 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Diffusion Models for Improved Prompt Compliance and Controllable Image Synthesis
Oct 29, 2024Recent advances in generative modeling with diffusion processes (DPs) enabled breakthroughs in image synthesis. Despite impressive image quality, these models have various prompt compliance problems, including low recall in generating multiple objects, difficulty in generating text in images, and meeting constraints like object locations and pose. For fine-grained editing and manipulation, they also require fine-grained semantic or instance maps that are tedious to produce manually. While prompt compliance can be enhanced by addition of loss functions at inference, this is time consuming and does not scale to complex scenes. To overcome these limitations, this work introduces a new family of \textit{Factor Graph Diffusion Models} (FG-DMs) that models the joint distribution of images and conditioning variables, such as semantic, sketch, depth or normal maps via a factor graph decomposition. This joint structure has several advantages, including support for efficient sampling based prompt compliance schemes, which produce images of high object recall, semi-automated fine-grained editing, text-based editing of conditions with noise inversion, explainability at intermediate levels, ability to produce labeled datasets for the training of downstream models such as segmentation or depth, training with missing data, and continual learning where new conditioning variables can be added with minimal or no modifications to the existing structure. We propose an implementation of FG-DMs by adapting a pre-trained Stable Diffusion (SD) model to implement all FG-DM factors, using only COCO dataset, and show that it is effective in generating images with 15\% higher recall than SD while retaining its generalization ability. We introduce an attention distillation loss that encourages consistency among the attention maps of all factors, improving the fidelity of the generated conditions and image.
Prompt Sliders for Fine-Grained Control, Editing and Erasing of Concepts in Diffusion Models
Sep 25, 2024


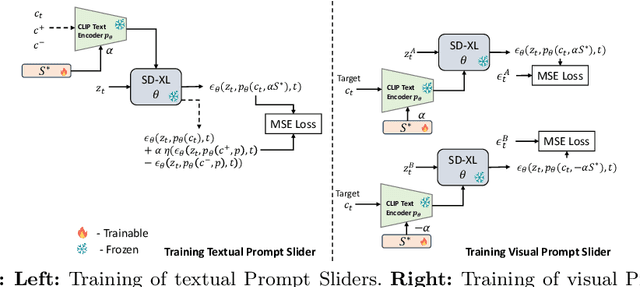
Diffusion models have recently surpassed GANs in image synthesis and editing, offering superior image quality and diversity. However, achieving precise control over attributes in generated images remains a challenge. Concept Sliders introduced a method for fine-grained image control and editing by learning concepts (attributes/objects). However, this approach adds parameters and increases inference time due to the loading and unloading of Low-Rank Adapters (LoRAs) used for learning concepts. These adapters are model-specific and require retraining for different architectures, such as Stable Diffusion (SD) v1.5 and SD-XL. In this paper, we propose a straightforward textual inversion method to learn concepts through text embeddings, which are generalizable across models that share the same text encoder, including different versions of the SD model. We refer to our method as Prompt Sliders. Besides learning new concepts, we also show that Prompt Sliders can be used to erase undesirable concepts such as artistic styles or mature content. Our method is 30% faster than using LoRAs because it eliminates the need to load and unload adapters and introduces no additional parameters aside from the target concept text embedding. Each concept embedding only requires 3KB of storage compared to the 8922KB or more required for each LoRA adapter, making our approach more computationally efficient. Project Page: https://deepaksridhar.github.io/promptsliders.github.io/
SCHEME: Scalable Channer Mixer for Vision Transformers
Dec 01, 2023Vision Transformers have received significant attention due to their impressive performance in many vision tasks. While the token mixer or attention block has been studied in great detail, the channel mixer or feature mixing block (FFN or MLP) has not been explored in depth albeit it accounts for a bulk of the parameters and computation in a model. In this work, we study whether sparse feature mixing can replace the dense connections and confirm this with a block diagonal MLP structure that improves the accuracy by supporting larger expansion ratios. To improve the feature clusters formed by this structure and thereby further improve the accuracy, a lightweight, parameter-free, channel covariance attention (CCA) mechanism is introduced as a parallel branch during training. This design of CCA enables gradual feature mixing across channel groups during training whose contribution decays to zero as the training progresses to convergence. This allows the CCA block to be discarded during inference, thus enabling enhanced performance with no additional computational cost. The resulting $\textit{Scalable CHannEl MixEr}$ (SCHEME) can be plugged into any ViT architecture to obtain a gamut of models with different trade-offs between complexity and performance by controlling the block diagonal structure size in the MLP. This is shown by the introduction of a new family of SCHEMEformer models. Experiments on image classification, object detection, and semantic segmentation, with different ViT backbones, consistently demonstrate substantial accuracy gains over existing designs, especially under lower FLOPs regimes. For example, the SCHEMEformer establishes a new SOTA of 79.7% accuracy for ViTs using pure attention mixers on ImageNet-1K at 1.77G FLOPs.
Class Semantics-based Attention for Action Detection
Sep 06, 2021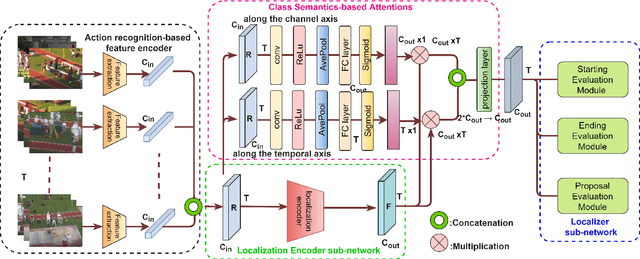
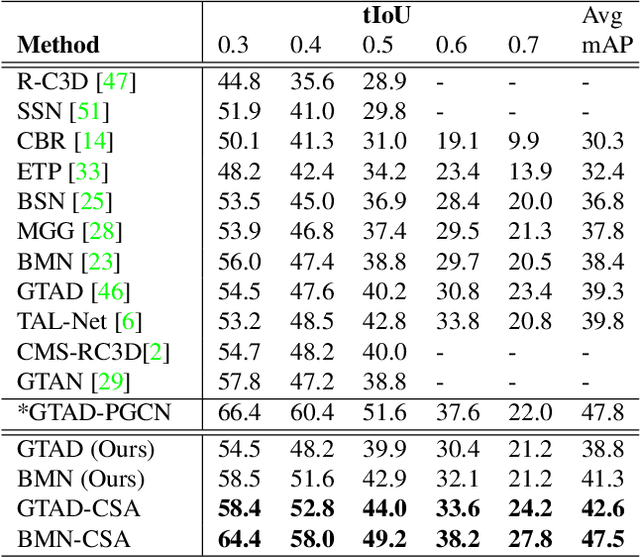
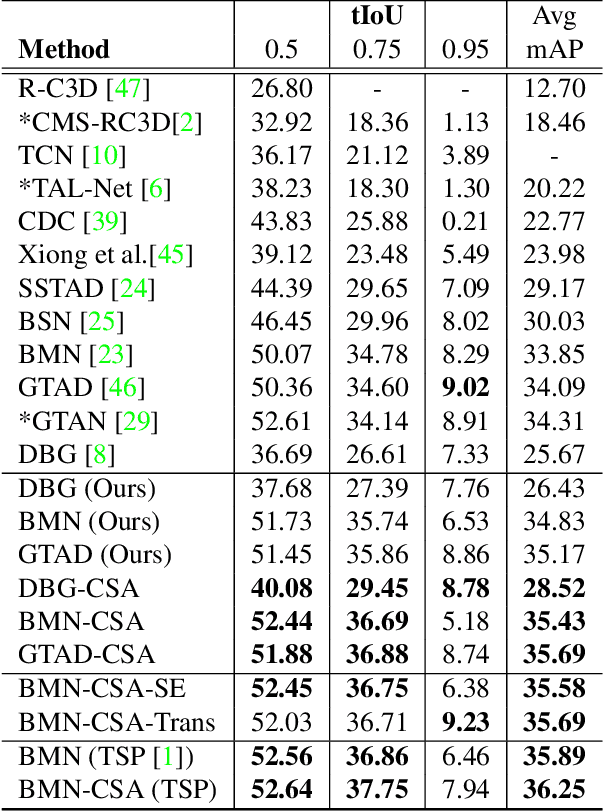
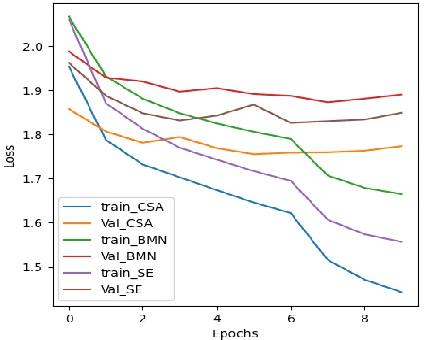
Action localization networks are often structured as a feature encoder sub-network and a localization sub-network, where the feature encoder learns to transform an input video to features that are useful for the localization sub-network to generate reliable action proposals. While some of the encoded features may be more useful for generating action proposals, prior action localization approaches do not include any attention mechanism that enables the localization sub-network to attend more to the more important features. In this paper, we propose a novel attention mechanism, the Class Semantics-based Attention (CSA), that learns from the temporal distribution of semantics of action classes present in an input video to find the importance scores of the encoded features, which are used to provide attention to the more useful encoded features. We demonstrate on two popular action detection datasets that incorporating our novel attention mechanism provides considerable performance gains on competitive action detection models (e.g., around 6.2% improvement over BMN action detection baseline to obtain 47.5% mAP on the THUMOS-14 dataset), and a new state-of-the-art of 36.25% mAP on the ActivityNet v1.3 dataset. Further, the CSA localization model family which includes BMN-CSA, was part of the second-placed submission at the 2021 ActivityNet action localization challenge. Our attention mechanism outperforms prior self-attention modules such as the squeeze-and-excitation in action detection task. We also observe that our attention mechanism is complementary to such self-attention modules in that performance improvements are seen when both are used together.