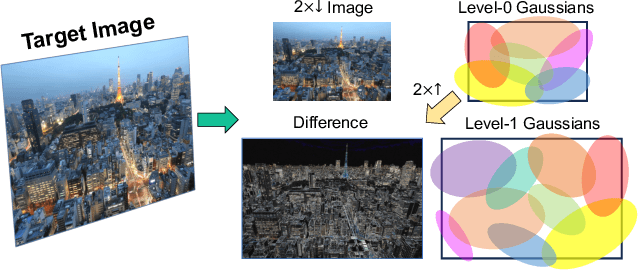
While Implicit Neural Representations (INRs) have demonstrated significant success in image representation, they are often hindered by large training memory and slow decoding speed. Recently, Gaussian Splatting (GS) has emerged as a promising solution in 3D reconstruction due to its high-quality novel view synthesis and rapid rendering capabilities, positioning it as a valuable tool for a broad spectrum of applications. In particular, a GS-based representation, 2DGS, has shown potential for image fitting. In our work, we present \textbf{L}arge \textbf{I}mages are \textbf{G}aussians (\textbf{LIG}), which delves deeper into the application of 2DGS for image representations, addressing the challenge of fitting large images with 2DGS in the situation of numerous Gaussian points, through two distinct modifications: 1) we adopt a variant of representation and optimization strategy, facilitating the fitting of a large number of Gaussian points; 2) we propose a Level-of-Gaussian approach for reconstructing both coarse low-frequency initialization and fine high-frequency details. Consequently, we successfully represent large images as Gaussian points and achieve high-quality large image representation, demonstrating its efficacy across various types of large images. Code is available at {\href{https://github.com/HKU-MedAI/LIG}{https://github.com/HKU-MedAI/LIG}}.
AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance
Feb 12, 2025Character video generation is a significant real-world application focused on producing high-quality videos featuring specific characters. Recent advancements have introduced various control signals to animate static characters, successfully enhancing control over the generation process. However, these methods often lack flexibility, limiting their applicability and making it challenging for users to synthesize a source character into a desired target scene. To address this issue, we propose a novel framework, AnyCharV, that flexibly generates character videos using arbitrary source characters and target scenes, guided by pose information. Our approach involves a two-stage training process. In the first stage, we develop a base model capable of integrating the source character with the target scene using pose guidance. The second stage further bootstraps controllable generation through a self-boosting mechanism, where we use the generated video in the first stage and replace the fine mask with the coarse one, enabling training outcomes with better preservation of character details. Experimental results demonstrate the effectiveness and robustness of our proposed method. Our project page is https://anycharv.github.io.
ToolBridge: An Open-Source Dataset to Equip LLMs with External Tool Capabilities
Oct 08, 2024

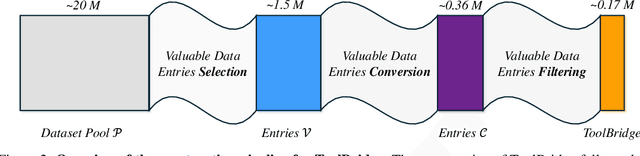

Through the integration of external tools, large language models (LLMs) such as GPT-4o and Llama 3.1 significantly expand their functional capabilities, evolving from elementary conversational agents to general-purpose assistants. We argue that the primary drivers of these advancements are the quality and diversity of the training data. However, the existing LLMs with external tool integration provide only limited transparency regarding their datasets and data collection methods, which has led to the initiation of this research. Specifically, in this paper, our objective is to elucidate the detailed process involved in constructing datasets that empower LLMs to effectively learn how to utilize external tools and make this information available to the public through the introduction of ToolBridge. ToolBridge proposes to employ a collection of general open-access datasets as its raw dataset pool and applies a series of strategies to identify appropriate data entries from the pool for external tool API insertions. By supervised fine-tuning on these curated data entries, LLMs can invoke external tools in appropriate contexts to boost their predictive accuracy, particularly for basic functions including data processing, numerical computation, and factual retrieval. Our experiments rigorously isolates model architectures and training configurations, focusing exclusively on the role of data. The experimental results indicate that LLMs trained on ToolBridge demonstrate consistent performance improvements on both standard benchmarks and custom evaluation datasets. All the associated code and data will be open-source at https://github.com/CharlesPikachu/ToolBridge, promoting transparency and facilitating the broader community to explore approaches for equipping LLMs with external tools capabilities.