 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
Error Amplification Limits ANN-to-SNN Conversion in Continuous Control
Jan 29, 2026Spiking Neural Networks (SNNs) can achieve competitive performance by converting already existing well-trained Artificial Neural Networks (ANNs), avoiding further costly training. This property is particularly attractive in Reinforcement Learning (RL), where training through environment interaction is expensive and potentially unsafe. However, existing conversion methods perform poorly in continuous control, where suitable baselines are largely absent. We identify error amplification as the key cause: small action approximation errors become temporally correlated across decision steps, inducing cumulative state distribution shift and severe performance degradation. To address this issue, we propose Cross-Step Residual Potential Initialization (CRPI), a lightweight training-free mechanism that carries over residual membrane potentials across decision steps to suppress temporally correlated errors. Experiments on continuous control benchmarks with both vector and visual observations demonstrate that CRPI can be integrated into existing conversion pipelines and substantially recovers lost performance. Our results highlight continuous control as a critical and challenging benchmark for ANN-to-SNN conversion, where small errors can be strongly amplified and impact performance.
Scone: Bridging Composition and Distinction in Subject-Driven Image Generation via Unified Understanding-Generation Modeling
Dec 14, 2025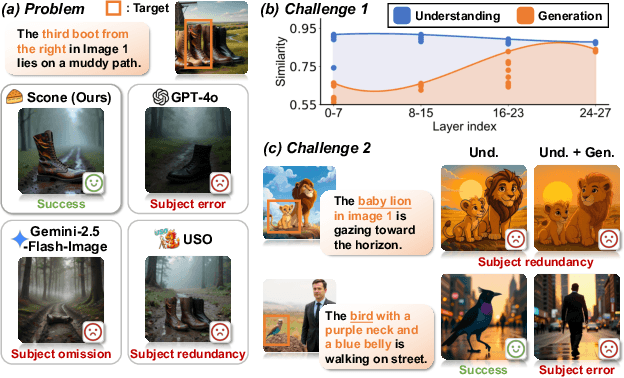

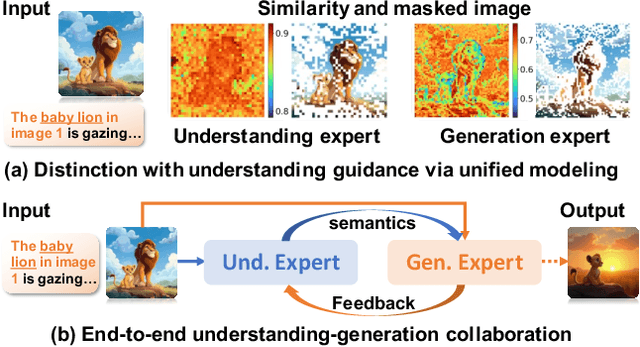
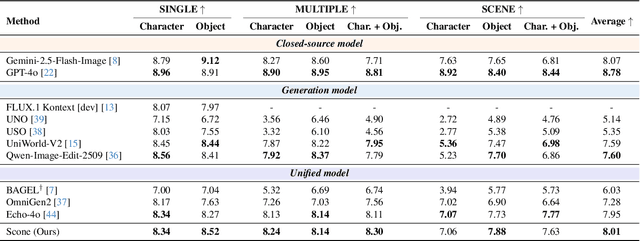
Subject-driven image generation has advanced from single- to multi-subject composition, while neglecting distinction, the ability to identify and generate the correct subject when inputs contain multiple candidates. This limitation restricts effectiveness in complex, realistic visual settings. We propose Scone, a unified understanding-generation method that integrates composition and distinction. Scone enables the understanding expert to act as a semantic bridge, conveying semantic information and guiding the generation expert to preserve subject identity while minimizing interference. A two-stage training scheme first learns composition, then enhances distinction through semantic alignment and attention-based masking. We also introduce SconeEval, a benchmark for evaluating both composition and distinction across diverse scenarios. Experiments demonstrate that Scone outperforms existing open-source models in composition and distinction tasks on two benchmarks. Our model, benchmark, and training data are available at: https://github.com/Ryann-Ran/Scone.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025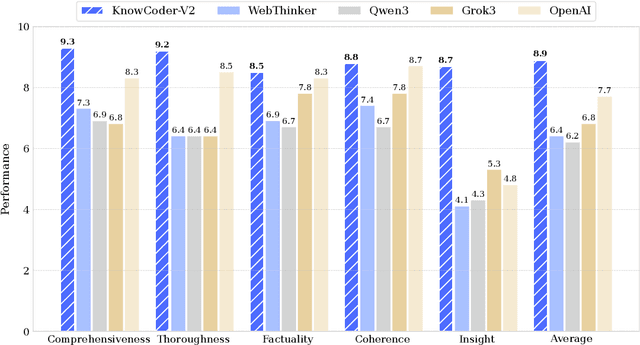
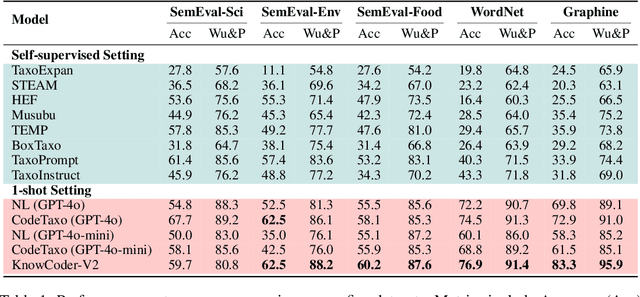
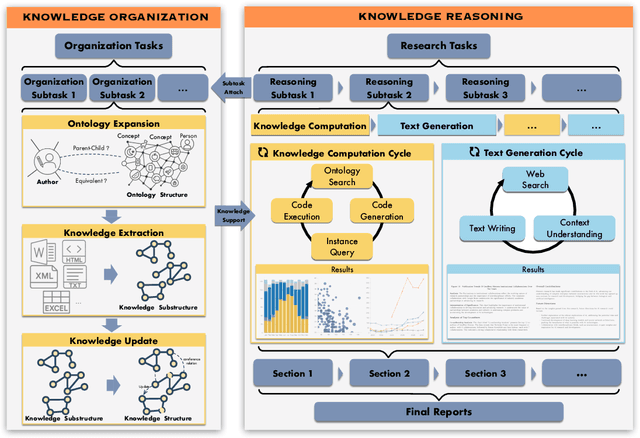
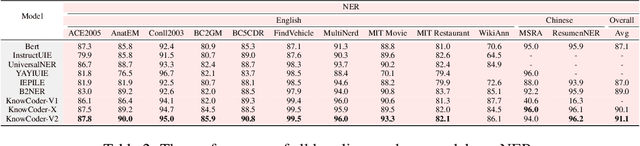
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
Expanding Zero-Shot Object Counting with Rich Prompts
May 21, 2025Expanding pre-trained zero-shot counting models to handle unseen categories requires more than simply adding new prompts, as this approach does not achieve the necessary alignment between text and visual features for accurate counting. We introduce RichCount, the first framework to address these limitations, employing a two-stage training strategy that enhances text encoding and strengthens the model's association with objects in images. RichCount improves zero-shot counting for unseen categories through two key objectives: (1) enriching text features with a feed-forward network and adapter trained on text-image similarity, thereby creating robust, aligned representations; and (2) applying this refined encoder to counting tasks, enabling effective generalization across diverse prompts and complex images. In this manner, RichCount goes beyond simple prompt expansion to establish meaningful feature alignment that supports accurate counting across novel categories. Extensive experiments on three benchmark datasets demonstrate the effectiveness of RichCount, achieving state-of-the-art performance in zero-shot counting and significantly enhancing generalization to unseen categories in open-world scenarios.
SOTA: Spike-Navigated Optimal TrAnsport Saliency Region Detection in Composite-bias Videos
May 01, 2025Existing saliency detection methods struggle in real-world scenarios due to motion blur and occlusions. In contrast, spike cameras, with their high temporal resolution, significantly enhance visual saliency maps. However, the composite noise inherent to spike camera imaging introduces discontinuities in saliency detection. Low-quality samples further distort model predictions, leading to saliency bias. To address these challenges, we propose Spike-navigated Optimal TrAnsport Saliency Region Detection (SOTA), a framework that leverages the strengths of spike cameras while mitigating biases in both spatial and temporal dimensions. Our method introduces Spike-based Micro-debias (SM) to capture subtle frame-to-frame variations and preserve critical details, even under minimal scene or lighting changes. Additionally, Spike-based Global-debias (SG) refines predictions by reducing inconsistencies across diverse conditions. Extensive experiments on real and synthetic datasets demonstrate that SOTA outperforms existing methods by eliminating composite noise bias. Our code and dataset will be released at https://github.com/lwxfight/sota.
Beyond the Horizon: Decoupling UAVs Multi-View Action Recognition via Partial Order Transfer
Apr 29, 2025Action recognition in unmanned aerial vehicles (UAVs) poses unique challenges due to significant view variations along the vertical spatial axis. Unlike traditional ground-based settings, UAVs capture actions from a wide range of altitudes, resulting in considerable appearance discrepancies. We introduce a multi-view formulation tailored to varying UAV altitudes and empirically observe a partial order among views, where recognition accuracy consistently decreases as the altitude increases. This motivates a novel approach that explicitly models the hierarchical structure of UAV views to improve recognition performance across altitudes. To this end, we propose the Partial Order Guided Multi-View Network (POG-MVNet), designed to address drastic view variations by effectively leveraging view-dependent information across different altitude levels. The framework comprises three key components: a View Partition (VP) module, which uses the head-to-body ratio to group views by altitude; an Order-aware Feature Decoupling (OFD) module, which disentangles action-relevant and view-specific features under partial order guidance; and an Action Partial Order Guide (APOG), which leverages the partial order to transfer informative knowledge from easier views to support learning in more challenging ones. We conduct experiments on Drone-Action, MOD20, and UAV datasets, demonstrating that POG-MVNet significantly outperforms competing methods. For example, POG-MVNet achieves a 4.7% improvement on Drone-Action dataset and a 3.5% improvement on UAV dataset compared to state-of-the-art methods ASAT and FAR. The code for POG-MVNet will be made available soon.
SU-YOLO: Spiking Neural Network for Efficient Underwater Object Detection
Mar 31, 2025Underwater object detection is critical for oceanic research and industrial safety inspections. However, the complex optical environment and the limited resources of underwater equipment pose significant challenges to achieving high accuracy and low power consumption. To address these issues, we propose Spiking Underwater YOLO (SU-YOLO), a Spiking Neural Network (SNN) model. Leveraging the lightweight and energy-efficient properties of SNNs, SU-YOLO incorporates a novel spike-based underwater image denoising method based solely on integer addition, which enhances the quality of feature maps with minimal computational overhead. In addition, we introduce Separated Batch Normalization (SeBN), a technique that normalizes feature maps independently across multiple time steps and is optimized for integration with residual structures to capture the temporal dynamics of SNNs more effectively. The redesigned spiking residual blocks integrate the Cross Stage Partial Network (CSPNet) with the YOLO architecture to mitigate spike degradation and enhance the model's feature extraction capabilities. Experimental results on URPC2019 underwater dataset demonstrate that SU-YOLO achieves mAP of 78.8% with 6.97M parameters and an energy consumption of 2.98 mJ, surpassing mainstream SNN models in both detection accuracy and computational efficiency. These results underscore the potential of SNNs for engineering applications. The code is available in https://github.com/lwxfight/snn-underwater.
Foveated Instance Segmentation
Mar 27, 2025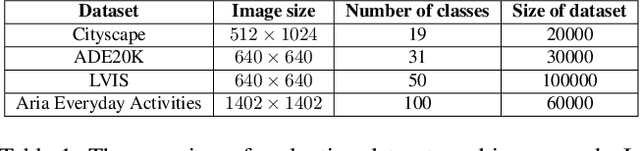
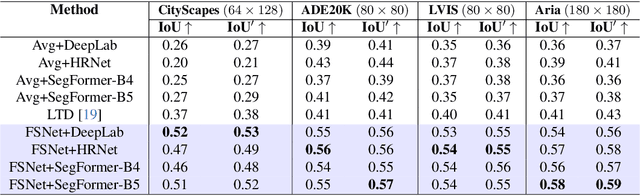
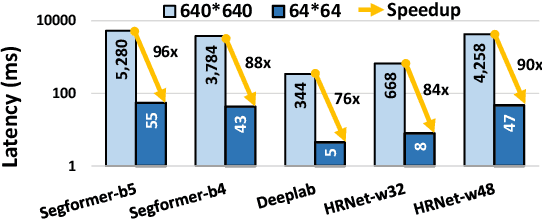
Instance segmentation is essential for augmented reality and virtual reality (AR/VR) as it enables precise object recognition and interaction, enhancing the integration of virtual and real-world elements for an immersive experience. However, the high computational overhead of segmentation limits its application on resource-constrained AR/VR devices, causing large processing latency and degrading user experience. In contrast to conventional scenarios, AR/VR users typically focus on only a few regions within their field of view before shifting perspective, allowing segmentation to be concentrated on gaze-specific areas. This insight drives the need for efficient segmentation methods that prioritize processing instance of interest, reducing computational load and enhancing real-time performance. In this paper, we present a foveated instance segmentation (FovealSeg) framework that leverages real-time user gaze data to perform instance segmentation exclusively on instance of interest, resulting in substantial computational savings. Evaluation results show that FSNet achieves an IoU of 0.56 on ADE20K and 0.54 on LVIS, notably outperforming the baseline. The code is available at https://github.com/SAI-