 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025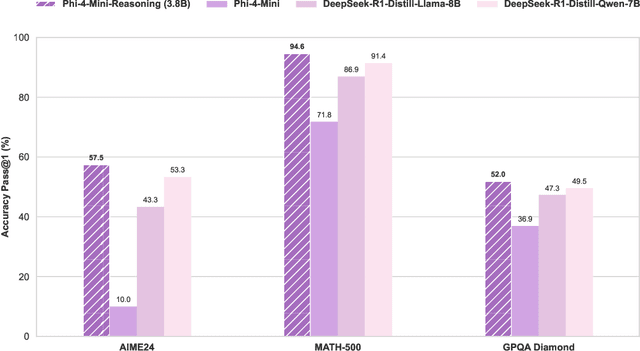
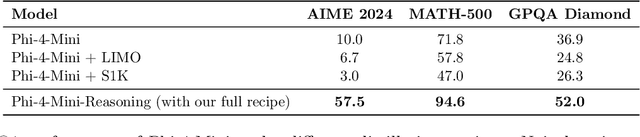

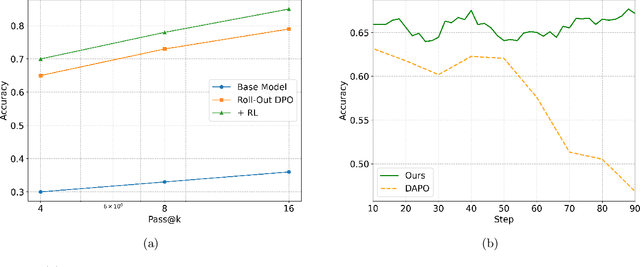
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Show and Segment: Universal Medical Image Segmentation via In-Context Learning
Mar 25, 2025Medical image segmentation remains challenging due to the vast diversity of anatomical structures, imaging modalities, and segmentation tasks. While deep learning has made significant advances, current approaches struggle to generalize as they require task-specific training or fine-tuning on unseen classes. We present Iris, a novel In-context Reference Image guided Segmentation framework that enables flexible adaptation to novel tasks through the use of reference examples without fine-tuning. At its core, Iris features a lightweight context task encoding module that distills task-specific information from reference context image-label pairs. This rich context embedding information is used to guide the segmentation of target objects. By decoupling task encoding from inference, Iris supports diverse strategies from one-shot inference and context example ensemble to object-level context example retrieval and in-context tuning. Through comprehensive evaluation across twelve datasets, we demonstrate that Iris performs strongly compared to task-specific models on in-distribution tasks. On seven held-out datasets, Iris shows superior generalization to out-of-distribution data and unseen classes. Further, Iris's task encoding module can automatically discover anatomical relationships across datasets and modalities, offering insights into medical objects without explicit anatomical supervision.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Benchmarking Large and Small MLLMs
Jan 04, 2025



Large multimodal language models (MLLMs) such as GPT-4V and GPT-4o have achieved remarkable advancements in understanding and generating multimodal content, showcasing superior quality and capabilities across diverse tasks. However, their deployment faces significant challenges, including slow inference, high computational cost, and impracticality for on-device applications. In contrast, the emergence of small MLLMs, exemplified by the LLava-series models and Phi-3-Vision, offers promising alternatives with faster inference, reduced deployment costs, and the ability to handle domain-specific scenarios. Despite their growing presence, the capability boundaries between large and small MLLMs remain underexplored. In this work, we conduct a systematic and comprehensive evaluation to benchmark both small and large MLLMs, spanning general capabilities such as object recognition, temporal reasoning, and multimodal comprehension, as well as real-world applications in domains like industry and automotive. Our evaluation reveals that small MLLMs can achieve comparable performance to large models in specific scenarios but lag significantly in complex tasks requiring deeper reasoning or nuanced understanding. Furthermore, we identify common failure cases in both small and large MLLMs, highlighting domains where even state-of-the-art models struggle. We hope our findings will guide the research community in pushing the quality boundaries of MLLMs, advancing their usability and effectiveness across diverse applications.
Olympus: A Universal Task Router for Computer Vision Tasks
Dec 12, 2024We introduce Olympus, a new approach that transforms Multimodal Large Language Models (MLLMs) into a unified framework capable of handling a wide array of computer vision tasks. Utilizing a controller MLLM, Olympus delegates over 20 specialized tasks across images, videos, and 3D objects to dedicated modules. This instruction-based routing enables complex workflows through chained actions without the need for training heavy generative models. Olympus easily integrates with existing MLLMs, expanding their capabilities with comparable performance. Experimental results demonstrate that Olympus achieves an average routing accuracy of 94.75% across 20 tasks and precision of 91.82% in chained action scenarios, showcasing its effectiveness as a universal task router that can solve a diverse range of computer vision tasks. Project page: https://github.com/yuanze-lin/Olympus_page
ToolBridge: An Open-Source Dataset to Equip LLMs with External Tool Capabilities
Oct 08, 2024

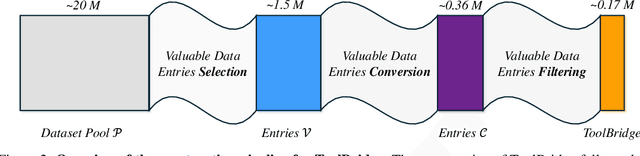

Through the integration of external tools, large language models (LLMs) such as GPT-4o and Llama 3.1 significantly expand their functional capabilities, evolving from elementary conversational agents to general-purpose assistants. We argue that the primary drivers of these advancements are the quality and diversity of the training data. However, the existing LLMs with external tool integration provide only limited transparency regarding their datasets and data collection methods, which has led to the initiation of this research. Specifically, in this paper, our objective is to elucidate the detailed process involved in constructing datasets that empower LLMs to effectively learn how to utilize external tools and make this information available to the public through the introduction of ToolBridge. ToolBridge proposes to employ a collection of general open-access datasets as its raw dataset pool and applies a series of strategies to identify appropriate data entries from the pool for external tool API insertions. By supervised fine-tuning on these curated data entries, LLMs can invoke external tools in appropriate contexts to boost their predictive accuracy, particularly for basic functions including data processing, numerical computation, and factual retrieval. Our experiments rigorously isolates model architectures and training configurations, focusing exclusively on the role of data. The experimental results indicate that LLMs trained on ToolBridge demonstrate consistent performance improvements on both standard benchmarks and custom evaluation datasets. All the associated code and data will be open-source at https://github.com/CharlesPikachu/ToolBridge, promoting transparency and facilitating the broader community to explore approaches for equipping LLMs with external tools capabilities.
SynChart: Synthesizing Charts from Language Models
Sep 25, 2024With the release of GPT-4V(O), its use in generating pseudo labels for multi-modality tasks has gained significant popularity. However, it is still a secret how to build such advanced models from its base large language models (LLMs). This work explores the potential of using LLMs alone for data generation and develop competitive multi-modality models focusing on chart understanding. We construct a large-scale chart dataset, SynChart, which contains approximately 4 million diverse chart images with over 75 million dense annotations, including data tables, code, descriptions, and question-answer sets. We trained a 4.2B chart-expert model using this dataset and achieve near-GPT-4O performance on the ChartQA task, surpassing GPT-4V.
Pluralistic Salient Object Detection
Sep 04, 2024



We introduce pluralistic salient object detection (PSOD), a novel task aimed at generating multiple plausible salient segmentation results for a given input image. Unlike conventional SOD methods that produce a single segmentation mask for salient objects, this new setting recognizes the inherent complexity of real-world images, comprising multiple objects, and the ambiguity in defining salient objects due to different user intentions. To study this task, we present two new SOD datasets "DUTS-MM" and "DUS-MQ", along with newly designed evaluation metrics. DUTS-MM builds upon the DUTS dataset but enriches the ground-truth mask annotations from three aspects which 1) improves the mask quality especially for boundary and fine-grained structures; 2) alleviates the annotation inconsistency issue; and 3) provides multiple ground-truth masks for images with saliency ambiguity. DUTS-MQ consists of approximately 100K image-mask pairs with human-annotated preference scores, enabling the learning of real human preferences in measuring mask quality. Building upon these two datasets, we propose a simple yet effective pluralistic SOD baseline based on a Mixture-of-Experts (MOE) design. Equipped with two prediction heads, it simultaneously predicts multiple masks using different query prompts and predicts human preference scores for each mask candidate. Extensive experiments and analyses underscore the significance of our proposed datasets and affirm the effectiveness of our PSOD framework.
Rethinking Visual Prompting for Multimodal Large Language Models with External Knowledge
Jul 05, 2024In recent years, multimodal large language models (MLLMs) have made significant strides by training on vast high-quality image-text datasets, enabling them to generally understand images well. However, the inherent difficulty in explicitly conveying fine-grained or spatially dense information in text, such as masks, poses a challenge for MLLMs, limiting their ability to answer questions requiring an understanding of detailed or localized visual elements. Drawing inspiration from the Retrieval-Augmented Generation (RAG) concept, this paper proposes a new visual prompt approach to integrate fine-grained external knowledge, gleaned from specialized vision models (e.g., instance segmentation/OCR models), into MLLMs. This is a promising yet underexplored direction for enhancing MLLMs' performance. Our approach diverges from concurrent works, which transform external knowledge into additional text prompts, necessitating the model to indirectly learn the correspondence between visual content and text coordinates. Instead, we propose embedding fine-grained knowledge information directly into a spatial embedding map as a visual prompt. This design can be effortlessly incorporated into various MLLMs, such as LLaVA and Mipha, considerably improving their visual understanding performance. Through rigorous experiments, we demonstrate that our method can enhance MLLM performance across nine benchmarks, amplifying their fine-grained context-aware capabilities.
SCHEME: Scalable Channer Mixer for Vision Transformers
Dec 01, 2023Vision Transformers have received significant attention due to their impressive performance in many vision tasks. While the token mixer or attention block has been studied in great detail, the channel mixer or feature mixing block (FFN or MLP) has not been explored in depth albeit it accounts for a bulk of the parameters and computation in a model. In this work, we study whether sparse feature mixing can replace the dense connections and confirm this with a block diagonal MLP structure that improves the accuracy by supporting larger expansion ratios. To improve the feature clusters formed by this structure and thereby further improve the accuracy, a lightweight, parameter-free, channel covariance attention (CCA) mechanism is introduced as a parallel branch during training. This design of CCA enables gradual feature mixing across channel groups during training whose contribution decays to zero as the training progresses to convergence. This allows the CCA block to be discarded during inference, thus enabling enhanced performance with no additional computational cost. The resulting $\textit{Scalable CHannEl MixEr}$ (SCHEME) can be plugged into any ViT architecture to obtain a gamut of models with different trade-offs between complexity and performance by controlling the block diagonal structure size in the MLP. This is shown by the introduction of a new family of SCHEMEformer models. Experiments on image classification, object detection, and semantic segmentation, with different ViT backbones, consistently demonstrate substantial accuracy gains over existing designs, especially under lower FLOPs regimes. For example, the SCHEMEformer establishes a new SOTA of 79.7% accuracy for ViTs using pure attention mixers on ImageNet-1K at 1.77G FLOPs.