 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
Dec 11, 2025The growing adoption of XR devices has fueled strong demand for high-quality stereo video, yet its production remains costly and artifact-prone. To address this challenge, we present StereoWorld, an end-to-end framework that repurposes a pretrained video generator for high-fidelity monocular-to-stereo video generation. Our framework jointly conditions the model on the monocular video input while explicitly supervising the generation with a geometry-aware regularization to ensure 3D structural fidelity. A spatio-temporal tiling scheme is further integrated to enable efficient, high-resolution synthesis. To enable large-scale training and evaluation, we curate a high-definition stereo video dataset containing over 11M frames aligned to natural human interpupillary distance (IPD). Extensive experiments demonstrate that StereoWorld substantially outperforms prior methods, generating stereo videos with superior visual fidelity and geometric consistency. The project webpage is available at https://ke-xing.github.io/StereoWorld/.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
ControlEchoSynth: Boosting Ejection Fraction Estimation Models via Controlled Video Diffusion
Aug 25, 2025



Synthetic data generation represents a significant advancement in boosting the performance of machine learning (ML) models, particularly in fields where data acquisition is challenging, such as echocardiography. The acquisition and labeling of echocardiograms (echo) for heart assessment, crucial in point-of-care ultrasound (POCUS) settings, often encounter limitations due to the restricted number of echo views available, typically captured by operators with varying levels of experience. This study proposes a novel approach for enhancing clinical diagnosis accuracy by synthetically generating echo views. These views are conditioned on existing, real views of the heart, focusing specifically on the estimation of ejection fraction (EF), a critical parameter traditionally measured from biplane apical views. By integrating a conditional generative model, we demonstrate an improvement in EF estimation accuracy, providing a comparative analysis with traditional methods. Preliminary results indicate that our synthetic echoes, when used to augment existing datasets, not only enhance EF estimation but also show potential in advancing the development of more robust, accurate, and clinically relevant ML models. This approach is anticipated to catalyze further research in synthetic data applications, paving the way for innovative solutions in medical imaging diagnostics.
TiP4GEN: Text to Immersive Panorama 4D Scene Generation
Aug 17, 2025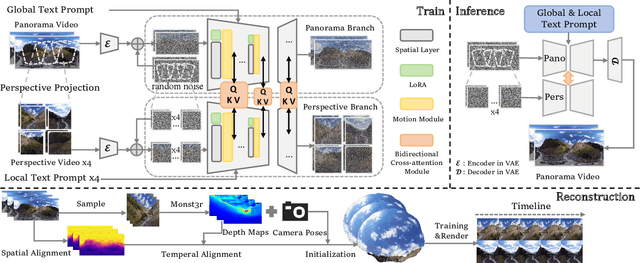
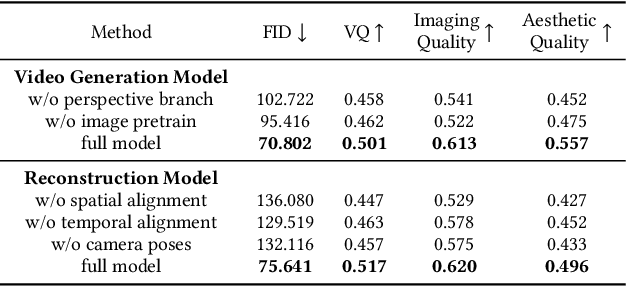
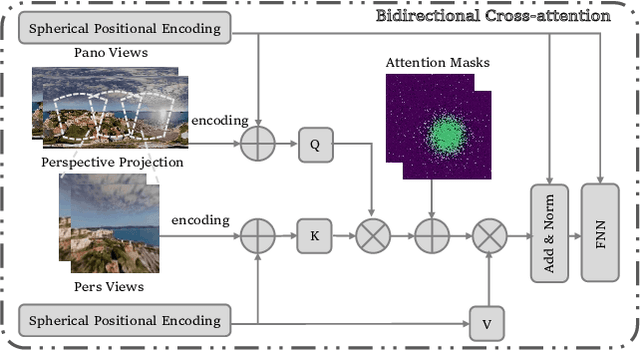
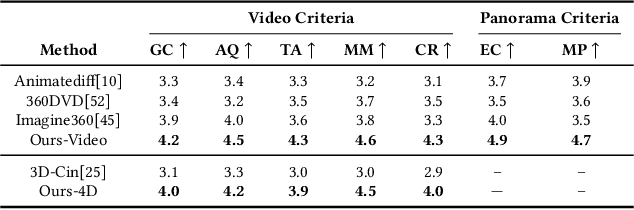
With the rapid advancement and widespread adoption of VR/AR technologies, there is a growing demand for the creation of high-quality, immersive dynamic scenes. However, existing generation works predominantly concentrate on the creation of static scenes or narrow perspective-view dynamic scenes, falling short of delivering a truly 360-degree immersive experience from any viewpoint. In this paper, we introduce \textbf{TiP4GEN}, an advanced text-to-dynamic panorama scene generation framework that enables fine-grained content control and synthesizes motion-rich, geometry-consistent panoramic 4D scenes. TiP4GEN integrates panorama video generation and dynamic scene reconstruction to create 360-degree immersive virtual environments. For video generation, we introduce a \textbf{Dual-branch Generation Model} consisting of a panorama branch and a perspective branch, responsible for global and local view generation, respectively. A bidirectional cross-attention mechanism facilitates comprehensive information exchange between the branches. For scene reconstruction, we propose a \textbf{Geometry-aligned Reconstruction Model} based on 3D Gaussian Splatting. By aligning spatial-temporal point clouds using metric depth maps and initializing scene cameras with estimated poses, our method ensures geometric consistency and temporal coherence for the reconstructed scenes. Extensive experiments demonstrate the effectiveness of our proposed designs and the superiority of TiP4GEN in generating visually compelling and motion-coherent dynamic panoramic scenes. Our project page is at https://ke-xing.github.io/TiP4GEN/.
Beyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking
May 24, 2025Masked diffusion models (MDM) are powerful generative models for discrete data that generate samples by progressively unmasking tokens in a sequence. Each token can take one of two states: masked or unmasked. We observe that token sequences often remain unchanged between consecutive sampling steps; consequently, the model repeatedly processes identical inputs, leading to redundant computation. To address this inefficiency, we propose the Partial masking scheme (Prime), which augments MDM by allowing tokens to take intermediate states interpolated between the masked and unmasked states. This design enables the model to make predictions based on partially observed token information, and facilitates a fine-grained denoising process. We derive a variational training objective and introduce a simple architectural design to accommodate intermediate-state inputs. Our method demonstrates superior performance across a diverse set of generative modeling tasks. On text data, it achieves a perplexity of 15.36 on OpenWebText, outperforming previous MDM (21.52), autoregressive models (17.54), and their hybrid variants (17.58), without relying on an autoregressive formulation. On image data, it attains competitive FID scores of 3.26 on CIFAR-10 and 6.98 on ImageNet-32, comparable to leading continuous generative models.
SpikeDerain: Unveiling Clear Videos from Rainy Sequences Using Color Spike Streams
Mar 26, 2025Restoring clear frames from rainy videos presents a significant challenge due to the rapid motion of rain streaks. Traditional frame-based visual sensors, which capture scene content synchronously, struggle to capture the fast-moving details of rain accurately. In recent years, neuromorphic sensors have introduced a new paradigm for dynamic scene perception, offering microsecond temporal resolution and high dynamic range. However, existing multimodal methods that fuse event streams with RGB images face difficulties in handling the complex spatiotemporal interference of raindrops in real scenes, primarily due to hardware synchronization errors and computational redundancy. In this paper, we propose a Color Spike Stream Deraining Network (SpikeDerain), capable of reconstructing spike streams of dynamic scenes and accurately removing rain streaks. To address the challenges of data scarcity in real continuous rainfall scenes, we design a physically interpretable rain streak synthesis model that generates parameterized continuous rain patterns based on arbitrary background images. Experimental results demonstrate that the network, trained with this synthetic data, remains highly robust even under extreme rainfall conditions. These findings highlight the effectiveness and robustness of our method across varying rainfall levels and datasets, setting new standards for video deraining tasks. The code will be released soon.
Wonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024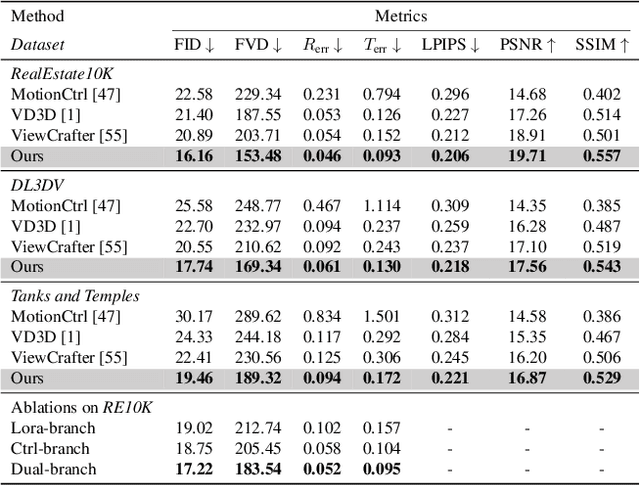
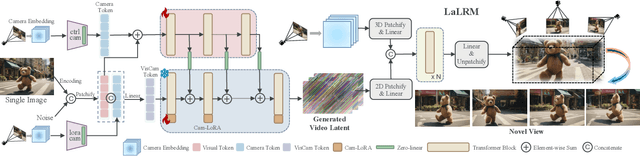
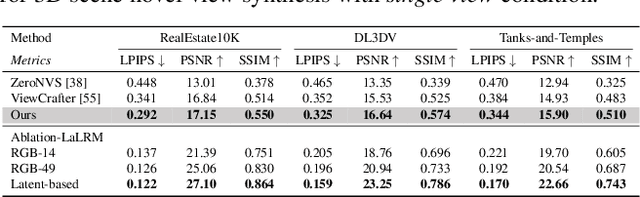

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
May 26, 2024



The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, \textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024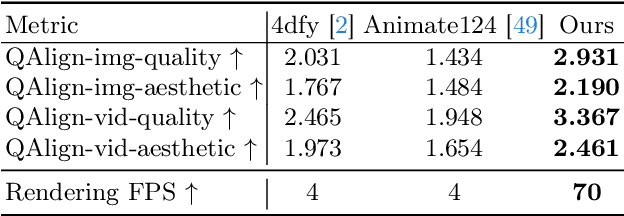
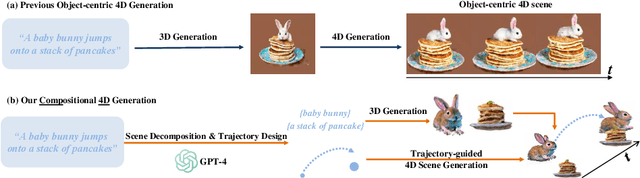

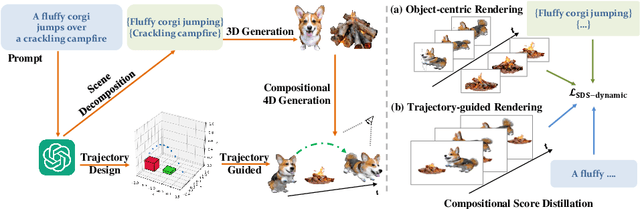
Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
Self-supervised Spatiotemporal Representation Learning by Exploiting Video Continuity
Jan 10, 2022
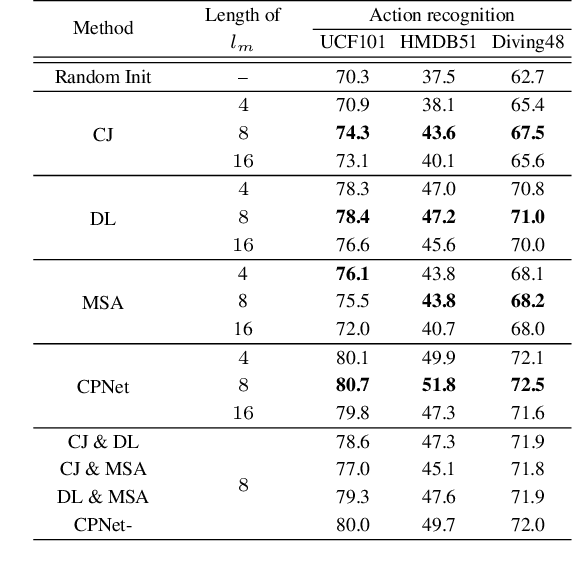
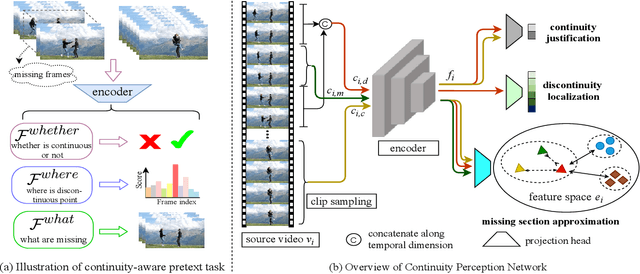
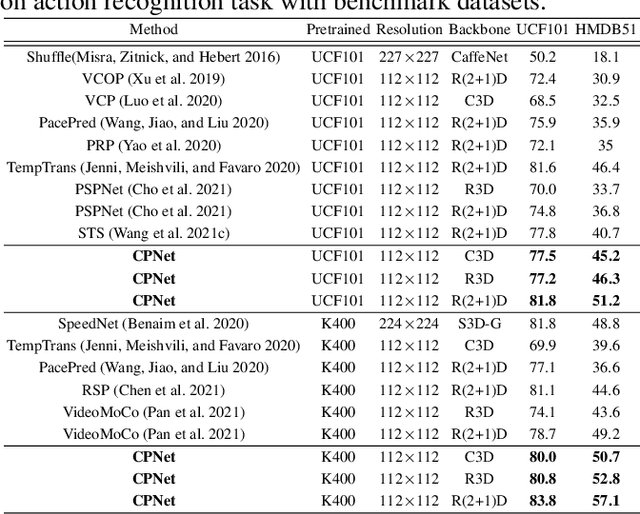
Recent self-supervised video representation learning methods have found significant success by exploring essential properties of videos, e.g. speed, temporal order, etc. This work exploits an essential yet under-explored property of videos, the video continuity, to obtain supervision signals for self-supervised representation learning. Specifically, we formulate three novel continuity-related pretext tasks, i.e. continuity justification, discontinuity localization, and missing section approximation, that jointly supervise a shared backbone for video representation learning. This self-supervision approach, termed as Continuity Perception Network (CPNet), solves the three tasks altogether and encourages the backbone network to learn local and long-ranged motion and context representations. It outperforms prior arts on multiple downstream tasks, such as action recognition, video retrieval, and action localization. Additionally, the video continuity can be complementary to other coarse-grained video properties for representation learning, and integrating the proposed pretext task to prior arts can yield much performance gains.