 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDMM-LM: Bridging Facial Understanding and Animation via Language Models
Mar 14, 2026Text-guided human body animation has advanced rapidly, yet facial animation lags due to the scarcity of well-annotated, text-paired facial corpora. To close this gap, we leverage foundation generative models to synthesize a large, balanced corpus of facial behavior. We design prompts suite covering emotions and head motions, generate about 80 hours of facial videos with multiple generators, and fit per-frame 3D facial parameters, yielding large-scale (prompt and parameter) pairs for training. Building on this dataset, we probe language models for bidirectional competence over facial motion via two complementary tasks: (1) Motion2Language: given a sequence of 3D facial parameters, the model produces natural-language descriptions capturing content, style, and dynamics; and (2) Language2Motion: given a prompt, the model synthesizes the corresponding sequence of 3D facial parameters via quantized motion tokens for downstream animation. Extensive experiments show that in this setting language models can both interpret and synthesize facial motion with strong generalization. To best of our knowledge, this is the first work to cast facial-parameter modeling as a language problem, establishing a unified path for text-conditioned facial animation and motion understanding.
AssetFormer: Modular 3D Assets Generation with Autoregressive Transformer
Feb 12, 2026The digital industry demands high-quality, diverse modular 3D assets, especially for user-generated content~(UGC). In this work, we introduce AssetFormer, an autoregressive Transformer-based model designed to generate modular 3D assets from textual descriptions. Our pilot study leverages real-world modular assets collected from online platforms. AssetFormer tackles the challenge of creating assets composed of primitives that adhere to constrained design parameters for various applications. By innovatively adapting module sequencing and decoding techniques inspired by language models, our approach enhances asset generation quality through autoregressive modeling. Initial results indicate the effectiveness of AssetFormer in streamlining asset creation for professional development and UGC scenarios. This work presents a flexible framework extendable to various types of modular 3D assets, contributing to the broader field of 3D content generation. The code is available at https://github.com/Advocate99/AssetFormer.
MAFE R-CNN: Selecting More Samples to Learn Category-aware Features for Small Object Detection
May 22, 2025Small object detection in intricate environments has consistently represented a major challenge in the field of object detection. In this paper, we identify that this difficulty stems from the detectors' inability to effectively learn discriminative features for objects of small size, compounded by the complexity of selecting high-quality small object samples during training, which motivates the proposal of the Multi-Clue Assignment and Feature Enhancement R-CNN.Specifically, MAFE R-CNN integrates two pivotal components.The first is the Multi-Clue Sample Selection (MCSS) strategy, in which the Intersection over Union (IoU) distance, predicted category confidence, and ground truth region sizes are leveraged as informative clues in the sample selection process. This methodology facilitates the selection of diverse positive samples and ensures a balanced distribution of object sizes during training, thereby promoting effective model learning.The second is the Category-aware Feature Enhancement Mechanism (CFEM), where we propose a simple yet effective category-aware memory module to explore the relationships among object features. Subsequently, we enhance the object feature representation by facilitating the interaction between category-aware features and candidate box features.Comprehensive experiments conducted on the large-scale small object dataset SODA validate the effectiveness of the proposed method. The code will be made publicly available.
Large Images are Gaussians: High-Quality Large Image Representation with Levels of 2D Gaussian Splatting
Feb 13, 2025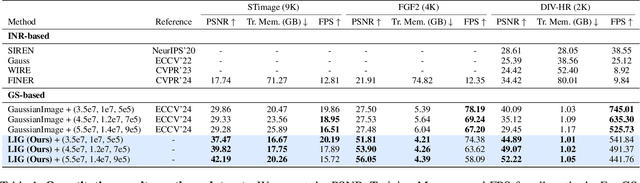
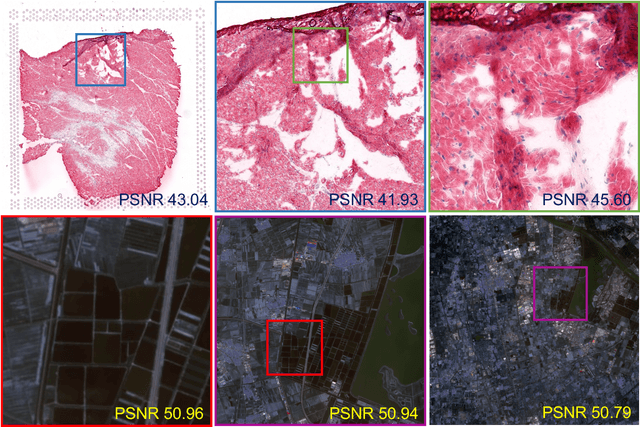
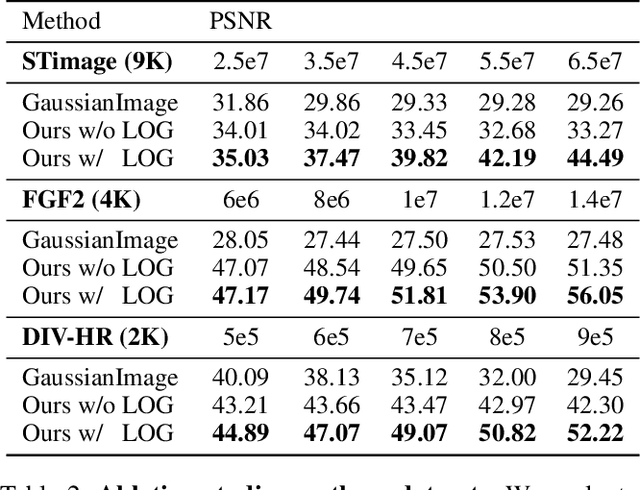
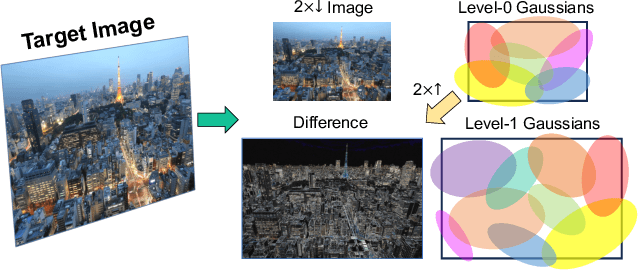
While Implicit Neural Representations (INRs) have demonstrated significant success in image representation, they are often hindered by large training memory and slow decoding speed. Recently, Gaussian Splatting (GS) has emerged as a promising solution in 3D reconstruction due to its high-quality novel view synthesis and rapid rendering capabilities, positioning it as a valuable tool for a broad spectrum of applications. In particular, a GS-based representation, 2DGS, has shown potential for image fitting. In our work, we present \textbf{L}arge \textbf{I}mages are \textbf{G}aussians (\textbf{LIG}), which delves deeper into the application of 2DGS for image representations, addressing the challenge of fitting large images with 2DGS in the situation of numerous Gaussian points, through two distinct modifications: 1) we adopt a variant of representation and optimization strategy, facilitating the fitting of a large number of Gaussian points; 2) we propose a Level-of-Gaussian approach for reconstructing both coarse low-frequency initialization and fine high-frequency details. Consequently, we successfully represent large images as Gaussian points and achieve high-quality large image representation, demonstrating its efficacy across various types of large images. Code is available at {\href{https://github.com/HKU-MedAI/LIG}{https://github.com/HKU-MedAI/LIG}}.
ToolBridge: An Open-Source Dataset to Equip LLMs with External Tool Capabilities
Oct 08, 2024

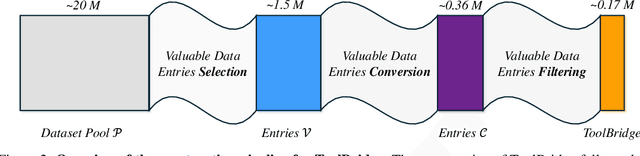

Through the integration of external tools, large language models (LLMs) such as GPT-4o and Llama 3.1 significantly expand their functional capabilities, evolving from elementary conversational agents to general-purpose assistants. We argue that the primary drivers of these advancements are the quality and diversity of the training data. However, the existing LLMs with external tool integration provide only limited transparency regarding their datasets and data collection methods, which has led to the initiation of this research. Specifically, in this paper, our objective is to elucidate the detailed process involved in constructing datasets that empower LLMs to effectively learn how to utilize external tools and make this information available to the public through the introduction of ToolBridge. ToolBridge proposes to employ a collection of general open-access datasets as its raw dataset pool and applies a series of strategies to identify appropriate data entries from the pool for external tool API insertions. By supervised fine-tuning on these curated data entries, LLMs can invoke external tools in appropriate contexts to boost their predictive accuracy, particularly for basic functions including data processing, numerical computation, and factual retrieval. Our experiments rigorously isolates model architectures and training configurations, focusing exclusively on the role of data. The experimental results indicate that LLMs trained on ToolBridge demonstrate consistent performance improvements on both standard benchmarks and custom evaluation datasets. All the associated code and data will be open-source at https://github.com/CharlesPikachu/ToolBridge, promoting transparency and facilitating the broader community to explore approaches for equipping LLMs with external tools capabilities.
Mixture-of-Noises Enhanced Forgery-Aware Predictor for Multi-Face Manipulation Detection and Localization
Aug 05, 2024



With the advancement of face manipulation technology, forgery images in multi-face scenarios are gradually becoming a more complex and realistic challenge. Despite this, detection and localization methods for such multi-face manipulations remain underdeveloped. Traditional manipulation localization methods either indirectly derive detection results from localization masks, resulting in limited detection performance, or employ a naive two-branch structure to simultaneously obtain detection and localization results, which cannot effectively benefit the localization capability due to limited interaction between two tasks. This paper proposes a new framework, namely MoNFAP, specifically tailored for multi-face manipulation detection and localization. The MoNFAP primarily introduces two novel modules: the Forgery-aware Unified Predictor (FUP) Module and the Mixture-of-Noises Module (MNM). The FUP integrates detection and localization tasks using a token learning strategy and multiple forgery-aware transformers, which facilitates the use of classification information to enhance localization capability. Besides, motivated by the crucial role of noise information in forgery detection, the MNM leverages multiple noise extractors based on the concept of the mixture of experts to enhance the general RGB features, further boosting the performance of our framework. Finally, we establish a comprehensive benchmark for multi-face detection and localization and the proposed \textit{MoNFAP} achieves significant performance. The codes will be made available.
Generative Enhancement for 3D Medical Images
Mar 19, 2024



The limited availability of 3D medical image datasets, due to privacy concerns and high collection or annotation costs, poses significant challenges in the field of medical imaging. While a promising alternative is the use of synthesized medical data, there are few solutions for realistic 3D medical image synthesis due to difficulties in backbone design and fewer 3D training samples compared to 2D counterparts. In this paper, we propose GEM-3D, a novel generative approach to the synthesis of 3D medical images and the enhancement of existing datasets using conditional diffusion models. Our method begins with a 2D slice, noted as the informed slice to serve the patient prior, and propagates the generation process using a 3D segmentation mask. By decomposing the 3D medical images into masks and patient prior information, GEM-3D offers a flexible yet effective solution for generating versatile 3D images from existing datasets. GEM-3D can enable dataset enhancement by combining informed slice selection and generation at random positions, along with editable mask volumes to introduce large variations in diffusion sampling. Moreover, as the informed slice contains patient-wise information, GEM-3D can also facilitate counterfactual image synthesis and dataset-level de-enhancement with desired control. Experiments on brain MRI and abdomen CT images demonstrate that GEM-3D is capable of synthesizing high-quality 3D medical images with volumetric consistency, offering a straightforward solution for dataset enhancement during inference. The code is available at https://github.com/HKU-MedAI/GEM-3D.
Deformable Endoscopic Tissues Reconstruction with Gaussian Splatting
Jan 21, 2024Surgical 3D reconstruction is a critical area of research in robotic surgery, with recent works adopting variants of dynamic radiance fields to achieve success in 3D reconstruction of deformable tissues from single-viewpoint videos. However, these methods often suffer from time-consuming optimization or inferior quality, limiting their adoption in downstream tasks. Inspired by 3D Gaussian Splatting, a recent trending 3D representation, we present EndoGS, applying Gaussian Splatting for deformable endoscopic tissue reconstruction. Specifically, our approach incorporates deformation fields to handle dynamic scenes, depth-guided supervision to optimize 3D targets with a single viewpoint, and a spatial-temporal weight mask to mitigate tool occlusion. As a result, EndoGS reconstructs and renders high-quality deformable endoscopic tissues from a single-viewpoint video, estimated depth maps, and labeled tool masks. Experiments on DaVinci robotic surgery videos demonstrate that EndoGS achieves superior rendering quality. Code is available at https://github.com/HKU-MedAI/EndoGS.
IDRNet: Intervention-Driven Relation Network for Semantic Segmentation
Oct 16, 2023
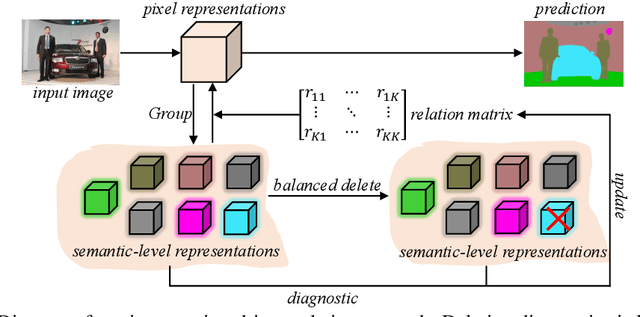
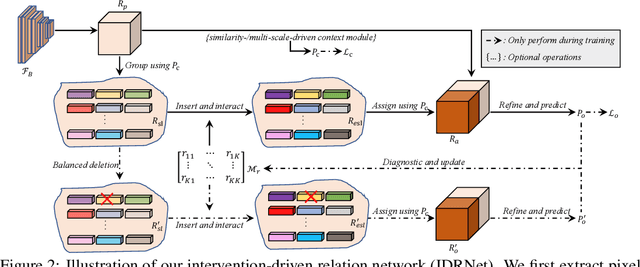
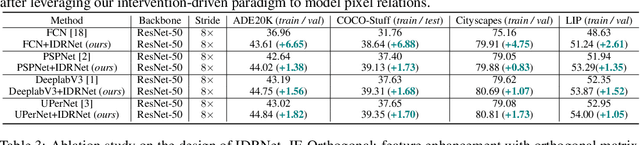
Co-occurrent visual patterns suggest that pixel relation modeling facilitates dense prediction tasks, which inspires the development of numerous context modeling paradigms, \emph{e.g.}, multi-scale-driven and similarity-driven context schemes. Despite the impressive results, these existing paradigms often suffer from inadequate or ineffective contextual information aggregation due to reliance on large amounts of predetermined priors. To alleviate the issues, we propose a novel \textbf{I}ntervention-\textbf{D}riven \textbf{R}elation \textbf{Net}work (\textbf{IDRNet}), which leverages a deletion diagnostics procedure to guide the modeling of contextual relations among different pixels. Specifically, we first group pixel-level representations into semantic-level representations with the guidance of pseudo labels and further improve the distinguishability of the grouped representations with a feature enhancement module. Next, a deletion diagnostics procedure is conducted to model relations of these semantic-level representations via perceiving the network outputs and the extracted relations are utilized to guide the semantic-level representations to interact with each other. Finally, the interacted representations are utilized to augment original pixel-level representations for final predictions. Extensive experiments are conducted to validate the effectiveness of IDRNet quantitatively and qualitatively. Notably, our intervention-driven context scheme brings consistent performance improvements to state-of-the-art segmentation frameworks and achieves competitive results on popular benchmark datasets, including ADE20K, COCO-Stuff, PASCAL-Context, LIP, and Cityscapes. Code is available at \url{https://github.com/SegmentationBLWX/sssegmentation}.
Emotional Listener Portrait: Neural Listener Head Generation with Emotion
Oct 08, 2023Listener head generation centers on generating non-verbal behaviors (e.g., smile) of a listener in reference to the information delivered by a speaker. A significant challenge when generating such responses is the non-deterministic nature of fine-grained facial expressions during a conversation, which varies depending on the emotions and attitudes of both the speaker and the listener. To tackle this problem, we propose the Emotional Listener Portrait (ELP), which treats each fine-grained facial motion as a composition of several discrete motion-codewords and explicitly models the probability distribution of the motions under different emotion in conversation. Benefiting from the ``explicit'' and ``discrete'' design, our ELP model can not only automatically generate natural and diverse responses toward a given speaker via sampling from the learned distribution but also generate controllable responses with a predetermined attitude. Under several quantitative metrics, our ELP exhibits significant improvements compared to previous methods.