 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPI: Exploiting Parameter Heterogeneity for Interference-Free Fine-Tuning
Jan 25, 2026Supervised fine-tuning (SFT) is a crucial step for adapting large language models (LLMs) to downstream tasks. However, conflicting objectives across heterogeneous SFT tasks often induce the "seesaw effect": optimizing for one task may degrade performance on others, particularly when model parameters are updated indiscriminately. In this paper, we propose a principled approach to disentangle and isolate task-specific parameter regions, motivated by the hypothesis that parameter heterogeneity underlies cross-task interference. Specifically, we first independently fine-tune LLMs on diverse SFT tasks and identify each task's core parameter region as the subset of parameters exhibiting the largest updates. Tasks with highly overlapping core parameter regions are merged for joint training, while disjoint tasks are organized into different stages. During multi-stage SFT, core parameters acquired in prior tasks are frozen, thereby preventing overwriting by subsequent tasks. To verify the effectiveness of our method, we conducted intensive experiments on multiple public datasets. The results showed that our dynamic parameter isolation strategy consistently reduced data conflicts and achieved consistent performance improvements compared to multi-stage and multi-task tuning baselines.
Table-R1: Region-based Reinforcement Learning for Table Understanding
May 18, 2025Tables present unique challenges for language models due to their structured row-column interactions, necessitating specialized approaches for effective comprehension. While large language models (LLMs) have demonstrated potential in table reasoning through prompting and techniques like chain-of-thought (CoT) and program-of-thought (PoT), optimizing their performance for table question answering remains underexplored. In this paper, we introduce region-based Table-R1, a novel reinforcement learning approach that enhances LLM table understanding by integrating region evidence into reasoning steps. Our method employs Region-Enhanced Supervised Fine-Tuning (RE-SFT) to guide models in identifying relevant table regions before generating answers, incorporating textual, symbolic, and program-based reasoning. Additionally, Table-Aware Group Relative Policy Optimization (TARPO) introduces a mixed reward system to dynamically balance region accuracy and answer correctness, with decaying region rewards and consistency penalties to align reasoning steps. Experiments show that Table-R1 achieves an average performance improvement of 14.36 points across multiple base models on three benchmark datasets, even outperforming baseline models with ten times the parameters, while TARPO reduces response token consumption by 67.5% compared to GRPO, significantly advancing LLM capabilities in efficient tabular reasoning.
SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models
Feb 18, 2025The increasing application of multi-modal large language models (MLLMs) across various sectors have spotlighted the essence of their output reliability and accuracy, particularly their ability to produce content grounded in factual information (e.g. common and domain-specific knowledge). In this work, we introduce SimpleVQA, the first comprehensive multi-modal benchmark to evaluate the factuality ability of MLLMs to answer natural language short questions. SimpleVQA is characterized by six key features: it covers multiple tasks and multiple scenarios, ensures high quality and challenging queries, maintains static and timeless reference answers, and is straightforward to evaluate. Our approach involves categorizing visual question-answering items into 9 different tasks around objective events or common knowledge and situating these within 9 topics. Rigorous quality control processes are implemented to guarantee high-quality, concise, and clear answers, facilitating evaluation with minimal variance via an LLM-as-a-judge scoring system. Using SimpleVQA, we perform a comprehensive assessment of leading 18 MLLMs and 8 text-only LLMs, delving into their image comprehension and text generation abilities by identifying and analyzing error cases.
TableBench: A Comprehensive and Complex Benchmark for Table Question Answering
Aug 17, 2024Recent advancements in Large Language Models (LLMs) have markedly enhanced the interpretation and processing of tabular data, introducing previously unimaginable capabilities. Despite these achievements, LLMs still encounter significant challenges when applied in industrial scenarios, particularly due to the increased complexity of reasoning required with real-world tabular data, underscoring a notable disparity between academic benchmarks and practical applications. To address this discrepancy, we conduct a detailed investigation into the application of tabular data in industrial scenarios and propose a comprehensive and complex benchmark TableBench, including 18 fields within four major categories of table question answering (TableQA) capabilities. Furthermore, we introduce TableLLM, trained on our meticulously constructed training set TableInstruct, achieving comparable performance with GPT-3.5. Massive experiments conducted on TableBench indicate that both open-source and proprietary LLMs still have significant room for improvement to meet real-world demands, where the most advanced model, GPT-4, achieves only a modest score compared to humans.
Raw Text is All you Need: Knowledge-intensive Multi-turn Instruction Tuning for Large Language Model
Jul 03, 2024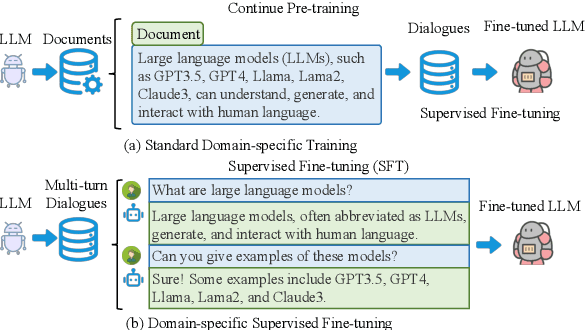



Instruction tuning as an effective technique aligns the outputs of large language models (LLMs) with human preference. But how to generate the seasonal multi-turn dialogues from raw documents for instruction tuning still requires further exploration. In this paper, we present a novel framework named R2S that leverages the CoD-Chain of Dialogue logic to guide large language models (LLMs) in generating knowledge-intensive multi-turn dialogues for instruction tuning. By integrating raw documents from both open-source datasets and domain-specific web-crawled documents into a benchmark K-BENCH, we cover diverse areas such as Wikipedia (English), Science (Chinese), and Artifacts (Chinese). Our approach first decides the logic flow of the current dialogue and then prompts LLMs to produce key phrases for sourcing relevant response content. This methodology enables the creation of the G I NSTRUCT instruction dataset, retaining raw document knowledge within dialoguestyle interactions. Utilizing this dataset, we fine-tune GLLM, a model designed to transform raw documents into structured multi-turn dialogues, thereby injecting comprehensive domain knowledge into the SFT model for enhanced instruction tuning. This work signifies a stride towards refining the adaptability and effectiveness of LLMs in processing and generating more accurate, contextually nuanced responses across various fields.
Unleashing Potential of Evidence in Knowledge-Intensive Dialogue Generation
Sep 15, 2023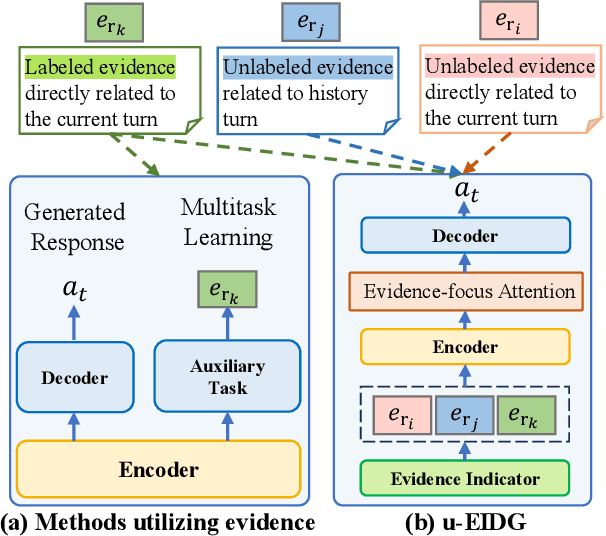



Incorporating external knowledge into dialogue generation (KIDG) is crucial for improving the correctness of response, where evidence fragments serve as knowledgeable snippets supporting the factual dialogue replies. However, introducing irrelevant content often adversely impacts reply quality and easily leads to hallucinated responses. Prior work on evidence retrieval and integration in dialogue systems falls short of fully leveraging existing evidence since the model fails to locate useful fragments accurately and overlooks hidden evidence labels within the KIDG dataset. To fully Unleash the potential of evidence, we propose a framework to effectively incorporate Evidence in knowledge-Intensive Dialogue Generation (u-EIDG). Specifically, we introduce an automatic evidence generation framework that harnesses the power of Large Language Models (LLMs) to mine reliable evidence veracity labels from unlabeled data. By utilizing these evidence labels, we train a reliable evidence indicator to effectively identify relevant evidence from retrieved passages. Furthermore, we propose an evidence-augmented generator with an evidence-focused attention mechanism, which allows the model to concentrate on evidenced segments. Experimental results on MultiDoc2Dial demonstrate the efficacy of evidential label augmentation and refined attention mechanisms in improving model performance. Further analysis confirms that the proposed method outperforms other baselines (+3~+5 points) regarding coherence and factual consistency.