 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Synergistic Ensemble Learning: Uniting CNNs, MLP-Mixers, and Vision Transformers to Enhance Image Classification
Apr 12, 2025In recent years, Convolutional Neural Networks (CNNs), MLP-mixers, and Vision Transformers have risen to prominence as leading neural architectures in image classification. Prior research has underscored the distinct advantages of each architecture, and there is growing evidence that combining modules from different architectures can boost performance. In this study, we build upon and improve previous work exploring the complementarity between different architectures. Instead of heuristically merging modules from various architectures through trial and error, we preserve the integrity of each architecture and combine them using ensemble techniques. By maintaining the distinctiveness of each architecture, we aim to explore their inherent complementarity more deeply and with implicit isolation. This approach provides a more systematic understanding of their individual strengths. In addition to uncovering insights into architectural complementarity, we showcase the effectiveness of even basic ensemble methods that combine models from diverse architectures. These methods outperform ensembles comprised of similar architectures. Our straightforward ensemble framework serves as a foundational strategy for blending complementary architectures, offering a solid starting point for further investigations into the unique strengths and synergies among different architectures and their ensembles in image classification. A direct outcome of this work is the creation of an ensemble of classification networks that surpasses the accuracy of the previous state-of-the-art single classification network on ImageNet, setting a new benchmark, all while requiring less overall latency.
Self-supervised Spatiotemporal Representation Learning by Exploiting Video Continuity
Jan 10, 2022
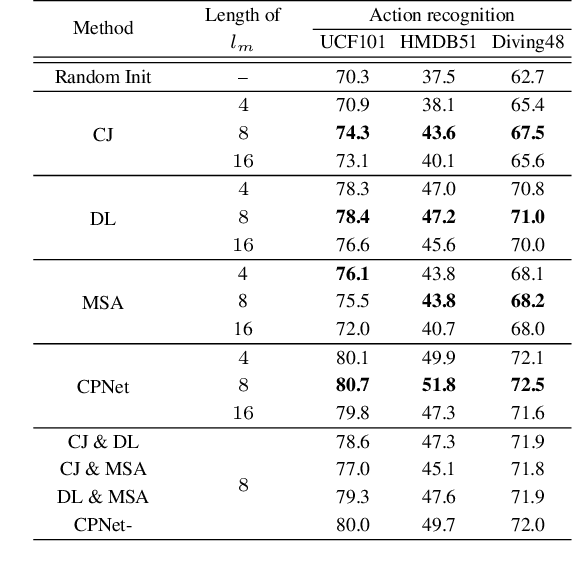
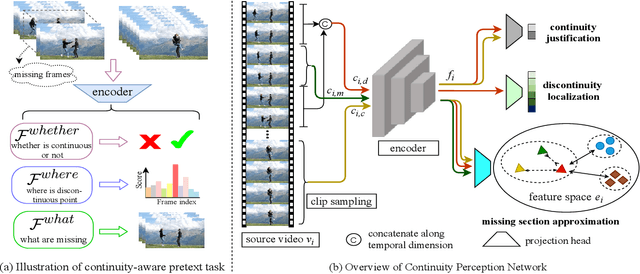
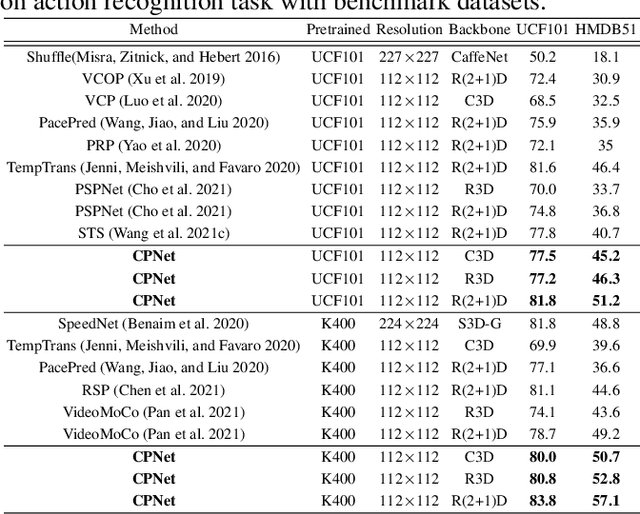
Recent self-supervised video representation learning methods have found significant success by exploring essential properties of videos, e.g. speed, temporal order, etc. This work exploits an essential yet under-explored property of videos, the video continuity, to obtain supervision signals for self-supervised representation learning. Specifically, we formulate three novel continuity-related pretext tasks, i.e. continuity justification, discontinuity localization, and missing section approximation, that jointly supervise a shared backbone for video representation learning. This self-supervision approach, termed as Continuity Perception Network (CPNet), solves the three tasks altogether and encourages the backbone network to learn local and long-ranged motion and context representations. It outperforms prior arts on multiple downstream tasks, such as action recognition, video retrieval, and action localization. Additionally, the video continuity can be complementary to other coarse-grained video properties for representation learning, and integrating the proposed pretext task to prior arts can yield much performance gains.
ConDA: Unsupervised Domain Adaptation for LiDAR Segmentation via Regularized Domain Concatenation
Nov 30, 2021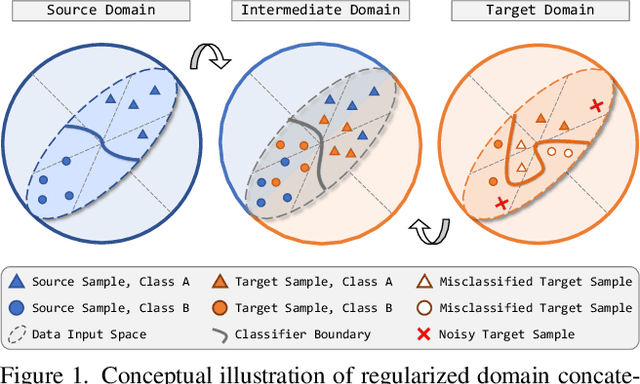
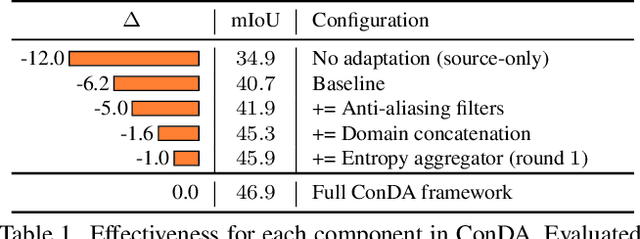
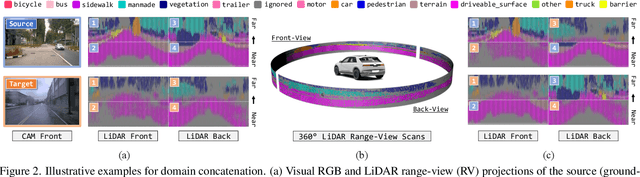

Transferring knowledge learned from the labeled source domain to the raw target domain for unsupervised domain adaptation (UDA) is essential to the scalable deployment of an autonomous driving system. State-of-the-art approaches in UDA often employ a key concept: utilize joint supervision signals from both the source domain (with ground-truth) and the target domain (with pseudo-labels) for self-training. In this work, we improve and extend on this aspect. We present ConDA, a concatenation-based domain adaptation framework for LiDAR semantic segmentation that: (1) constructs an intermediate domain consisting of fine-grained interchange signals from both source and target domains without destabilizing the semantic coherency of objects and background around the ego-vehicle; and (2) utilizes the intermediate domain for self-training. Additionally, to improve both the network training on the source domain and self-training on the intermediate domain, we propose an anti-aliasing regularizer and an entropy aggregator to reduce the detrimental effects of aliasing artifacts and noisy target predictions. Through extensive experiments, we demonstrate that ConDA is significantly more effective in mitigating the domain gap compared to prior arts.
Class Semantics-based Attention for Action Detection
Sep 06, 2021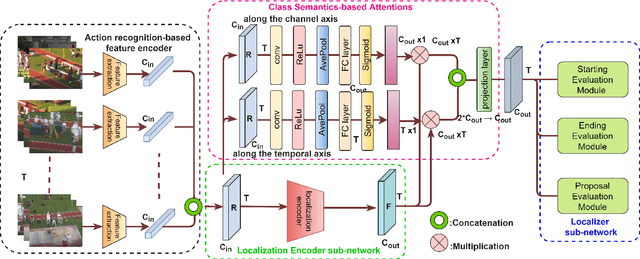
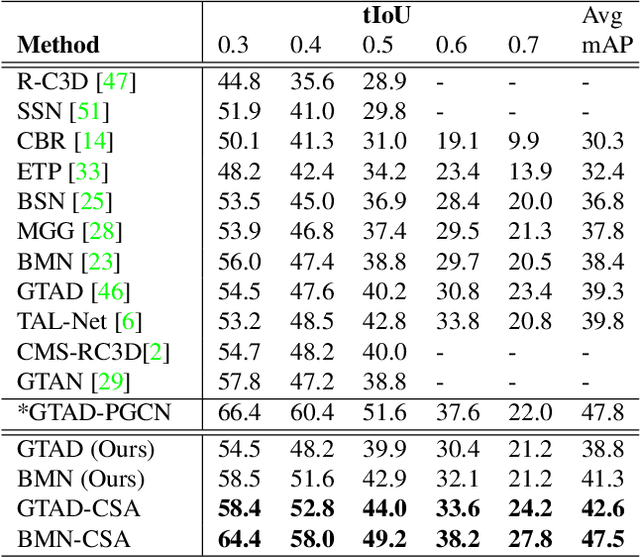
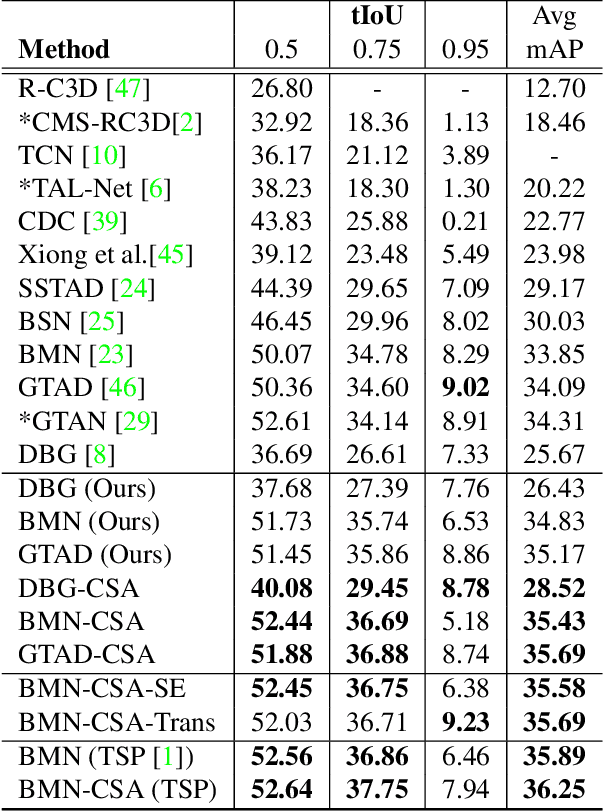
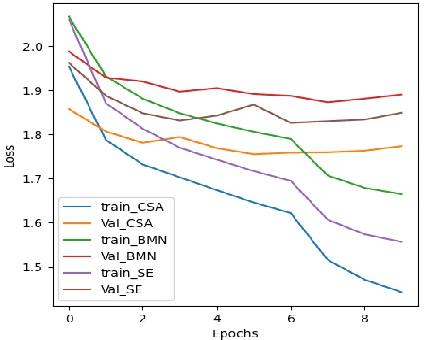
Action localization networks are often structured as a feature encoder sub-network and a localization sub-network, where the feature encoder learns to transform an input video to features that are useful for the localization sub-network to generate reliable action proposals. While some of the encoded features may be more useful for generating action proposals, prior action localization approaches do not include any attention mechanism that enables the localization sub-network to attend more to the more important features. In this paper, we propose a novel attention mechanism, the Class Semantics-based Attention (CSA), that learns from the temporal distribution of semantics of action classes present in an input video to find the importance scores of the encoded features, which are used to provide attention to the more useful encoded features. We demonstrate on two popular action detection datasets that incorporating our novel attention mechanism provides considerable performance gains on competitive action detection models (e.g., around 6.2% improvement over BMN action detection baseline to obtain 47.5% mAP on the THUMOS-14 dataset), and a new state-of-the-art of 36.25% mAP on the ActivityNet v1.3 dataset. Further, the CSA localization model family which includes BMN-CSA, was part of the second-placed submission at the 2021 ActivityNet action localization challenge. Our attention mechanism outperforms prior self-attention modules such as the squeeze-and-excitation in action detection task. We also observe that our attention mechanism is complementary to such self-attention modules in that performance improvements are seen when both are used together.