 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Jun 18, 2025Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought (Long CoT) reasoning have demonstrated remarkable cross-domain generalization capabilities. However, the underlying mechanisms supporting such transfer remain poorly understood. We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes -- fundamental reasoning patterns that capture the essence of problems across domains. These prototypes minimize the nuances of the representation, revealing that seemingly diverse tasks are grounded in shared reasoning structures.Based on this hypothesis, we propose ProtoReasoning, a framework that enhances the reasoning ability of LLMs by leveraging scalable and verifiable prototypical representations (Prolog for logical reasoning, PDDL for planning).ProtoReasoning features: (1) an automated prototype construction pipeline that transforms problems into corresponding prototype representations; (2) a comprehensive verification system providing reliable feedback through Prolog/PDDL interpreters; (3) the scalability to synthesize problems arbitrarily within prototype space while ensuring correctness. Extensive experiments show that ProtoReasoning achieves 4.7% improvement over baseline models on logical reasoning (Enigmata-Eval), 6.3% improvement on planning tasks, 4.0% improvement on general reasoning (MMLU) and 1.0% on mathematics (AIME24). Significantly, our ablation studies confirm that learning in prototype space also demonstrates enhanced generalization to structurally similar problems compared to training solely on natural language representations, validating our hypothesis that reasoning prototypes serve as the foundation for generalizable reasoning in large language models.
What are they talking about? Benchmarking Large Language Models for Knowledge-Grounded Discussion Summarization
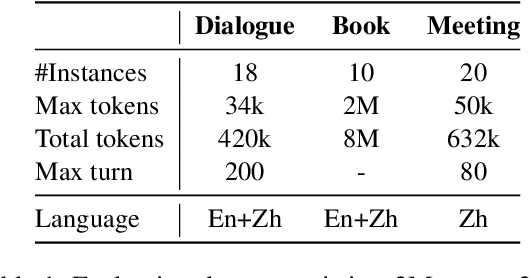
May 18, 2025In this work, we investigate the performance of LLMs on a new task that requires combining discussion with background knowledge for summarization. This aims to address the limitation of outside observer confusion in existing dialogue summarization systems due to their reliance solely on discussion information. To achieve this, we model the task output as background and opinion summaries and define two standardized summarization patterns. To support assessment, we introduce the first benchmark comprising high-quality samples consistently annotated by human experts and propose a novel hierarchical evaluation framework with fine-grained, interpretable metrics. We evaluate 12 LLMs under structured-prompt and self-reflection paradigms. Our findings reveal: (1) LLMs struggle with background summary retrieval, generation, and opinion summary integration. (2) Even top LLMs achieve less than 69% average performance across both patterns. (3) Current LLMs lack adequate self-evaluation and self-correction capabilities for this task.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
m3P: Towards Multimodal Multilingual Translation with Multimodal Prompt
Mar 26, 2024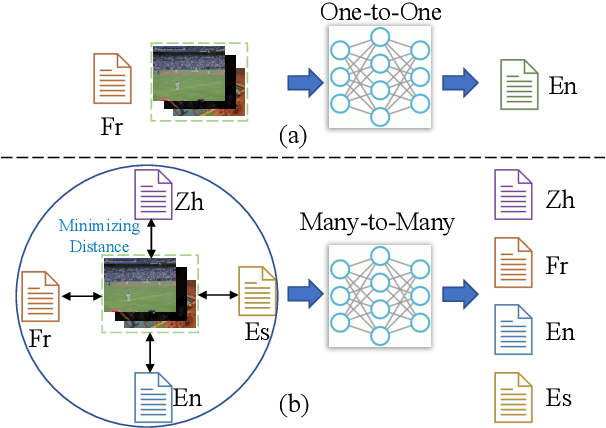
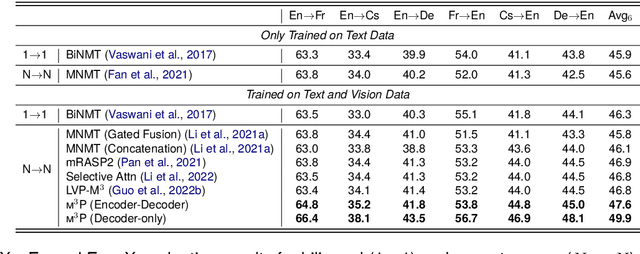
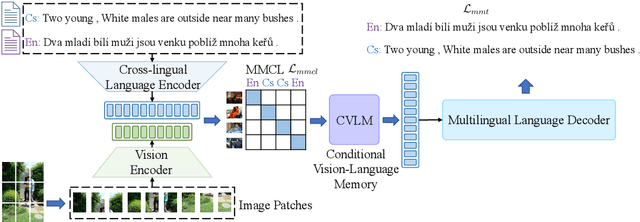
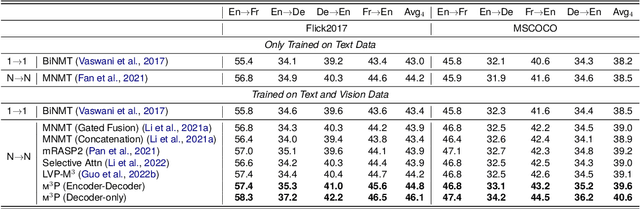
Multilingual translation supports multiple translation directions by projecting all languages in a shared space, but the translation quality is undermined by the difference between languages in the text-only modality, especially when the number of languages is large. To bridge this gap, we introduce visual context as the universal language-independent representation to facilitate multilingual translation. In this paper, we propose a framework to leverage the multimodal prompt to guide the Multimodal Multilingual neural Machine Translation (m3P), which aligns the representations of different languages with the same meaning and generates the conditional vision-language memory for translation. We construct a multilingual multimodal instruction dataset (InstrMulti102) to support 102 languages. Our method aims to minimize the representation distance of different languages by regarding the image as a central language. Experimental results show that m3P outperforms previous text-only baselines and multilingual multimodal methods by a large margin. Furthermore, the probing experiments validate the effectiveness of our method in enhancing translation under the low-resource and massively multilingual scenario.
Mitigating Catastrophic Forgetting in Multi-domain Chinese Spelling Correction by Multi-stage Knowledge Transfer Framework
Feb 18, 2024Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in given sentences. Recently, multi-domain CSC has gradually attracted the attention of researchers because it is more practicable. In this paper, we focus on the key flaw of the CSC model when adapting to multi-domain scenarios: the tendency to forget previously acquired knowledge upon learning new domain-specific knowledge (i.e., catastrophic forgetting). To address this, we propose a novel model-agnostic Multi-stage Knowledge Transfer (MKT) framework, which utilizes a continuously evolving teacher model for knowledge transfer in each domain, rather than focusing solely on new domain knowledge. It deserves to be mentioned that we are the first to apply continual learning methods to the multi-domain CSC task. Experiments prove the effectiveness of our proposed method, and further analyses demonstrate the importance of overcoming catastrophic forgetting for improving the model performance.
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Dec 26, 2023
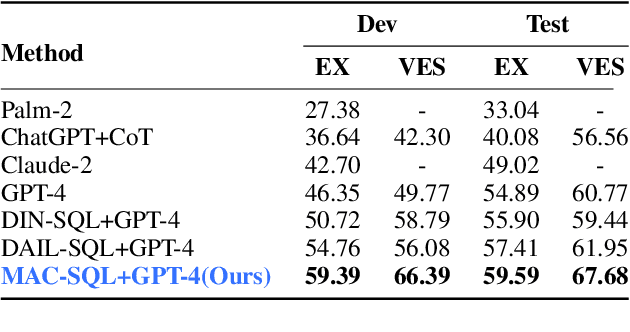
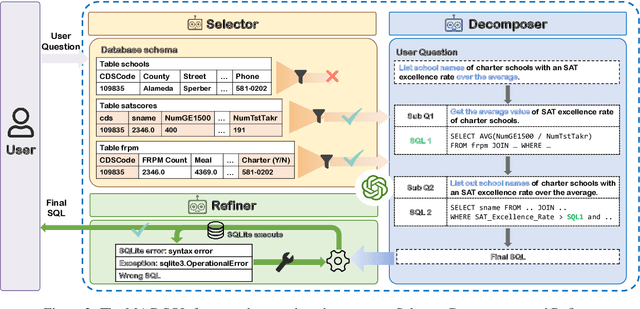

Recent advancements in Text-to-SQL methods employing Large Language Models (LLMs) have demonstrated remarkable performance. Nonetheless, these approaches continue to encounter difficulties when handling extensive databases, intricate user queries, and erroneous SQL results. To tackle these challenges, we present \textsc{MAC-SQL}, a novel LLM-based multi-agent collaborative framework designed for the Text-to-SQL task. Our framework comprises three agents: the \textit{Selector}, accountable for condensing voluminous databases and preserving relevant table schemas for user questions; the \textit{Decomposer}, which disassembles complex user questions into more straightforward sub-problems and resolves them progressively; and the \textit{Refiner}, tasked with validating and refining defective SQL queries. We perform comprehensive experiments on two Text-to-SQL datasets, BIRD and Spider, achieving a state-of-the-art execution accuracy of 59.59\% on the BIRD test set. Moreover, we have open-sourced an instruction fine-tuning model, SQL-Llama, based on Code Llama 7B, in addition to an agent instruction dataset derived from training data based on BIRD and Spider. The SQL-Llama model has demonstrated encouraging results on the development sets of both BIRD and Spider. However, when compared to GPT-4, there remains a notable potential for enhancement. Our code and data are publicly available at https://github.com/wbbeyourself/MAC-SQL.
Multi-Stage Pre-training Enhanced by ChatGPT for Multi-Scenario Multi-Domain Dialogue Summarization
Oct 16, 2023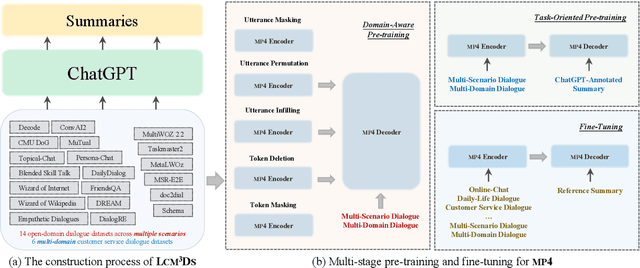

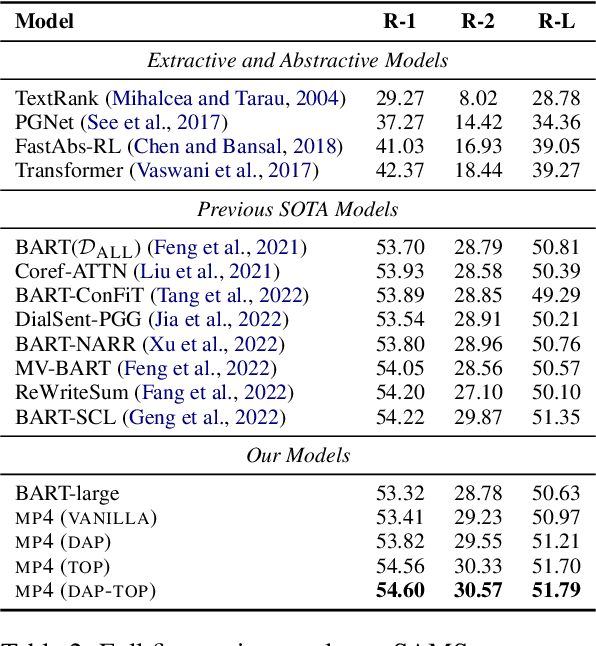
Dialogue summarization involves a wide range of scenarios and domains. However, existing methods generally only apply to specific scenarios or domains. In this study, we propose a new pre-trained model specifically designed for multi-scenario multi-domain dialogue summarization. It adopts a multi-stage pre-training strategy to reduce the gap between the pre-training objective and fine-tuning objective. Specifically, we first conduct domain-aware pre-training using large-scale multi-scenario multi-domain dialogue data to enhance the adaptability of our pre-trained model. Then, we conduct task-oriented pre-training using large-scale multi-scenario multi-domain "dialogue-summary" parallel data annotated by ChatGPT to enhance the dialogue summarization ability of our pre-trained model. Experimental results on three dialogue summarization datasets from different scenarios and domains indicate that our pre-trained model significantly outperforms previous state-of-the-art models in full fine-tuning, zero-shot, and few-shot settings.
KnowPrefix-Tuning: A Two-Stage Prefix-Tuning Framework for Knowledge-Grounded Dialogue Generation
Jun 27, 2023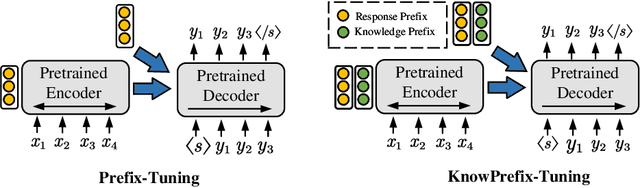
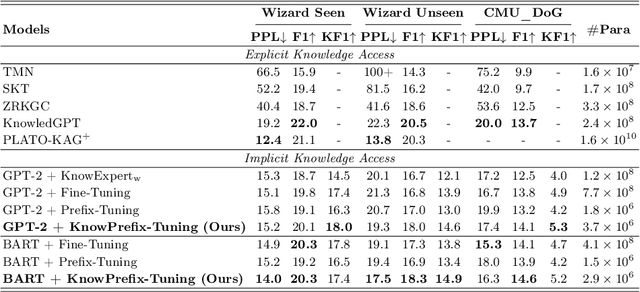
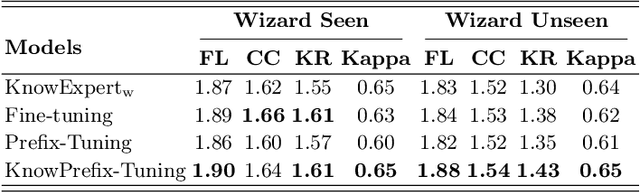
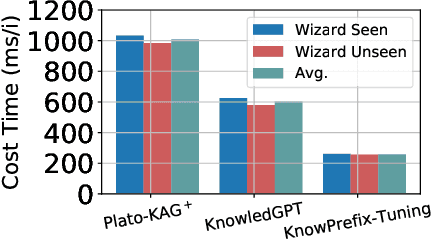
Existing knowledge-grounded conversation systems generate responses typically in a retrieve-then-generate manner. They require a large knowledge base and a strong knowledge retrieval component, which is time- and resource-consuming. In this paper, we address the challenge by leveraging the inherent knowledge encoded in the pre-trained language models (PLMs). We propose Knowledgeable Prefix Tuning (KnowPrefix-Tuning), a two-stage tuning framework, bypassing the retrieval process in a knowledge-grounded conversation system by injecting prior knowledge into the lightweight knowledge prefix. The knowledge prefix is a sequence of continuous knowledge-specific vectors that can be learned during training. In addition, we propose a novel interactive re-parameterization mechanism that allows the prefix to interact fully with the PLM during the optimization of response generation. Experimental results demonstrate that KnowPrefix-Tuning outperforms fine-tuning and other lightweight tuning approaches, and performs comparably with strong retrieval-based baselines while being $3\times$ faster during inference.
GripRank: Bridging the Gap between Retrieval and Generation via the Generative Knowledge Improved Passage Ranking
May 29, 2023
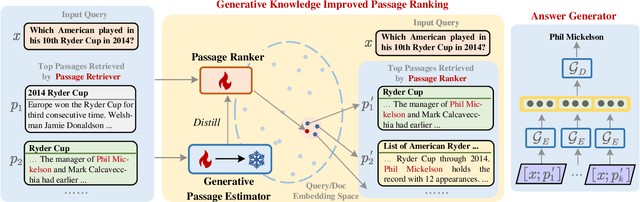
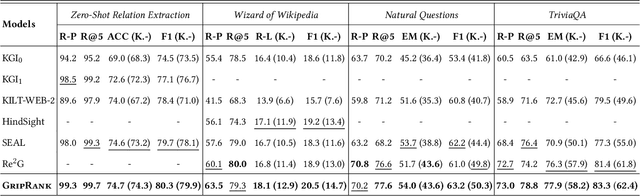
Retrieval-enhanced text generation, which aims to leverage passages retrieved from a large passage corpus for delivering a proper answer given the input query, has shown remarkable progress on knowledge-intensive language tasks such as open-domain question answering and knowledge-enhanced dialogue generation. However, the retrieved passages are not ideal for guiding answer generation because of the discrepancy between retrieval and generation, i.e., the candidate passages are all treated equally during the retrieval procedure without considering their potential to generate the proper answers. This discrepancy makes a passage retriever deliver a sub-optimal collection of candidate passages to generate answers. In this paper, we propose the GeneRative Knowledge Improved Passage Ranking (GripRank) approach, addressing the above challenge by distilling knowledge from a generative passage estimator (GPE) to a passage ranker, where the GPE is a generative language model used to measure how likely the candidate passages can generate the proper answer. We realize the distillation procedure by teaching the passage ranker learning to rank the passages ordered by the GPE. Furthermore, we improve the distillation quality by devising a curriculum knowledge distillation mechanism, which allows the knowledge provided by the GPE can be progressively distilled to the ranker through an easy-to-hard curriculum, enabling the passage ranker to correctly recognize the provenance of the answer from many plausible candidates. We conduct extensive experiments on four datasets across three knowledge-intensive language tasks. Experimental results show advantages over the state-of-the-art methods for both passage ranking and answer generation on the KILT benchmark.
Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System
Apr 26, 2023
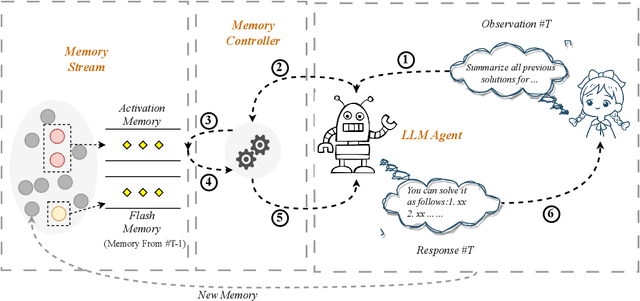

Large-scale Language Models (LLMs) are constrained by their inability to process lengthy inputs. To address this limitation, we propose the Self-Controlled Memory (SCM) system to unleash infinite-length input capacity for large-scale language models. Our SCM system is composed of three key modules: the language model agent, the memory stream, and the memory controller. The language model agent iteratively processes ultra-long inputs and stores all historical information in the memory stream. The memory controller provides the agent with both long-term memory (archived memory) and short-term memory (flash memory) to generate precise and coherent responses. The controller determines which memories from archived memory should be activated and how to incorporate them into the model input. Our SCM system can be integrated with any LLMs to enable them to process ultra-long texts without any modification or fine-tuning. Experimental results show that our SCM system enables LLMs, which are not optimized for multi-turn dialogue, to achieve multi-turn dialogue capabilities that are comparable to ChatGPT, and to outperform ChatGPT in scenarios involving ultra-long document summarization or long-term conversations. Additionally, we will supply a test set, which covers common long-text input scenarios, for evaluating the abilities of LLMs in processing long documents.~\footnote{Working in progress.}\footnote{\url{https://github.com/wbbeyourself/SCM4LLMs}}