 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Jun 18, 2025Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought (Long CoT) reasoning have demonstrated remarkable cross-domain generalization capabilities. However, the underlying mechanisms supporting such transfer remain poorly understood. We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes -- fundamental reasoning patterns that capture the essence of problems across domains. These prototypes minimize the nuances of the representation, revealing that seemingly diverse tasks are grounded in shared reasoning structures.Based on this hypothesis, we propose ProtoReasoning, a framework that enhances the reasoning ability of LLMs by leveraging scalable and verifiable prototypical representations (Prolog for logical reasoning, PDDL for planning).ProtoReasoning features: (1) an automated prototype construction pipeline that transforms problems into corresponding prototype representations; (2) a comprehensive verification system providing reliable feedback through Prolog/PDDL interpreters; (3) the scalability to synthesize problems arbitrarily within prototype space while ensuring correctness. Extensive experiments show that ProtoReasoning achieves 4.7% improvement over baseline models on logical reasoning (Enigmata-Eval), 6.3% improvement on planning tasks, 4.0% improvement on general reasoning (MMLU) and 1.0% on mathematics (AIME24). Significantly, our ablation studies confirm that learning in prototype space also demonstrates enhanced generalization to structurally similar problems compared to training solely on natural language representations, validating our hypothesis that reasoning prototypes serve as the foundation for generalizable reasoning in large language models.
Inference-time Alignment in Continuous Space
May 26, 2025Aligning large language models with human feedback at inference time has received increasing attention due to its flexibility. Existing methods rely on generating multiple responses from the base policy for search using a reward model, which can be considered as searching in a discrete response space. However, these methods struggle to explore informative candidates when the base policy is weak or the candidate set is small, resulting in limited effectiveness. In this paper, to address this problem, we propose Simple Energy Adaptation ($\textbf{SEA}$), a simple yet effective algorithm for inference-time alignment. In contrast to expensive search over the discrete space, SEA directly adapts original responses from the base policy toward the optimal one via gradient-based sampling in continuous latent space. Specifically, SEA formulates inference as an iterative optimization procedure on an energy function over actions in the continuous space defined by the optimal policy, enabling simple and effective alignment. For instance, despite its simplicity, SEA outperforms the second-best baseline with a relative improvement of up to $ \textbf{77.51%}$ on AdvBench and $\textbf{16.36%}$ on MATH. Our code is publicly available at https://github.com/yuanyige/SEA
A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges
Jul 26, 2020
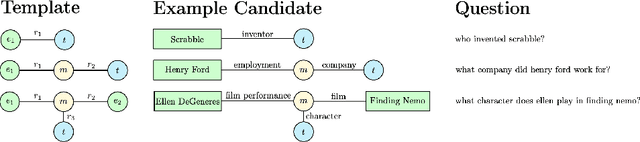

Question Answering (QA) over Knowledge Base (KB) aims to automatically answer natural language questions via well-structured relation information between entities stored in knowledge bases. In order to make KBQA more applicable in actual scenarios, researchers have shifted their attention from simple questions to complex questions, which require more KB triples and constraint inference. In this paper, we introduce the recent advances in complex QA. Besides traditional methods relying on templates and rules, the research is categorized into a taxonomy that contains two main branches, namely Information Retrieval-based and Neural Semantic Parsing-based. After describing the methods of these branches, we analyze directions for future research and introduce the models proposed by the Alime team.
Graph Wavelet Neural Network
Apr 12, 2019
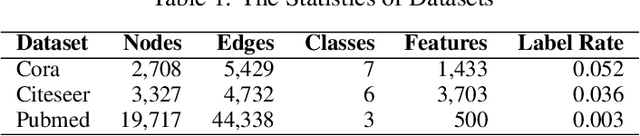

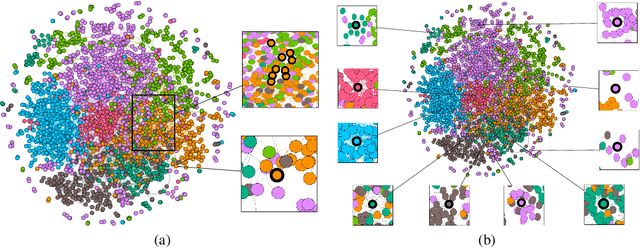
We present graph wavelet neural network (GWNN), a novel graph convolutional neural network (CNN), leveraging graph wavelet transform to address the shortcomings of previous spectral graph CNN methods that depend on graph Fourier transform. Different from graph Fourier transform, graph wavelet transform can be obtained via a fast algorithm without requiring matrix eigendecomposition with high computational cost. Moreover, graph wavelets are sparse and localized in vertex domain, offering high efficiency and good interpretability for graph convolution. The proposed GWNN significantly outperforms previous spectral graph CNNs in the task of graph-based semi-supervised classification on three benchmark datasets: Cora, Citeseer and Pubmed.