 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRescueBench: Can Embodied Agents Save Lives in the Wild ?
Jun 01, 2026Search-and-rescue (SAR) requires embodied agents to explore unfamiliar environments under multimodal uncertainty, perform multi-stage interactions, and retrieve spatial memory over long horizons. Existing benchmarks typically evaluate these capabilities in isolation, leaving unclear how failures compound when they must be composed in realistic workflows. We introduce RescueBench, a photo-realistic diagnostic benchmark that instantiates SAR as a four-stage pipeline: multimodal exploration, target rescue, memory-guided return, and final handoff. By combining sequential task composition with stage-level evaluation, RescueBench enables analysis of how exploration and memory failures propagate through embodied rescue workflows. It contains five progressive difficulty levels that vary in environmental complexity, clue ambiguity, and spatial hierarchy, along with an automatic episode generation and annotation pipeline for scalable evaluation and training. We evaluate seven baselines, an oracle reference, and human players, showing that no baselines complete the full task at the greatest difficulty. Stage-level diagnosis identifies autonomous exploration as the dominant failure mode and spatial memory as a second, independent bottleneck, suggesting that these limitations are not resolved by current topological visual-language navigation or map-based methods. Code is available in https://github.com/wukui-muc/RescueBench
Beyond Input Understanding: Diagnosing Multilingual Mathematical Reasoning with Directed Acyclic Trace Graphs
May 26, 2026Large reasoning models (LRMs) achieve strong mathematical reasoning performance in English, but remain much less reliable in many low- and medium-resource languages. This gap is often explained as a failure to understand non-English problem statements. We show that this view is incomplete: even when the problem is given in English, controlling the model's reasoning language can substantially reduce accuracy, suggesting that language also affects reasoning execution itself. To study this effect, we introduce DATG, a Directed Acyclic Trace Graph framework that maps reasoning traces to language-independent mathematical anchors and dependencies. This allows us to align target-language traces with reference DAGs and measure whether they cover required mathematical nodes, respect dependency edges, and avoid harmful mathematical actions. Experiments on the Qwen3 series across 12 languages show that non-English reasoning often suffers from reduced anchor coverage and weaker dependency fidelity, especially in low-resource languages. Motivated by this diagnosis, we propose Loop-Retry and Formula-Retry, two simple test-time controls targeting DATG-exposed failure modes, and show that they consistently improve target-language reasoning performance in low-resource languages.
AdaTracker: Learning Adaptive In-Context Policy for Cross-Embodiment Active Visual Tracking
Apr 22, 2026Realizing active visual tracking with a single unified model across diverse robots is challenging, as the physical constraints and motion dynamics vary drastically from one platform to another. Existing approaches typically train separate models for each embodiment, leading to poor scalability and limited generalization. To address this, we propose AdaTracker, an adaptive in-context policy learning framework that robustly tracks targets on diverse robot morphologies. Our key insight is to explicitly model embodiment-specific constraints through an Embodiment Context Encoder, which infers embodiment-specific constraints from history. This contextual representation dynamically modulates a Context-Aware Policy, enabling it to infer optimal control actions for unseen embodiments in a zero-shot manner. To enhance robustness, we introduce two auxiliary objectives to ensure accurate context identification and temporal consistency. Experiments in both simulation and the real world demonstrate that AdaTracker significantly outperforms state-of-the-art methods in cross-embodiment generalization, sample efficiency, and zero-shot adaptation.
PilotBench: A Benchmark for General Aviation Agents with Safety Constraints
Apr 10, 2026As Large Language Models (LLMs) advance toward embodied AI agents operating in physical environments, a fundamental question emerges: can models trained on text corpora reliably reason about complex physics while adhering to safety constraints? We address this through PilotBench, a benchmark evaluating LLMs on safety-critical flight trajectory and attitude prediction. Built from 708 real-world general aviation trajectories spanning nine operationally distinct flight phases with synchronized 34-channel telemetry, PilotBench systematically probes the intersection of semantic understanding and physics-governed prediction through comparative analysis of LLMs and traditional forecasters. We introduce Pilot-Score, a composite metric balancing 60% regression accuracy with 40% instruction adherence and safety compliance. Comparative evaluation across 41 models uncovers a Precision-Controllability Dichotomy: traditional forecasters achieve superior MAE of 7.01 but lack semantic reasoning capabilities, while LLMs gain controllability with 86--89% instruction-following at the cost of 11--14 MAE precision. Phase-stratified analysis further exposes a Dynamic Complexity Gap-LLM performance degrades sharply in high-workload phases such as Climb and Approach, suggesting brittle implicit physics models. These empirical discoveries motivate hybrid architectures combining LLMs' symbolic reasoning with specialized forecasters' numerical precision. PilotBench provides a rigorous foundation for advancing embodied AI in safety-constrained domains.
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
M2G-Eval: Enhancing and Evaluating Multi-granularity Multilingual Code Generation
Dec 27, 2025The rapid advancement of code large language models (LLMs) has sparked significant research interest in systematically evaluating their code generation capabilities, yet existing benchmarks predominantly assess models at a single structural granularity and focus on limited programming languages, obscuring fine-grained capability variations across different code scopes and multilingual scenarios. We introduce M2G-Eval, a multi-granularity, multilingual framework for evaluating code generation in large language models (LLMs) across four levels: Class, Function, Block, and Line. Spanning 18 programming languages, M2G-Eval includes 17K+ training tasks and 1,286 human-annotated, contamination-controlled test instances. We develop M2G-Eval-Coder models by training Qwen3-8B with supervised fine-tuning and Group Relative Policy Optimization. Evaluating 30 models (28 state-of-the-art LLMs plus our two M2G-Eval-Coder variants) reveals three main findings: (1) an apparent difficulty hierarchy, with Line-level tasks easiest and Class-level most challenging; (2) widening performance gaps between full- and partial-granularity languages as task complexity increases; and (3) strong cross-language correlations, suggesting that models learn transferable programming concepts. M2G-Eval enables fine-grained diagnosis of code generation capabilities and highlights persistent challenges in synthesizing complex, long-form code.
CodeSimpleQA: Scaling Factuality in Code Large Language Models
Dec 22, 2025Large language models (LLMs) have made significant strides in code generation, achieving impressive capabilities in synthesizing code snippets from natural language instructions. However, a critical challenge remains in ensuring LLMs generate factually accurate responses about programming concepts, technical implementations, etc. Most previous code-related benchmarks focus on code execution correctness, overlooking the factual accuracy of programming knowledge. To address this gap, we present CodeSimpleQA, a comprehensive bilingual benchmark designed to evaluate the factual accuracy of code LLMs in answering code-related questions, which contains carefully curated question-answer pairs in both English and Chinese, covering diverse programming languages and major computer science domains. Further, we create CodeSimpleQA-Instruct, a large-scale instruction corpus with 66M samples, and develop a post-training framework combining supervised fine-tuning and reinforcement learning. Our comprehensive evaluation of diverse LLMs reveals that even frontier LLMs struggle with code factuality. Our proposed framework demonstrates substantial improvements over the base model, underscoring the critical importance of factuality-aware alignment in developing reliable code LLMs.
UCoder: Unsupervised Code Generation by Internal Probing of Large Language Models
Dec 19, 2025
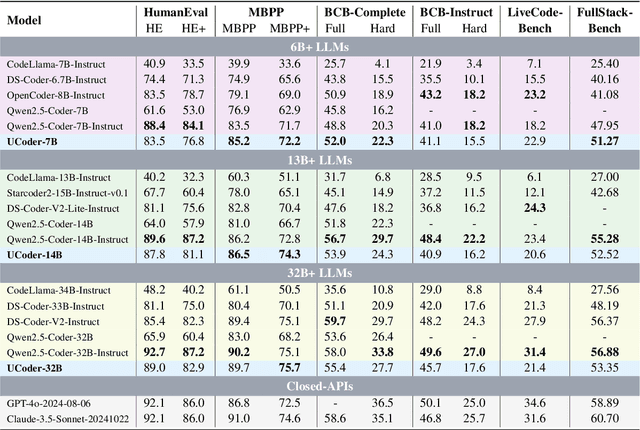
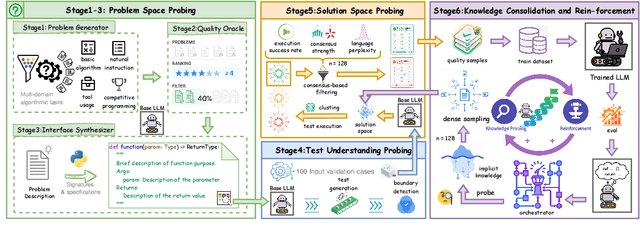
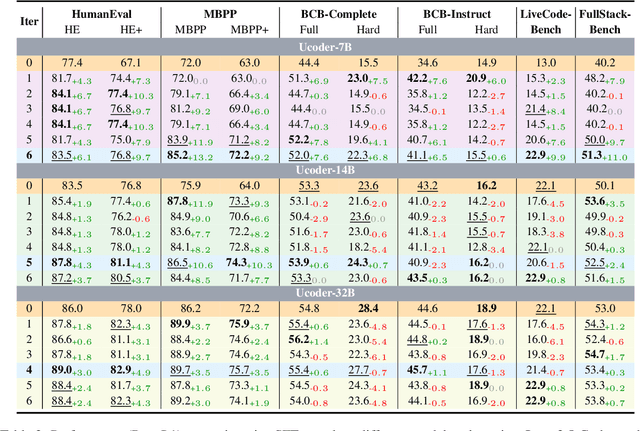
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, their effectiveness heavily relies on supervised training with extensive labeled (e.g., question-answering pairs) or unlabeled datasets (e.g., code snippets), which are often expensive and difficult to obtain at scale. To address this limitation, this paper introduces a method IPC, an unsupervised framework that leverages Internal Probing of LLMs for Code generation without any external corpus, even unlabeled code snippets. We introduce the problem space probing, test understanding probing, solution space probing, and knowledge consolidation and reinforcement to probe the internal knowledge and confidence patterns existing in LLMs. Further, IPC identifies reliable code candidates through self-consistency mechanisms and representation-based quality estimation to train UCoder (coder with unsupervised learning). We validate the proposed approach across multiple code benchmarks, demonstrating that unsupervised methods can achieve competitive performance compared to supervised approaches while significantly reducing the dependency on labeled data and computational resources. Analytic experiments reveal that internal model states contain rich signals about code quality and correctness, and that properly harnessing these signals enables effective unsupervised learning for code generation tasks, opening new directions for training code LLMs in resource-constrained scenarios.
Scaling Laws for Code: Every Programming Language Matters
Dec 15, 2025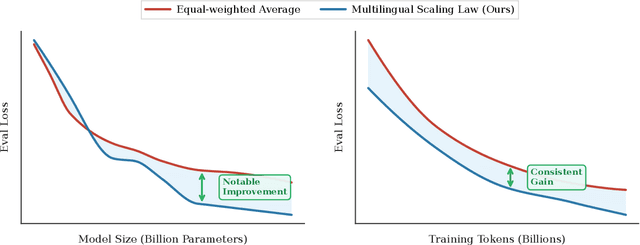

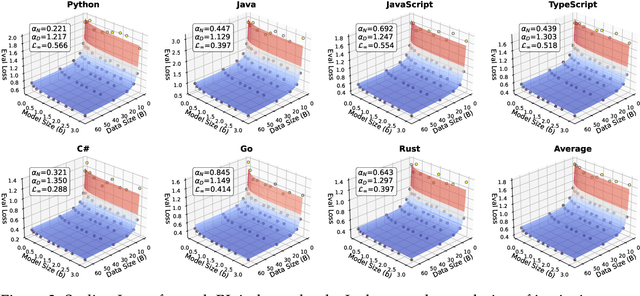

Code large language models (Code LLMs) are powerful but costly to train, with scaling laws predicting performance from model size, data, and compute. However, different programming languages (PLs) have varying impacts during pre-training that significantly affect base model performance, leading to inaccurate performance prediction. Besides, existing works focus on language-agnostic settings, neglecting the inherently multilingual nature of modern software development. Therefore, it is first necessary to investigate the scaling laws of different PLs, and then consider their mutual influences to arrive at the final multilingual scaling law. In this paper, we present the first systematic exploration of scaling laws for multilingual code pre-training, conducting over 1000+ experiments (Equivalent to 336,000+ H800 hours) across multiple PLs, model sizes (0.2B to 14B parameters), and dataset sizes (1T tokens). We establish comprehensive scaling laws for code LLMs across multiple PLs, revealing that interpreted languages (e.g., Python) benefit more from increased model size and data than compiled languages (e.g., Rust). The study demonstrates that multilingual pre-training provides synergistic benefits, particularly between syntactically similar PLs. Further, the pre-training strategy of the parallel pairing (concatenating code snippets with their translations) significantly enhances cross-lingual abilities with favorable scaling properties. Finally, a proportion-dependent multilingual scaling law is proposed to optimally allocate training tokens by prioritizing high-utility PLs (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and reducing allocation to fast-saturating languages (Rust), achieving superior average performance across all PLs compared to uniform distribution under the same compute budget.