 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
May 19, 2026Video generation is rapidly evolving from single-shot synthesis to complex multi-shot audio-video (MSAV) narratives to meet real-world demands. However, evaluating such frontier models remains a fundamental challenge. Existing benchmarks are limited in scope and data diversity, and rely on rigid evaluation pipelines, preventing systematic and reliable assessment of modern MSAV models. To bridge these gaps, we introduce MSAVBench, the first comprehensive benchmark and adaptive hybrid evaluation framework for multi-shot audio-video generation. Our benchmark spans four key dimensions, video, audio, shot, and reference, covering diverse task settings, varying shot counts of up to 15, and challenging non-realistic scenarios. Our evaluation framework improves robustness through an adaptive self-correction mechanism for shot segmentation, instance-wise rubrics for subjective metrics, and tool-grounded evidence extraction for complex judgments. Furthermore, MSAVBench achieves high alignment with human judgments, reaching a Spearman rank correlation of 91.5%. Our systematic evaluation of 19 state-of-the-art closed- and open-source models shows that current systems still struggle with director-level control and fine-grained audio-visual synchronization, while modular or agentic generation pipelines offer a promising path toward narrowing the gap between open- and closed-source models. We will release the benchmark data and evaluation code to facilitate future research.
DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
May 14, 2026Reinforcement learning has emerged as a powerful tool for improving diffusion-based text-to-image models, but existing methods are largely limited to single-task optimization. Extending RL to multiple tasks is challenging: joint optimization suffers from cross-task interference and imbalance, while cascade RL is cumbersome and prone to catastrophic forgetting. We propose DiffusionOPD, a new multi-task training paradigm for diffusion models based on Online Policy Distillation (OPD). DiffusionOPD first trains task-specific teachers independently, then distills their capabilities into a unified student along the student own rollout trajectories. This decouples single-task exploration from multi-task integration and avoids the optimization burden of solving all tasks jointly from scratch. Theoretically, we lift the OPD framework from discrete tokens to continuous-state Markov processes, deriving a closed-form per-step KL objective that unifies both stochastic SDE and deterministic ODE refinement via mean-matching. We formally and empirically demonstrate that this analytic gradient provides lower variance and better generality compared to conventional PPO-style policy gradients. Extensive experiments show that DiffusionOPD consistently surpasses both multi-reward RL and cascade RL baselines in training efficiency and final performance, while achieving state-of-the-art results on all evaluated benchmarks.
Bridging Brain and Semantics: A Hierarchical Framework for Semantically Enhanced fMRI-to-Video Reconstruction
May 14, 2026Reconstructing dynamic visual experiences as videos from functional magnetic resonance imaging (fMRI) is pivotal for advancing the understanding of neural processes. However, current fMRI-to-video reconstruction methods are hindered by a semantic gap between noisy fMRI signals and the rich content of videos, stemming from a reliance on incomplete semantic embeddings that neither capture video-specific cues (e.g., actions) nor integrate prior knowledge. To this end, we draw inspiration from the dual-pathway processing mechanism in human brain and introduce CineNeuron, a novel hierarchical framework for semantically enhanced video reconstruction from fMRI signals with two synergistic stages. First, a bottom-up semantic enrichment stage maps fMRI signals to a rich embedding space that comprehensively captures textual semantics, image contents, action concepts, and object categories. Second, a top-down memory integration stage utilizes the proposed Mixture-of-Memories method to dynamically select relevant "memories" from previously seen data and fuse them with the fMRI embedding to refine the video reconstruction. Extensive experimental results on two fMRI-to-video benchmarks demonstrate that CineNeuron surpasses state-of-the-art methods across various metrics.
M$^\star$: Every Task Deserves Its Own Memory Harness
Apr 10, 2026Large language model agents rely on specialized memory systems to accumulate and reuse knowledge during extended interactions. Recent architectures typically adopt a fixed memory design tailored to specific domains, such as semantic retrieval for conversations or skills reused for coding. However, a memory system optimized for one purpose frequently fails to transfer to others. To address this limitation, we introduce M$^\star$, a method that automatically discovers task-optimized memory harnesses through executable program evolution. Specifically, M$^\star$ models an agent memory system as a memory program written in Python. This program encapsulates the data Schema, the storage Logic, and the agent workflow Instructions. We optimize these components jointly using a reflective code evolution method; this approach employs a population-based search strategy and analyzes evaluation failures to iteratively refine the candidate programs. We evaluate M$^\star$ on four distinct benchmarks spanning conversation, embodied planning, and expert reasoning. Our results demonstrate that M$^\star$ improves performance over existing fixed-memory baselines robustly across all evaluated tasks. Furthermore, the evolved memory programs exhibit structurally distinct processing mechanisms for each domain. This finding indicates that specializing the memory mechanism for a given task explores a broad design space and provides a superior solution compared to general-purpose memory paradigms.
AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
Mar 31, 2026Although image generation has boosted various applications via its rapid evolution, whether the state-of-the-art models are able to produce ready-to-use academic illustrations for papers is still largely unexplored. Directly comparing or evaluating the illustration with VLM is native but requires oracle multi-modal understanding ability, which is unreliable for long and complex texts and illustrations. To address this, we propose AIBench, the first benchmark using VQA for evaluating logic correctness of the academic illustrations and VLMs for assessing aesthetics. In detail, we designed four levels of questions proposed from a logic diagram summarized from the method part of the paper, which query whether the generated illustration aligns with the paper on different scales. Our VQA-based approach raises more accurate and detailed evaluations on visual-logical consistency while relying less on the ability of the judger VLM. With our high-quality AIBench, we conduct extensive experiments and conclude that the performance gap between models on this task is significantly larger than general ones, reflecting their various complex reasoning and high-density generation ability. Further, the logic and aesthetics are hard to optimize simultaneously as in handcrafted illustrations. Additional experiments further state that test-time scaling on both abilities significantly boosts the performance on this task.
DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
Mar 12, 2026While large-scale diffusion models have revolutionized video synthesis, achieving precise control over both multi-subject identity and multi-granularity motion remains a significant challenge. Recent attempts to bridge this gap often suffer from limited motion granularity, control ambiguity, and identity degradation, leading to suboptimal performance on identity preservation and motion control. In this work, we present DreamVideo-Omni, a unified framework enabling harmonious multi-subject customization with omni-motion control via a progressive two-stage training paradigm. In the first stage, we integrate comprehensive control signals for joint training, encompassing subject appearances, global motion, local dynamics, and camera movements. To ensure robust and precise controllability, we introduce a condition-aware 3D rotary positional embedding to coordinate heterogeneous inputs and a hierarchical motion injection strategy to enhance global motion guidance. Furthermore, to resolve multi-subject ambiguity, we introduce group and role embeddings to explicitly anchor motion signals to specific identities, effectively disentangling complex scenes into independent controllable instances. In the second stage, to mitigate identity degradation, we design a latent identity reward feedback learning paradigm by training a latent identity reward model upon a pretrained video diffusion backbone. This provides motion-aware identity rewards in the latent space, prioritizing identity preservation aligned with human preferences. Supported by our curated large-scale dataset and the comprehensive DreamOmni Bench for multi-subject and omni-motion control evaluation, DreamVideo-Omni demonstrates superior performance in generating high-quality videos with precise controllability.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025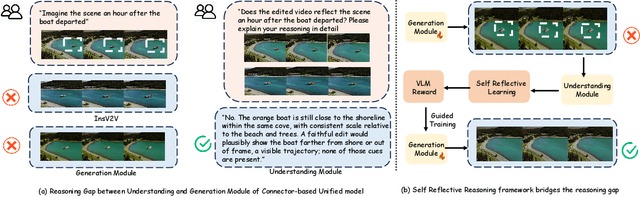
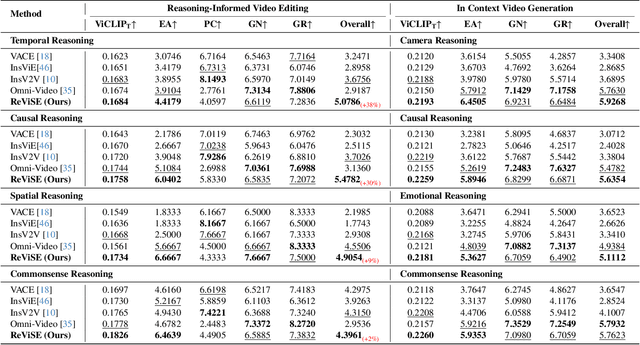

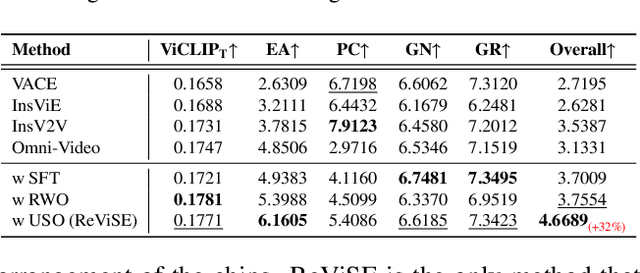
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
Dec 09, 2025We present Wan-Move, a simple and scalable framework that brings motion control to video generative models. Existing motion-controllable methods typically suffer from coarse control granularity and limited scalability, leaving their outputs insufficient for practical use. We narrow this gap by achieving precise and high-quality motion control. Our core idea is to directly make the original condition features motion-aware for guiding video synthesis. To this end, we first represent object motions with dense point trajectories, allowing fine-grained control over the scene. We then project these trajectories into latent space and propagate the first frame's features along each trajectory, producing an aligned spatiotemporal feature map that tells how each scene element should move. This feature map serves as the updated latent condition, which is naturally integrated into the off-the-shelf image-to-video model, e.g., Wan-I2V-14B, as motion guidance without any architecture change. It removes the need for auxiliary motion encoders and makes fine-tuning base models easily scalable. Through scaled training, Wan-Move generates 5-second, 480p videos whose motion controllability rivals Kling 1.5 Pro's commercial Motion Brush, as indicated by user studies. To support comprehensive evaluation, we further design MoveBench, a rigorously curated benchmark featuring diverse content categories and hybrid-verified annotations. It is distinguished by larger data volume, longer video durations, and high-quality motion annotations. Extensive experiments on MoveBench and the public dataset consistently show Wan-Move's superior motion quality. Code, models, and benchmark data are made publicly available.
Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
Jul 22, 2025
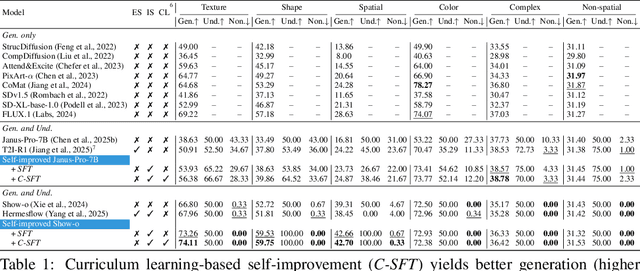
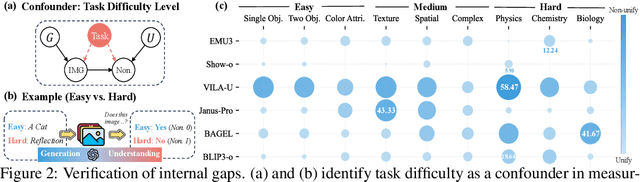

Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer
Apr 15, 2025


This report presents UniAnimate-DiT, an advanced project that leverages the cutting-edge and powerful capabilities of the open-source Wan2.1 model for consistent human image animation. Specifically, to preserve the robust generative capabilities of the original Wan2.1 model, we implement Low-Rank Adaptation (LoRA) technique to fine-tune a minimal set of parameters, significantly reducing training memory overhead. A lightweight pose encoder consisting of multiple stacked 3D convolutional layers is designed to encode motion information of driving poses. Furthermore, we adopt a simple concatenation operation to integrate the reference appearance into the model and incorporate the pose information of the reference image for enhanced pose alignment. Experimental results show that our approach achieves visually appearing and temporally consistent high-fidelity animations. Trained on 480p (832x480) videos, UniAnimate-DiT demonstrates strong generalization capabilities to seamlessly upscale to 720P (1280x720) during inference. The training and inference code is publicly available at https://github.com/ali-vilab/UniAnimate-DiT.