 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models
Feb 18, 2025



The increasing application of multi-modal large language models (MLLMs) across various sectors have spotlighted the essence of their output reliability and accuracy, particularly their ability to produce content grounded in factual information (e.g. common and domain-specific knowledge). In this work, we introduce SimpleVQA, the first comprehensive multi-modal benchmark to evaluate the factuality ability of MLLMs to answer natural language short questions. SimpleVQA is characterized by six key features: it covers multiple tasks and multiple scenarios, ensures high quality and challenging queries, maintains static and timeless reference answers, and is straightforward to evaluate. Our approach involves categorizing visual question-answering items into 9 different tasks around objective events or common knowledge and situating these within 9 topics. Rigorous quality control processes are implemented to guarantee high-quality, concise, and clear answers, facilitating evaluation with minimal variance via an LLM-as-a-judge scoring system. Using SimpleVQA, we perform a comprehensive assessment of leading 18 MLLMs and 8 text-only LLMs, delving into their image comprehension and text generation abilities by identifying and analyzing error cases.
ECLIPSE: Semantic Entropy-LCS for Cross-Lingual Industrial Log Parsing
May 22, 2024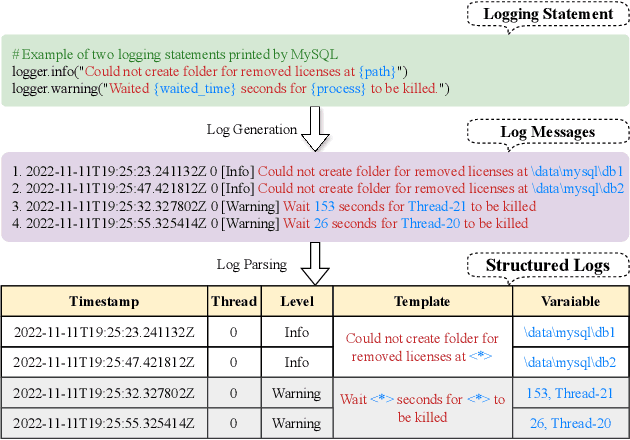


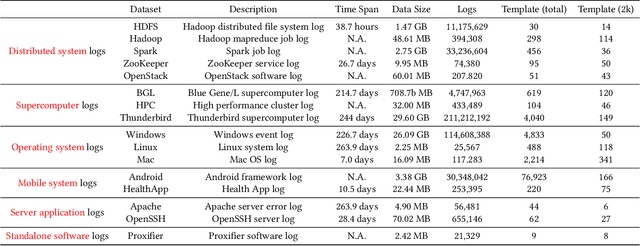
Log parsing, a vital task for interpreting the vast and complex data produced within software architectures faces significant challenges in the transition from academic benchmarks to the industrial domain. Existing log parsers, while highly effective on standardized public datasets, struggle to maintain performance and efficiency when confronted with the sheer scale and diversity of real-world industrial logs. These challenges are two-fold: 1) massive log templates: The performance and efficiency of most existing parsers will be significantly reduced when logs of growing quantities and different lengths; 2) Complex and changeable semantics: Traditional template-matching algorithms cannot accurately match the log templates of complicated industrial logs because they cannot utilize cross-language logs with similar semantics. To address these issues, we propose ECLIPSE, Enhanced Cross-Lingual Industrial log Parsing with Semantic Entropy-LCS, since cross-language logs can robustly parse industrial logs. On the one hand, it integrates two efficient data-driven template-matching algorithms and Faiss indexing. On the other hand, driven by the powerful semantic understanding ability of the Large Language Model (LLM), the semantics of log keywords were accurately extracted, and the retrieval space was effectively reduced. It is worth noting that we launched a Chinese and English cross-platform industrial log parsing benchmark ECLIPSE-Bench to evaluate the performance of mainstream parsers in industrial scenarios. Our experimental results, conducted across public benchmarks and the proprietary ECLIPSE-Bench dataset, underscore the superior performance and robustness of our proposed ECLIPSE. Notably, ECLIPSE delivers state-of-the-art performance when compared to strong baselines on diverse datasets and preserves a significant edge in processing efficiency.