 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Multi-Dimensional Empirical Study of LLMs for Conversation Summarization
Jun 14, 2026Despite the significant advancement of LLMs in conversation summarization, their evaluation remains limited by insufficient scenarios, input lengths, and sample sizes. Furthermore, existing benchmarks often omit frontier reasoning systems and efficient small models, or lack fine-grained, multi-dimensional assessments. To bridge these gaps, we propose OmniCSEval, a unified benchmark comprising 1,800 diverse conversations across six real-world scenarios, featuring context lengths ranging from 128 to 32k tokens. For fine-grained evaluation, we employ a bidirectional fact-checking framework that integrates key fact matching to assess completeness and conciseness, alongside summary fact verification to evaluate faithfulness. To ensure reliable assessment, we establish a human-LLM collaborative pipeline for key fact extraction and a multi-LLM consensus verifier for summary fact decomposition. Leveraging this framework, we evaluate 28 LLMs across four distinct categories grouped by reasoning capability and model scale. Our extensive empirical study reveals critical insights regarding the cross-scenario challenges current LLMs continue to face, the impacts of reasoning and scale, and the efficiency and adaptability of reasoning models. We also provide guidance for system selection in real-world deployments.
NeuroArmor: Safe-Variant-Guided Representation Consistency for Selective Re-Anchoring in Jailbreak Defense
Jun 02, 2026Large language models remain vulnerable to jailbreak attacks that hide harmful intent behind seemingly ordinary requests such as role-play, translation, encoding, adversarial suffixes, and multi-turn buildup. Existing defenses still struggle to handle these attacks without over-blocking benign but sensitive requests, partly because they often apply the same action to every prompt and therefore fail to balance safety and helpfulness. We propose NeuroArmor, a white-box runtime defense that uses prompt-specific safe variants as a local safety reference for deciding when intervention is needed and, once triggered, as safe targets for intervention. For each prompt, NeuroArmor builds K safe variants, compares the prompt state against this local safe reference in hidden-state space, and routes anomalies either to a refusal branch for malicious prompts or to a helpful recovery branch for borderline benign prompts. On Llama-3-8B-Instruct, NeuroArmor reduces malicious attack success rate (ASR) from 41.56% to 1.57% while lowering benign false positive rate (FPR) on the shared benign pool from 30.26% to 22.05%; matched baselines remain substantially weaker on this trade-off. External-judge and manual behavioral evaluations further show that the remaining non-blocked outputs are much less likely to be operationally harmful. Overall, NeuroArmor provides a more effective runtime strategy for jailbreak defense by combining prompt-specific consistency checking, routing, and selective intervention.
PromptDLA: A Domain-aware Prompt Document Layout Analysis Framework with Descriptive Knowledge as a Cue
Mar 10, 2026Document Layout Analysis (DLA) is crucial for document artificial intelligence and has recently received increasing attention, resulting in an influx of large-scale public DLA datasets. Existing work often combines data from various domains in recent public DLA datasets to improve the generalization of DLA. However, directly merging these datasets for training often results in suboptimal model performance, as it overlooks the different layout structures inherent to various domains. These variations include different labeling styles, document types, and languages. This paper introduces PromptDLA, a domain-aware Prompter for Document Layout Analysis that effectively leverages descriptive knowledge as cues to integrate domain priors into DLA. The innovative PromptDLA features a unique domain-aware prompter that customizes prompts based on the specific attributes of the data domain. These prompts then serve as cues that direct the DLA toward critical features and structures within the data, enhancing the model's ability to generalize across varied domains. Extensive experiments show that our proposal achieves state-of-the-art performance among DocLayNet, PubLayNet, M6Doc, and D$^4$LA. Our code is available at https://github.com/Zirui00/PromptDLA.
CROP: Contextual Region-Oriented Visual Token Pruning
May 27, 2025



Current VLM-based VQA methods often process entire images, leading to excessive visual tokens that include redundant information irrelevant to the posed question. This abundance of unnecessary image details creates numerous visual tokens, drastically increasing memory and computational requirements in VLMs. To address this, we propose Contextual Region-Oriented Visual Token Pruning (CROP), a novel framework to compress visual tokens through a two-step process: Localization and Pruning. Specifically, CROP first employs an efficient model to identify the contextual region relevant to the input query. Subsequently, two distinct strategies are introduced for pruning: (1) Pre-LLM Compression (PLC), which adaptively compresses different image regions with varying ratios, and (2) Inner-LLM Pruning (ILP), a training-free method that prunes tokens within early LLM layers guided by the identified contextual region. Extensive experiments on a wide range of VQA tasks demonstrate that CROP significantly outperforms existing visual token pruning methods and achieves state-of-the-art performance. Our code and datasets will be made available.
What are they talking about? Benchmarking Large Language Models for Knowledge-Grounded Discussion Summarization
May 18, 2025In this work, we investigate the performance of LLMs on a new task that requires combining discussion with background knowledge for summarization. This aims to address the limitation of outside observer confusion in existing dialogue summarization systems due to their reliance solely on discussion information. To achieve this, we model the task output as background and opinion summaries and define two standardized summarization patterns. To support assessment, we introduce the first benchmark comprising high-quality samples consistently annotated by human experts and propose a novel hierarchical evaluation framework with fine-grained, interpretable metrics. We evaluate 12 LLMs under structured-prompt and self-reflection paradigms. Our findings reveal: (1) LLMs struggle with background summary retrieval, generation, and opinion summary integration. (2) Even top LLMs achieve less than 69% average performance across both patterns. (3) Current LLMs lack adequate self-evaluation and self-correction capabilities for this task.
TROVE: A Challenge for Fine-Grained Text Provenance via Source Sentence Tracing and Relationship Classification
Mar 19, 2025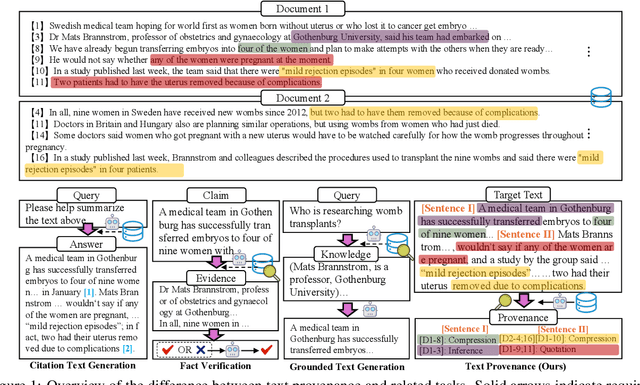
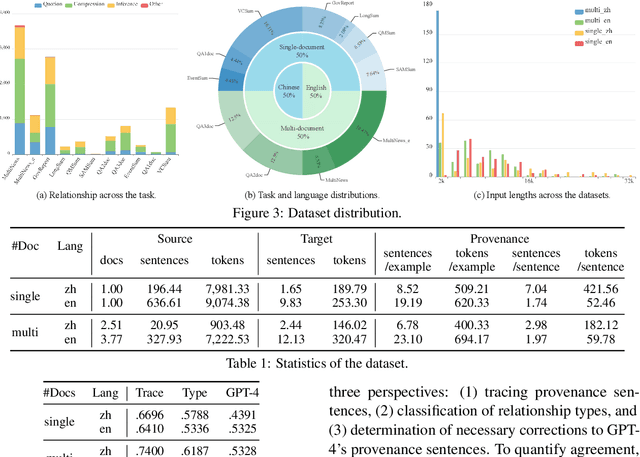
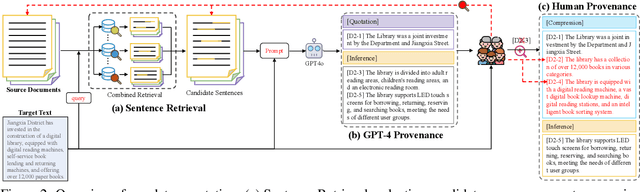
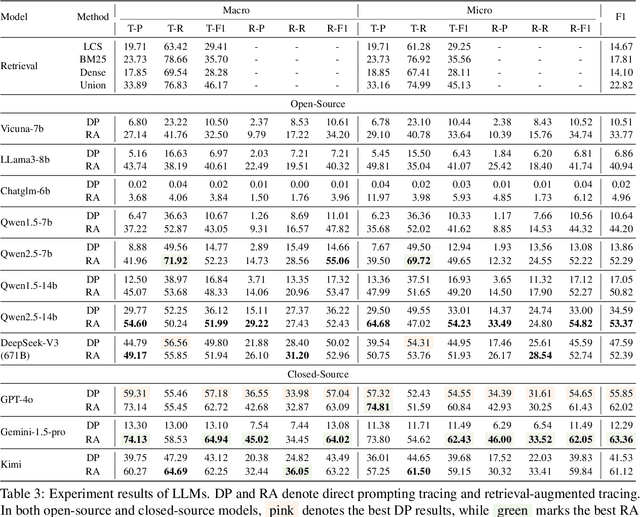
LLMs have achieved remarkable fluency and coherence in text generation, yet their widespread adoption has raised concerns about content reliability and accountability. In high-stakes domains such as healthcare, law, and news, it is crucial to understand where and how the content is created. To address this, we introduce the Text pROVEnance (TROVE) challenge, designed to trace each sentence of a target text back to specific source sentences within potentially lengthy or multi-document inputs. Beyond identifying sources, TROVE annotates the fine-grained relationships (quotation, compression, inference, and others), providing a deep understanding of how each target sentence is formed. To benchmark TROVE, we construct our dataset by leveraging three public datasets covering 11 diverse scenarios (e.g., QA and summarization) in English and Chinese, spanning source texts of varying lengths (0-5k, 5-10k, 10k+), emphasizing the multi-document and long-document settings essential for provenance. To ensure high-quality data, we employ a three-stage annotation process: sentence retrieval, GPT provenance, and human provenance. We evaluate 11 LLMs under direct prompting and retrieval-augmented paradigms, revealing that retrieval is essential for robust performance, larger models perform better in complex relationship classification, and closed-source models often lead, yet open-source models show significant promise, particularly with retrieval augmentation.
Multi-Stage Pre-training Enhanced by ChatGPT for Multi-Scenario Multi-Domain Dialogue Summarization
Oct 16, 2023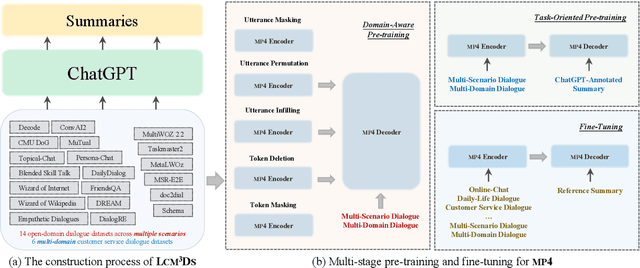

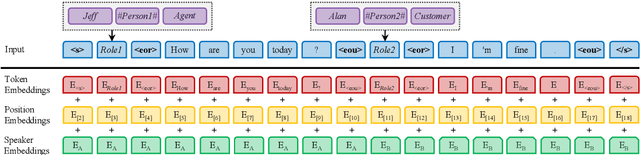
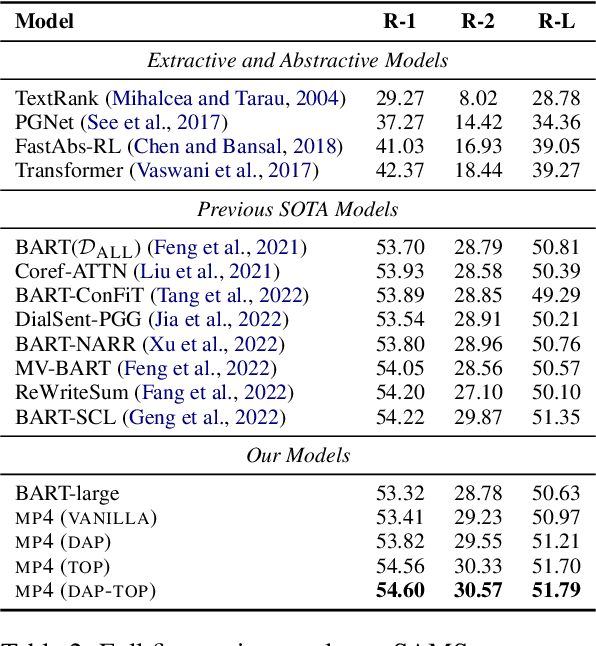
Dialogue summarization involves a wide range of scenarios and domains. However, existing methods generally only apply to specific scenarios or domains. In this study, we propose a new pre-trained model specifically designed for multi-scenario multi-domain dialogue summarization. It adopts a multi-stage pre-training strategy to reduce the gap between the pre-training objective and fine-tuning objective. Specifically, we first conduct domain-aware pre-training using large-scale multi-scenario multi-domain dialogue data to enhance the adaptability of our pre-trained model. Then, we conduct task-oriented pre-training using large-scale multi-scenario multi-domain "dialogue-summary" parallel data annotated by ChatGPT to enhance the dialogue summarization ability of our pre-trained model. Experimental results on three dialogue summarization datasets from different scenarios and domains indicate that our pre-trained model significantly outperforms previous state-of-the-art models in full fine-tuning, zero-shot, and few-shot settings.
Life-long Learning for Multilingual Neural Machine Translation with Knowledge Distillation
Dec 06, 2022
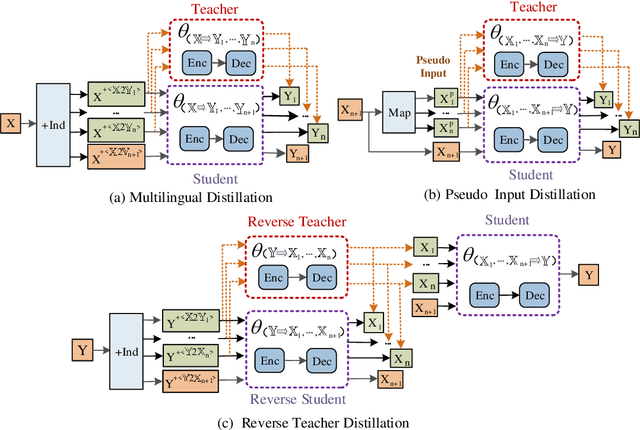
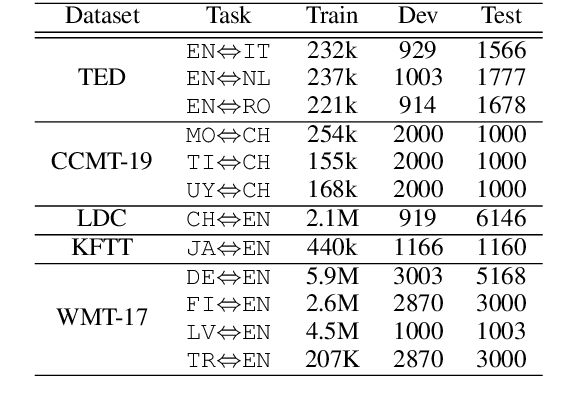
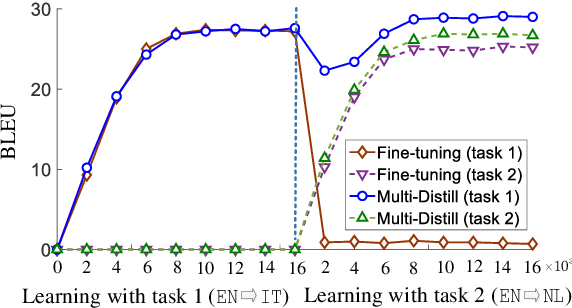
A common scenario of Multilingual Neural Machine Translation (MNMT) is that each translation task arrives in a sequential manner, and the training data of previous tasks is unavailable. In this scenario, the current methods suffer heavily from catastrophic forgetting (CF). To alleviate the CF, we investigate knowledge distillation based life-long learning methods. Specifically, in one-tomany scenario, we propose a multilingual distillation method to make the new model (student) jointly learn multilingual output from old model (teacher) and new task. In many-to one scenario, we find that direct distillation faces the extreme partial distillation problem, and we propose two different methods to address it: pseudo input distillation and reverse teacher distillation. The experimental results on twelve translation tasks show that the proposed methods can better consolidate the previous knowledge and sharply alleviate the CF.
Neural Models for Sequence Chunking
Jan 15, 2017
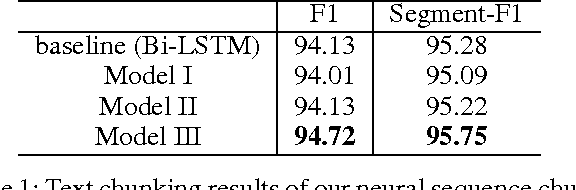
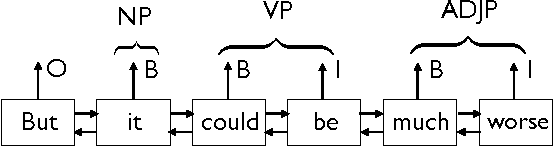

Many natural language understanding (NLU) tasks, such as shallow parsing (i.e., text chunking) and semantic slot filling, require the assignment of representative labels to the meaningful chunks in a sentence. Most of the current deep neural network (DNN) based methods consider these tasks as a sequence labeling problem, in which a word, rather than a chunk, is treated as the basic unit for labeling. These chunks are then inferred by the standard IOB (Inside-Outside-Beginning) labels. In this paper, we propose an alternative approach by investigating the use of DNN for sequence chunking, and propose three neural models so that each chunk can be treated as a complete unit for labeling. Experimental results show that the proposed neural sequence chunking models can achieve start-of-the-art performance on both the text chunking and slot filling tasks.
SummaRuNNer: A Recurrent Neural Network based Sequence Model for Extractive Summarization of Documents
Nov 14, 2016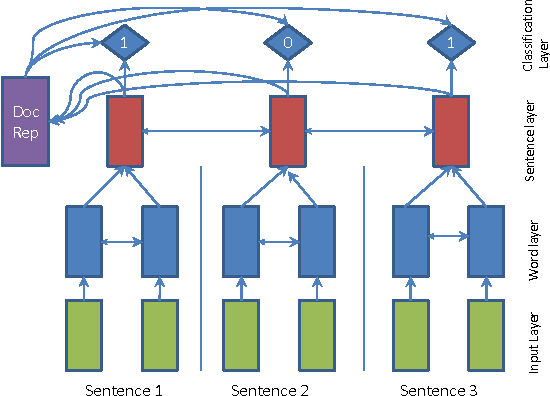
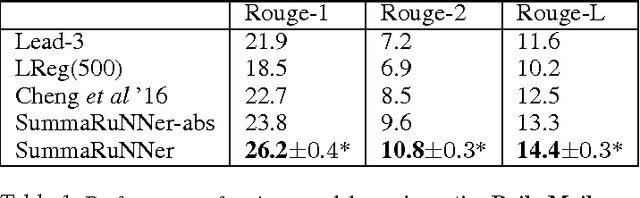

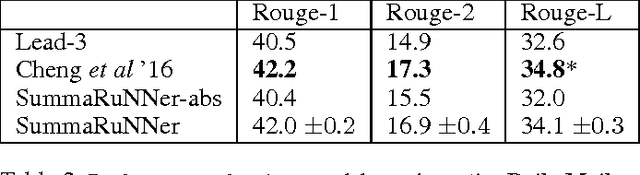
We present SummaRuNNer, a Recurrent Neural Network (RNN) based sequence model for extractive summarization of documents and show that it achieves performance better than or comparable to state-of-the-art. Our model has the additional advantage of being very interpretable, since it allows visualization of its predictions broken up by abstract features such as information content, salience and novelty. Another novel contribution of our work is abstractive training of our extractive model that can train on human generated reference summaries alone, eliminating the need for sentence-level extractive labels.