 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
Stepsize anything: A unified learning rate schedule for budgeted-iteration training
May 30, 2025The expanding computational costs and limited resources underscore the critical need for budgeted-iteration training, which aims to achieve optimal learning within predetermined iteration budgets.While learning rate schedules fundamentally govern the performance of different networks and tasks, particularly in budgeted-iteration scenarios, their design remains largely heuristic, lacking theoretical foundations.In addition, the optimal learning rate schedule requires extensive trial-and-error selection, making the training process inefficient.In this work, we propose the Unified Budget-Aware (UBA) schedule, a theoretically grounded learning rate schedule that consistently outperforms commonly-used schedules among diverse architectures and tasks under different constrained training budgets.First, we bridge the gap by constructing a novel training budget-aware optimization framework, which explicitly accounts for the robustness to landscape curvature variations.From this framework, we derive the UBA schedule, controlled by a single hyper-parameter $\varphi$ that provides a trade-off between flexibility and simplicity, eliminating the need for per-network numerical optimization. Moreover, we establish a theoretical connection between $\varphi$ and the condition number, adding interpretation and justification to our approach. Besides, we prove the convergence for different values of $\varphi$.We offer practical guidelines for its selection via theoretical analysis and empirical results.xtensive experimental results show that UBA \textit{consistently surpasses} the commonly-used schedules across diverse vision and language tasks, spanning network architectures (e.g., ResNet, OLMo) and scales, under different training-iteration budgets.
Scaling Law for Quantization-Aware Training
May 20, 2025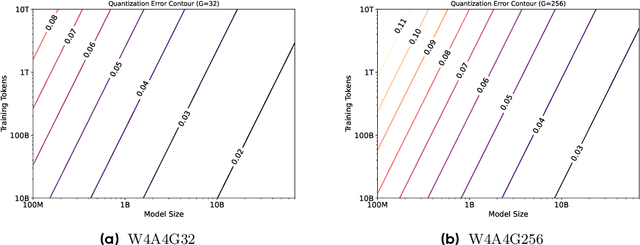
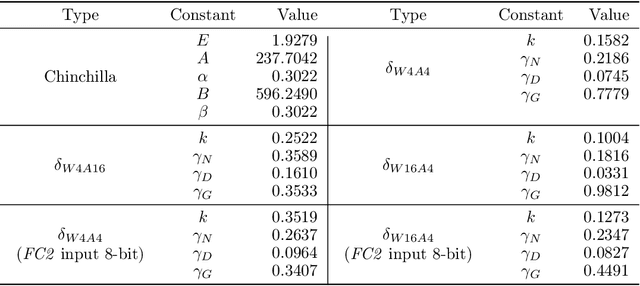
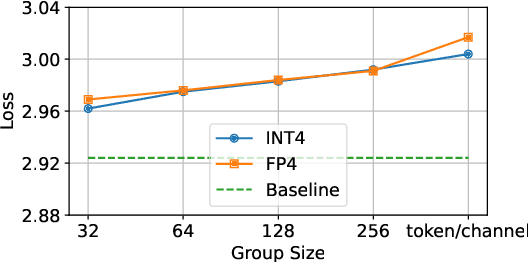
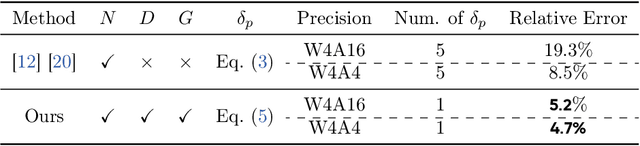
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Efficient Pretraining Length Scaling
Apr 21, 2025Recent advances in large language models have demonstrated the effectiveness of length scaling during post-training, yet its potential in pre-training remains underexplored. We present the Parallel Hidden Decoding Transformer (\textit{PHD}-Transformer), a novel framework that enables efficient length scaling during pre-training while maintaining inference efficiency. \textit{PHD}-Transformer achieves this through an innovative KV cache management strategy that distinguishes between original tokens and hidden decoding tokens. By retaining only the KV cache of original tokens for long-range dependencies while immediately discarding hidden decoding tokens after use, our approach maintains the same KV cache size as the vanilla transformer while enabling effective length scaling. To further enhance performance, we introduce two optimized variants: \textit{PHD-SWA} employs sliding window attention to preserve local dependencies, while \textit{PHD-CSWA} implements chunk-wise sliding window attention to eliminate linear growth in pre-filling time. Extensive experiments demonstrate consistent improvements across multiple benchmarks.
Frac-Connections: Fractional Extension of Hyper-Connections
Mar 18, 2025Residual connections are central to modern deep learning architectures, enabling the training of very deep networks by mitigating gradient vanishing. Hyper-Connections recently generalized residual connections by introducing multiple connection strengths at different depths, thereby addressing the seesaw effect between gradient vanishing and representation collapse. However, Hyper-Connections increase memory access costs by expanding the width of hidden states. In this paper, we propose Frac-Connections, a novel approach that divides hidden states into multiple parts rather than expanding their width. Frac-Connections retain partial benefits of Hyper-Connections while reducing memory consumption. To validate their effectiveness, we conduct large-scale experiments on language tasks, with the largest being a 7B MoE model trained on up to 3T tokens, demonstrating that Frac-Connections significantly outperform residual connections.
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Mar 06, 2025Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the location of layer normalization. While Pre-Norm structures facilitate easier training due to their more prominent identity path, they often yield suboptimal performance compared to Post-Norm. In this paper, we propose $\textbf{HybridNorm}$, a straightforward yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm approaches. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. This design not only stabilizes training but also enhances performance, particularly in the context of LLMs. Comprehensive experiments in both dense and sparse architectures show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches, achieving state-of-the-art results across various benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. %Code will be made publicly available. Code is available at https://github.com/BryceZhuo/HybridNorm.
Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models
Feb 21, 2025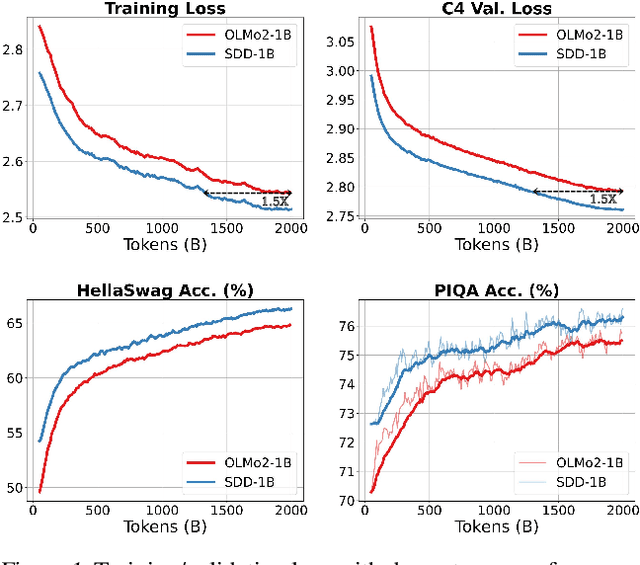
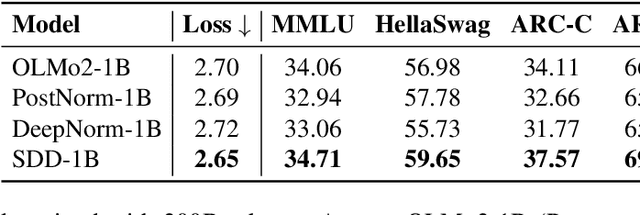
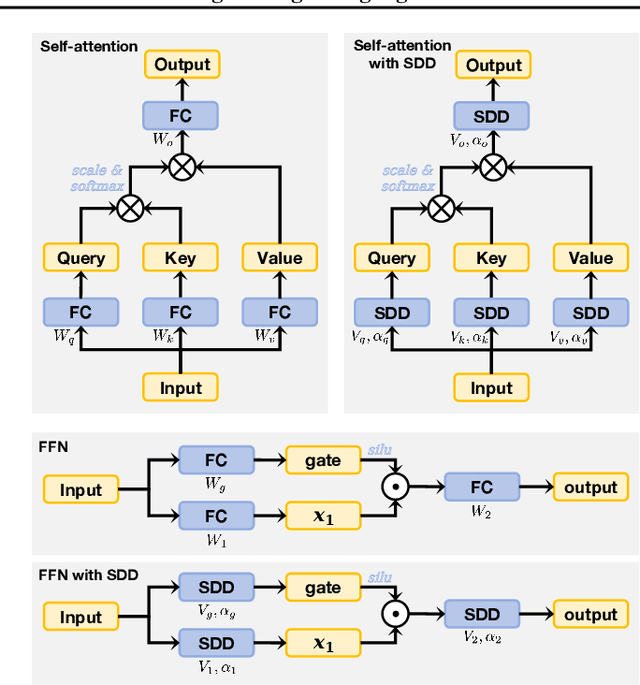
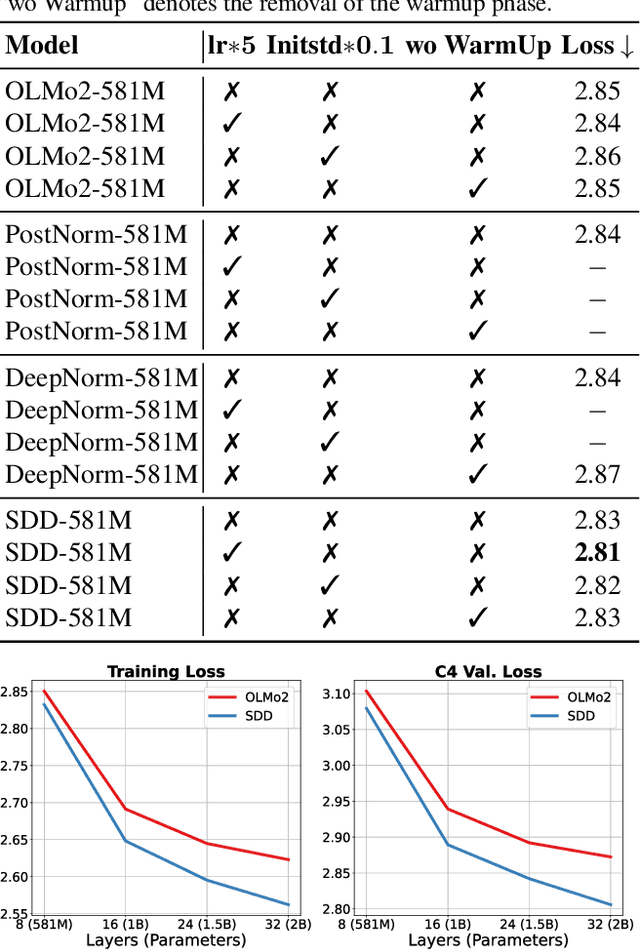
Training stability is a persistent challenge in the pre-training of large language models (LLMs), particularly for architectures such as Post-Norm Transformers, which are prone to gradient explosion and dissipation. In this paper, we propose Scale-Distribution Decoupling (SDD), a novel approach that stabilizes training by explicitly decoupling the scale and distribution of the weight matrix in fully-connected layers. SDD applies a normalization mechanism to regulate activations and a learnable scaling vector to maintain well-conditioned gradients, effectively preventing $\textbf{gradient explosion and dissipation}$. This separation improves optimization efficiency, particularly in deep networks, by ensuring stable gradient propagation. Experimental results demonstrate that our method stabilizes training across various LLM architectures and outperforms existing techniques in different normalization configurations. Furthermore, the proposed method is lightweight and compatible with existing frameworks, making it a practical solution for stabilizing LLM training. Code is available at https://github.com/kaihemo/SDD.
SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models
Feb 18, 2025The increasing application of multi-modal large language models (MLLMs) across various sectors have spotlighted the essence of their output reliability and accuracy, particularly their ability to produce content grounded in factual information (e.g. common and domain-specific knowledge). In this work, we introduce SimpleVQA, the first comprehensive multi-modal benchmark to evaluate the factuality ability of MLLMs to answer natural language short questions. SimpleVQA is characterized by six key features: it covers multiple tasks and multiple scenarios, ensures high quality and challenging queries, maintains static and timeless reference answers, and is straightforward to evaluate. Our approach involves categorizing visual question-answering items into 9 different tasks around objective events or common knowledge and situating these within 9 topics. Rigorous quality control processes are implemented to guarantee high-quality, concise, and clear answers, facilitating evaluation with minimal variance via an LLM-as-a-judge scoring system. Using SimpleVQA, we perform a comprehensive assessment of leading 18 MLLMs and 8 text-only LLMs, delving into their image comprehension and text generation abilities by identifying and analyzing error cases.
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
Jan 28, 2025Tokenization is a fundamental component of large language models (LLMs), yet its influence on model scaling and performance is not fully explored. In this paper, we introduce Over-Tokenized Transformers, a novel framework that decouples input and output vocabularies to improve language modeling performance. Specifically, our approach scales up input vocabularies to leverage multi-gram tokens. Through extensive experiments, we uncover a log-linear relationship between input vocabulary size and training loss, demonstrating that larger input vocabularies consistently enhance model performance, regardless of model size. Using a large input vocabulary, we achieve performance comparable to double-sized baselines with no additional cost. Our findings highlight the importance of tokenization in scaling laws and provide practical insight for tokenizer design, paving the way for more efficient and powerful LLMs.