 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Noticeable Difference Modeling for Deep Visual Features
Jan 29, 2026Deep visual features are increasingly used as the interface in vision systems, motivating the need to describe feature characteristics and control feature quality for machine perception. Just noticeable difference (JND) characterizes the maximum imperceptible distortion for images under human or machine vision. Extending it to deep visual features naturally meets the above demand by providing a task-aligned tolerance boundary in feature space, offering a practical reference for controlling feature quality under constrained resources. We propose FeatJND, a task-aligned JND formulation that predicts the maximum tolerable per-feature perturbation map while preserving downstream task performance. We propose a FeatJND estimator at standardized split points and validate it across image classification, detection, and instance segmentation. Under matched distortion strength, FeatJND-based distortions consistently preserve higher task performance than unstructured Gaussian perturbations, and attribution visualizations suggest FeatJND can suppress non-critical feature regions. As an application, we further apply FeatJND to token-wise dynamic quantization and show that FeatJND-guided step-size allocation yields clear gains over random step-size permutation and global uniform step size under the same noise budget. Our code will be released after publication.
SpikeDerain: Unveiling Clear Videos from Rainy Sequences Using Color Spike Streams
Mar 26, 2025Restoring clear frames from rainy videos presents a significant challenge due to the rapid motion of rain streaks. Traditional frame-based visual sensors, which capture scene content synchronously, struggle to capture the fast-moving details of rain accurately. In recent years, neuromorphic sensors have introduced a new paradigm for dynamic scene perception, offering microsecond temporal resolution and high dynamic range. However, existing multimodal methods that fuse event streams with RGB images face difficulties in handling the complex spatiotemporal interference of raindrops in real scenes, primarily due to hardware synchronization errors and computational redundancy. In this paper, we propose a Color Spike Stream Deraining Network (SpikeDerain), capable of reconstructing spike streams of dynamic scenes and accurately removing rain streaks. To address the challenges of data scarcity in real continuous rainfall scenes, we design a physically interpretable rain streak synthesis model that generates parameterized continuous rain patterns based on arbitrary background images. Experimental results demonstrate that the network, trained with this synthetic data, remains highly robust even under extreme rainfall conditions. These findings highlight the effectiveness and robustness of our method across varying rainfall levels and datasets, setting new standards for video deraining tasks. The code will be released soon.
Rethinking High-speed Image Reconstruction Framework with Spike Camera
Jan 08, 2025



Spike cameras, as innovative neuromorphic devices, generate continuous spike streams to capture high-speed scenes with lower bandwidth and higher dynamic range than traditional RGB cameras. However, reconstructing high-quality images from the spike input under low-light conditions remains challenging. Conventional learning-based methods often rely on the synthetic dataset as the supervision for training. Still, these approaches falter when dealing with noisy spikes fired under the low-light environment, leading to further performance degradation in the real-world dataset. This phenomenon is primarily due to inadequate noise modelling and the domain gap between synthetic and real datasets, resulting in recovered images with unclear textures, excessive noise, and diminished brightness. To address these challenges, we introduce a novel spike-to-image reconstruction framework SpikeCLIP that goes beyond traditional training paradigms. Leveraging the CLIP model's powerful capability to align text and images, we incorporate the textual description of the captured scene and unpaired high-quality datasets as the supervision. Our experiments on real-world low-light datasets U-CALTECH and U-CIFAR demonstrate that SpikeCLIP significantly enhances texture details and the luminance balance of recovered images. Furthermore, the reconstructed images are well-aligned with the broader visual features needed for downstream tasks, ensuring more robust and versatile performance in challenging environments.
USP-Gaussian: Unifying Spike-based Image Reconstruction, Pose Correction and Gaussian Splatting
Nov 15, 2024



Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework, \textbf{USP-Gaussian}, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving fine texture details. Our code, data and trained models will be available at \url{https://github.com/chenkang455/USP-Gaussian}.
SpikeGS: 3D Gaussian Splatting from Spike Streams with High-Speed Camera Motion
Jul 14, 2024



Novel View Synthesis plays a crucial role by generating new 2D renderings from multi-view images of 3D scenes. However, capturing high-speed scenes with conventional cameras often leads to motion blur, hindering the effectiveness of 3D reconstruction. To address this challenge, high-frame-rate dense 3D reconstruction emerges as a vital technique, enabling detailed and accurate modeling of real-world objects or scenes in various fields, including Virtual Reality or embodied AI. Spike cameras, a novel type of neuromorphic sensor, continuously record scenes with an ultra-high temporal resolution, showing potential for accurate 3D reconstruction. Despite their promise, existing approaches, such as applying Neural Radiance Fields (NeRF) to spike cameras, encounter challenges due to the time-consuming rendering process. To address this issue, we make the first attempt to introduce the 3D Gaussian Splatting (3DGS) into spike cameras in high-speed capture, providing 3DGS as dense and continuous clues of views, then constructing SpikeGS. Specifically, to train SpikeGS, we establish computational equations between the rendering process of 3DGS and the processes of instantaneous imaging and exposing-like imaging of the continuous spike stream. Besides, we build a very lightweight but effective mapping process from spikes to instant images to support training. Furthermore, we introduced a new spike-based 3D rendering dataset for validation. Extensive experiments have demonstrated our method possesses the high quality of novel view rendering, proving the tremendous potential of spike cameras in modeling 3D scenes.
SpikeMM: Flexi-Magnification of High-Speed Micro-Motions
Jun 01, 2024
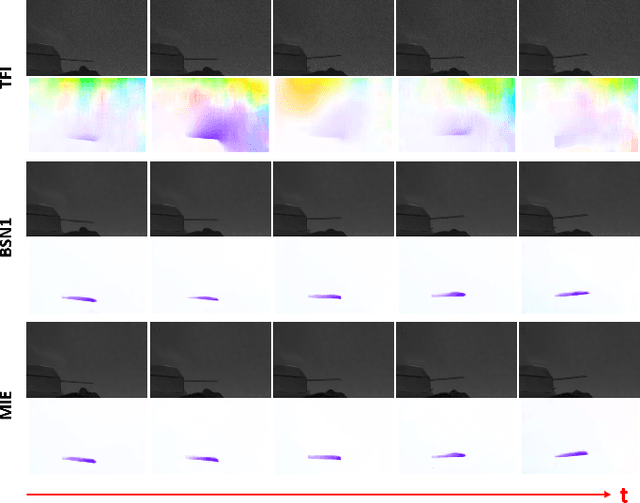


The amplification of high-speed micro-motions holds significant promise, with applications spanning fault detection in fast-paced industrial environments to refining precision in medical procedures. However, conventional motion magnification algorithms often encounter challenges in high-speed scenarios due to low sampling rates or motion blur. In recent years, spike cameras have emerged as a superior alternative for visual tasks in such environments, owing to their unique capability to capture temporal and spatial frequency domains with exceptional fidelity. Unlike conventional cameras, which operate at fixed, low frequencies, spike cameras emulate the functionality of the retina, asynchronously capturing photon changes at each pixel position using spike streams. This innovative approach comprehensively records temporal and spatial visual information, rendering it particularly suitable for magnifying high-speed micro-motions.This paper introduces SpikeMM, a pioneering spike-based algorithm tailored specifically for high-speed motion magnification. SpikeMM integrates multi-level information extraction, spatial upsampling, and motion magnification modules, offering a self-supervised approach adaptable to a wide range of scenarios. Notably, SpikeMM facilitates seamless integration with high-performance super-resolution and motion magnification algorithms. We substantiate the efficacy of SpikeMM through rigorous validation using scenes captured by spike cameras, showcasing its capacity to magnify motions in real-world high-frequency settings.
SpikeReveal: Unlocking Temporal Sequences from Real Blurry Inputs with Spike Streams
Mar 14, 2024



Reconstructing a sequence of sharp images from the blurry input is crucial for enhancing our insights into the captured scene and poses a significant challenge due to the limited temporal features embedded in the image. Spike cameras, sampling at rates up to 40,000 Hz, have proven effective in capturing motion features and beneficial for solving this ill-posed problem. Nonetheless, existing methods fall into the supervised learning paradigm, which suffers from notable performance degradation when applied to real-world scenarios that diverge from the synthetic training data domain. Moreover, the quality of reconstructed images is capped by the generated images based on motion analysis interpolation, which inherently differs from the actual scene, affecting the generalization ability of these methods in real high-speed scenarios. To address these challenges, we propose the first self-supervised framework for the task of spike-guided motion deblurring. Our approach begins with the formulation of a spike-guided deblurring model that explores the theoretical relationships among spike streams, blurry images, and their corresponding sharp sequences. We subsequently develop a self-supervised cascaded framework to alleviate the issues of spike noise and spatial-resolution mismatching encountered in the deblurring model. With knowledge distillation and re-blurring loss, we further design a lightweight deblur network to generate high-quality sequences with brightness and texture consistency with the original input. Quantitative and qualitative experiments conducted on our real-world and synthetic datasets with spikes validate the superior generalization of the proposed framework. Our code, data and trained models will be available at \url{https://github.com/chenkang455/S-SDM}.
Unveiling the Potential of Spike Streams for Foreground Occlusion Removal from Densely Continuous Views
Jul 03, 2023
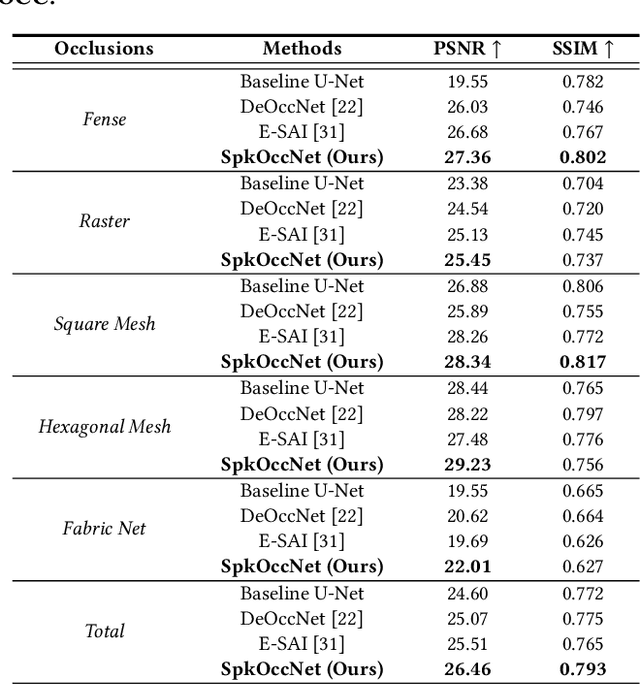

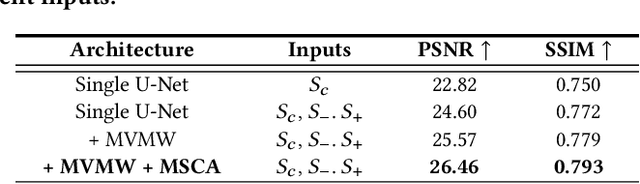
The extraction of a clean background image by removing foreground occlusion holds immense practical significance, but it also presents several challenges. Presently, the majority of de-occlusion research focuses on addressing this issue through the extraction and synthesis of discrete images from calibrated camera arrays. Nonetheless, the restoration quality tends to suffer when faced with dense occlusions or high-speed motions due to limited perspectives and motion blur. To successfully remove dense foreground occlusion, an effective multi-view visual information integration approach is required. Introducing the spike camera as a novel type of neuromorphic sensor offers promising capabilities with its ultra-high temporal resolution and high dynamic range. In this paper, we propose an innovative solution for tackling the de-occlusion problem through continuous multi-view imaging using only one spike camera without any prior knowledge of camera intrinsic parameters and camera poses. By rapidly moving the spike camera, we continually capture the dense stream of spikes from the occluded scene. To process the spikes, we build a novel model \textbf{SpkOccNet}, in which we integrate information of spikes from continuous viewpoints within multi-windows, and propose a novel cross-view mutual attention mechanism for effective fusion and refinement. In addition, we contribute the first real-world spike-based dataset \textbf{S-OCC} for occlusion removal. The experimental results demonstrate that our proposed model efficiently removes dense occlusions in diverse scenes while exhibiting strong generalization.
SpikeCV: Open a Continuous Computer Vision Era
Mar 21, 2023



SpikeCV is a new open-source computer vision platform for the spike camera, which is a neuromorphic visual sensor that has developed rapidly in recent years. In the spike camera, each pixel position directly accumulates the light intensity and asynchronously fires spikes. The output binary spikes can reach a frequency of 40,000 Hz. As a new type of visual expression, spike sequence has high spatiotemporal completeness and preserves the continuous visual information of the external world. Taking advantage of the low latency and high dynamic range of the spike camera, many spike-based algorithms have made significant progress, such as high-quality imaging and ultra-high-speed target detection. To build up a community ecology for the spike vision to facilitate more users to take advantage of the spike camera, SpikeCV provides a variety of ultra-high-speed scene datasets, hardware interfaces, and an easy-to-use modules library. SpikeCV focuses on encapsulation for spike data, standardization for dataset interfaces, modularization for vision tasks, and real-time applications for challenging scenes. With the advent of the open-source Python ecosystem, modules of SpikeCV can be used as a Python library to fulfilled most of the numerical analysis needs of researchers. We demonstrate the efficiency of the SpikeCV on offline inference and real-time applications. The project repository address are \url{https://openi.pcl.ac.cn/Cordium/SpikeCV} and \url{https://github.com/Zyj061/SpikeCV
1000x Faster Camera and Machine Vision with Ordinary Devices
Jan 23, 2022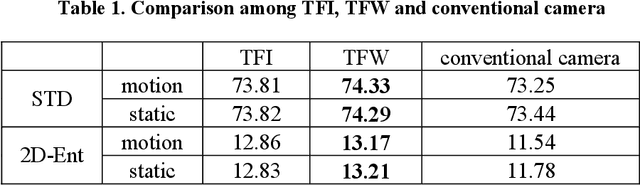


In digital cameras, we find a major limitation: the image and video form inherited from a film camera obstructs it from capturing the rapidly changing photonic world. Here, we present vidar, a bit sequence array where each bit represents whether the accumulation of photons has reached a threshold, to record and reconstruct the scene radiance at any moment. By employing only consumer-level CMOS sensors and integrated circuits, we have developed a vidar camera that is 1,000x faster than conventional cameras. By treating vidar as spike trains in biological vision, we have further developed a spiking neural network-based machine vision system that combines the speed of the machine and the mechanism of biological vision, achieving high-speed object detection and tracking 1,000x faster than human vision. We demonstrate the utility of the vidar camera and the super vision system in an assistant referee and target pointing system. Our study is expected to fundamentally revolutionize the image and video concepts and related industries, including photography, movies, and visual media, and to unseal a new spiking neural network-enabled speed-free machine vision era.