 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are they talking about? Benchmarking Large Language Models for Knowledge-Grounded Discussion Summarization
May 18, 2025In this work, we investigate the performance of LLMs on a new task that requires combining discussion with background knowledge for summarization. This aims to address the limitation of outside observer confusion in existing dialogue summarization systems due to their reliance solely on discussion information. To achieve this, we model the task output as background and opinion summaries and define two standardized summarization patterns. To support assessment, we introduce the first benchmark comprising high-quality samples consistently annotated by human experts and propose a novel hierarchical evaluation framework with fine-grained, interpretable metrics. We evaluate 12 LLMs under structured-prompt and self-reflection paradigms. Our findings reveal: (1) LLMs struggle with background summary retrieval, generation, and opinion summary integration. (2) Even top LLMs achieve less than 69% average performance across both patterns. (3) Current LLMs lack adequate self-evaluation and self-correction capabilities for this task.
SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models
Feb 18, 2025The increasing application of multi-modal large language models (MLLMs) across various sectors have spotlighted the essence of their output reliability and accuracy, particularly their ability to produce content grounded in factual information (e.g. common and domain-specific knowledge). In this work, we introduce SimpleVQA, the first comprehensive multi-modal benchmark to evaluate the factuality ability of MLLMs to answer natural language short questions. SimpleVQA is characterized by six key features: it covers multiple tasks and multiple scenarios, ensures high quality and challenging queries, maintains static and timeless reference answers, and is straightforward to evaluate. Our approach involves categorizing visual question-answering items into 9 different tasks around objective events or common knowledge and situating these within 9 topics. Rigorous quality control processes are implemented to guarantee high-quality, concise, and clear answers, facilitating evaluation with minimal variance via an LLM-as-a-judge scoring system. Using SimpleVQA, we perform a comprehensive assessment of leading 18 MLLMs and 8 text-only LLMs, delving into their image comprehension and text generation abilities by identifying and analyzing error cases.
XFormParser: A Simple and Effective Multimodal Multilingual Semi-structured Form Parser
May 27, 2024In the domain of document AI, semi-structured form parsing plays a crucial role. This task leverages techniques from key information extraction (KIE), dealing with inputs that range from plain text to intricate modal data comprising images and structural layouts. The advent of pre-trained multimodal models has driven the extraction of key information from form documents in different formats such as PDFs and images. Nonetheless, the endeavor of form parsing is still encumbered by notable challenges like subpar capabilities in multi-lingual parsing and diminished recall in contexts rich in text and visuals. In this work, we introduce a simple but effective \textbf{M}ultimodal and \textbf{M}ultilingual semi-structured \textbf{FORM} \textbf{PARSER} (\textbf{XFormParser}), which is anchored on a comprehensive pre-trained language model and innovatively amalgamates semantic entity recognition (SER) and relation extraction (RE) into a unified framework, enhanced by a novel staged warm-up training approach that employs soft labels to significantly refine form parsing accuracy without amplifying inference overhead. Furthermore, we have developed a groundbreaking benchmark dataset, named InDFormBench, catering specifically to the parsing requirements of multilingual forms in various industrial contexts. Through rigorous testing on established multilingual benchmarks and InDFormBench, XFormParser has demonstrated its unparalleled efficacy, notably surpassing the state-of-the-art (SOTA) models in RE tasks within language-specific setups by achieving an F1 score improvement of up to 1.79\%. Our framework exhibits exceptionally improved performance across tasks in both multi-language and zero-shot contexts when compared to existing SOTA benchmarks. The code is publicly available at https://github.com/zhbuaa0/layoutlmft.
VIPTR: A Vision Permutable Extractor for Fast and Efficient Scene Text Recognition
Jan 24, 2024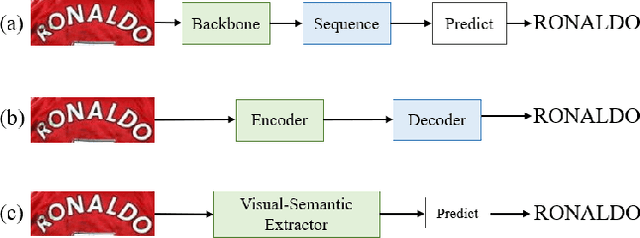
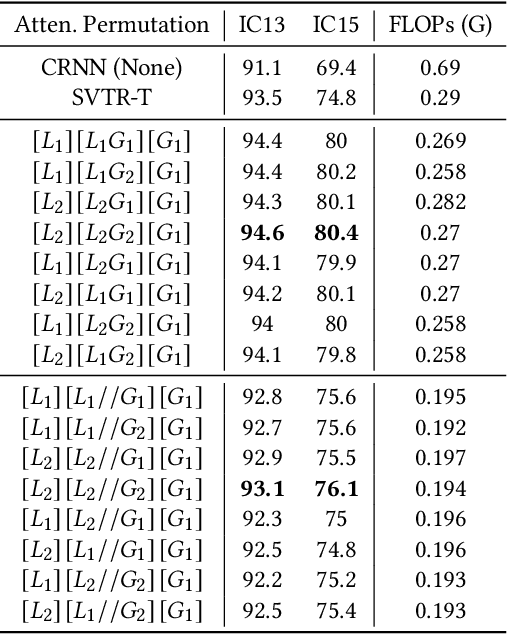
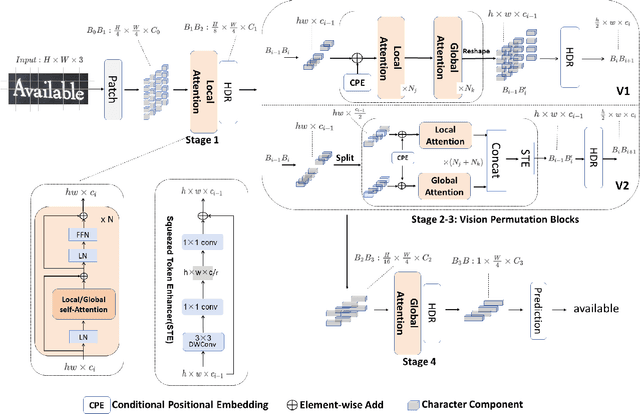
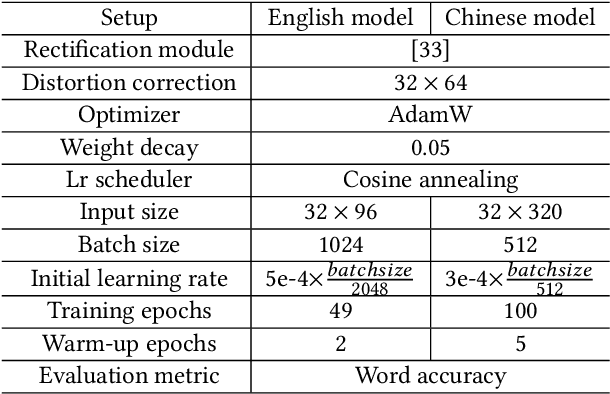
Scene Text Recognition (STR) is a challenging task that involves recognizing text within images of natural scenes. Although current state-of-the-art models for STR exhibit high performance, they typically suffer from low inference efficiency due to their reliance on hybrid architectures comprised of visual encoders and sequence decoders. In this work, we propose the VIsion Permutable extractor for fast and efficient scene Text Recognition (VIPTR), which achieves an impressive balance between high performance and rapid inference speeds in the domain of STR. Specifically, VIPTR leverages a visual-semantic extractor with a pyramid structure, characterized by multiple self-attention layers, while eschewing the traditional sequence decoder. This design choice results in a lightweight and efficient model capable of handling inputs of varying sizes. Extensive experimental results on various standard datasets for both Chinese and English scene text recognition validate the superiority of VIPTR. Notably, the VIPTR-T (Tiny) variant delivers highly competitive accuracy on par with other lightweight models and achieves SOTA inference speeds. Meanwhile, the VIPTR-L (Large) variant attains greater recognition accuracy, while maintaining a low parameter count and favorable inference speed. Our proposed method provides a compelling solution for the STR challenge, which blends high accuracy with efficiency and greatly benefits real-world applications requiring fast and reliable text recognition. The code is publicly available at https://github.com/cxfyxl/VIPTR.
Multi-Stage Pre-training Enhanced by ChatGPT for Multi-Scenario Multi-Domain Dialogue Summarization
Oct 16, 2023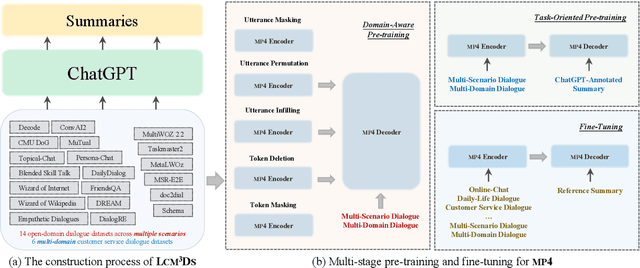

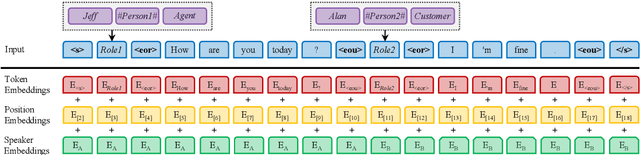
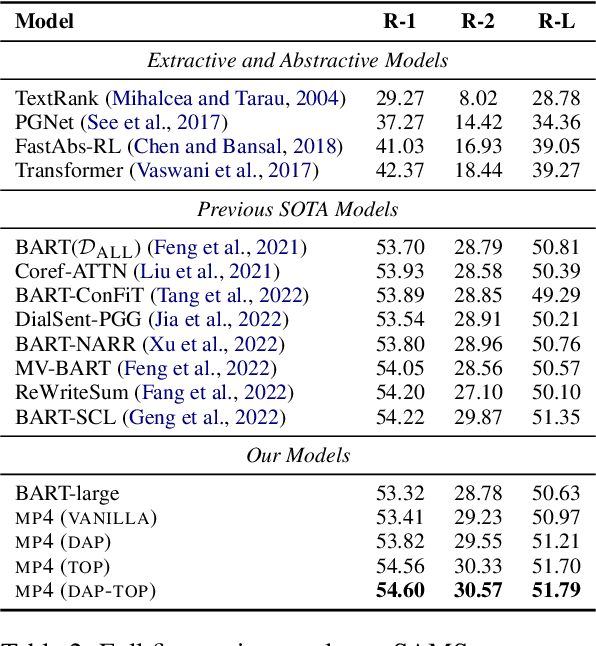
Dialogue summarization involves a wide range of scenarios and domains. However, existing methods generally only apply to specific scenarios or domains. In this study, we propose a new pre-trained model specifically designed for multi-scenario multi-domain dialogue summarization. It adopts a multi-stage pre-training strategy to reduce the gap between the pre-training objective and fine-tuning objective. Specifically, we first conduct domain-aware pre-training using large-scale multi-scenario multi-domain dialogue data to enhance the adaptability of our pre-trained model. Then, we conduct task-oriented pre-training using large-scale multi-scenario multi-domain "dialogue-summary" parallel data annotated by ChatGPT to enhance the dialogue summarization ability of our pre-trained model. Experimental results on three dialogue summarization datasets from different scenarios and domains indicate that our pre-trained model significantly outperforms previous state-of-the-art models in full fine-tuning, zero-shot, and few-shot settings.