 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Language Models Using Follow-up Likelihood as Reward Signal
Sep 20, 2024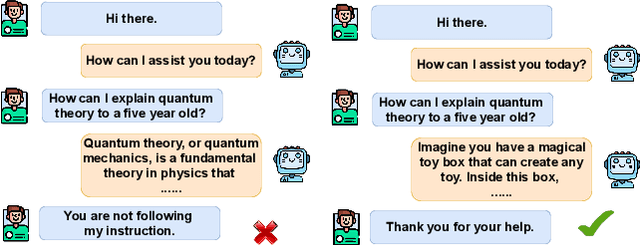

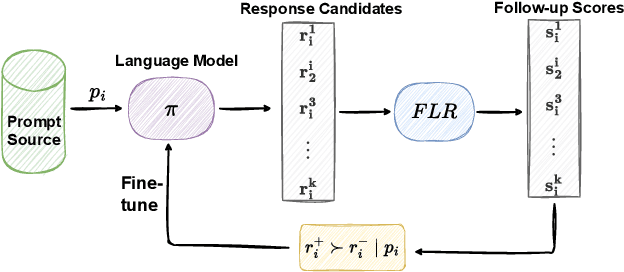

In natural human-to-human conversations, participants often receive feedback signals from one another based on their follow-up reactions. These reactions can include verbal responses, facial expressions, changes in emotional state, and other non-verbal cues. Similarly, in human-machine interactions, the machine can leverage the user's follow-up utterances as feedback signals to assess whether it has appropriately addressed the user's request. Therefore, we propose using the likelihood of follow-up utterances as rewards to differentiate preferred responses from less favored ones, without relying on human or commercial LLM-based preference annotations. Our proposed reward mechanism, ``Follow-up Likelihood as Reward" (FLR), matches the performance of strong reward models trained on large-scale human or GPT-4 annotated data on 8 pairwise-preference and 4 rating-based benchmarks. Building upon the FLR mechanism, we propose to automatically mine preference data from the online generations of a base policy model. The preference data are subsequently used to boost the helpfulness of the base model through direct alignment from preference (DAP) methods, such as direct preference optimization (DPO). Lastly, we demonstrate that fine-tuning the language model that provides follow-up likelihood with natural language feedback significantly enhances FLR's performance on reward modeling benchmarks and effectiveness in aligning the base policy model's helpfulness.
TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
May 30, 2024



Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the "TS-Align" framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023



Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.
Overview of Robust and Multilingual Automatic Evaluation Metrics for Open-Domain Dialogue Systems at DSTC 11 Track 4
Jun 22, 2023



The advent and fast development of neural networks have revolutionized the research on dialogue systems and subsequently have triggered various challenges regarding their automatic evaluation. Automatic evaluation of open-domain dialogue systems as an open challenge has been the center of the attention of many researchers. Despite the consistent efforts to improve automatic metrics' correlations with human evaluation, there have been very few attempts to assess their robustness over multiple domains and dimensions. Also, their focus is mainly on the English language. All of these challenges prompt the development of automatic evaluation metrics that are reliable in various domains, dimensions, and languages. This track in the 11th Dialogue System Technology Challenge (DSTC11) is part of the ongoing effort to promote robust and multilingual automatic evaluation metrics. This article describes the datasets and baselines provided to participants and discusses the submission and result details of the two proposed subtasks.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022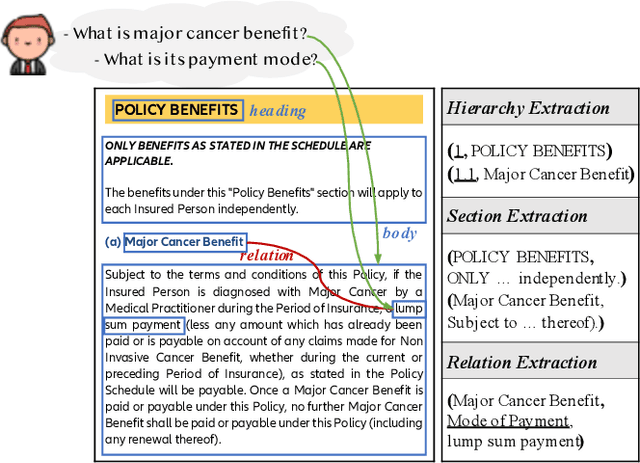
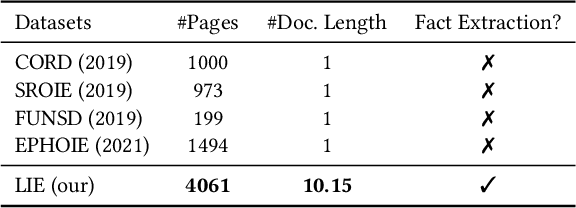

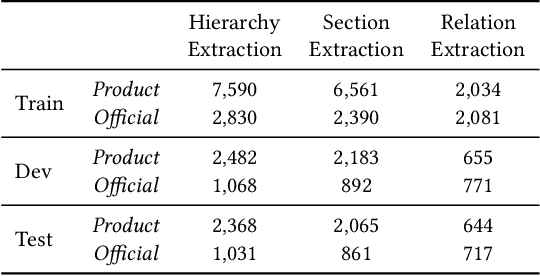
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding
Dec 02, 2021
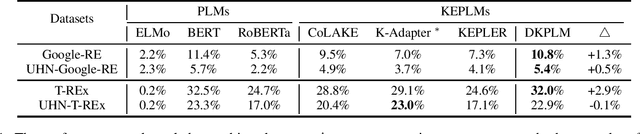
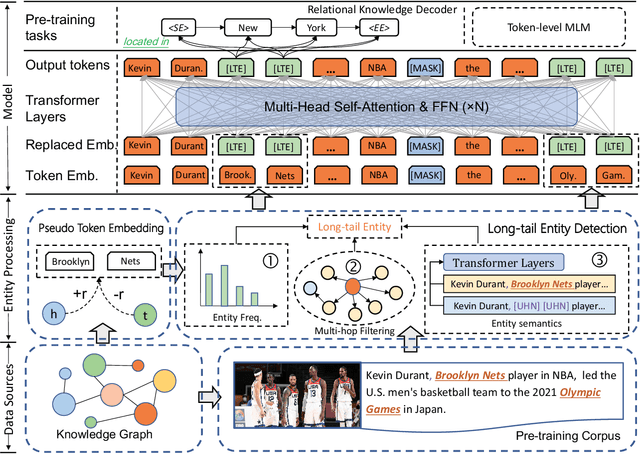
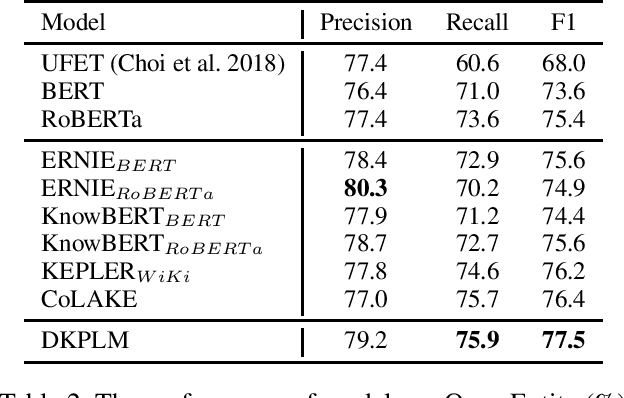
Knowledge-Enhanced Pre-trained Language Models (KEPLMs) are pre-trained models with relation triples injecting from knowledge graphs to improve language understanding abilities. To guarantee effective knowledge injection, previous studies integrate models with knowledge encoders for representing knowledge retrieved from knowledge graphs. The operations for knowledge retrieval and encoding bring significant computational burdens, restricting the usage of such models in real-world applications that require high inference speed. In this paper, we propose a novel KEPLM named DKPLM that Decomposes Knowledge injection process of the Pre-trained Language Models in pre-training, fine-tuning and inference stages, which facilitates the applications of KEPLMs in real-world scenarios. Specifically, we first detect knowledge-aware long-tail entities as the target for knowledge injection, enhancing the KEPLMs' semantic understanding abilities and avoiding injecting redundant information. The embeddings of long-tail entities are replaced by "pseudo token representations" formed by relevant knowledge triples. We further design the relational knowledge decoding task for pre-training to force the models to truly understand the injected knowledge by relation triple reconstruction. Experiments show that our model outperforms other KEPLMs significantly over zero-shot knowledge probing tasks and multiple knowledge-aware language understanding tasks. We further show that DKPLM has a higher inference speed than other competing models due to the decomposing mechanism.
Path-Enhanced Multi-Relational Question Answering with Knowledge Graph Embeddings
Oct 29, 2021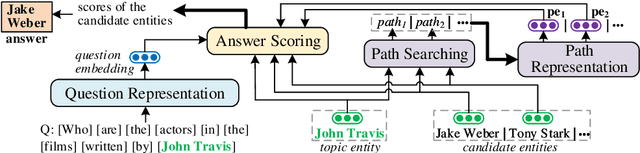
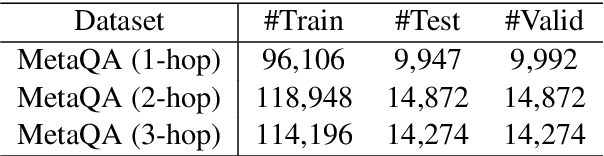

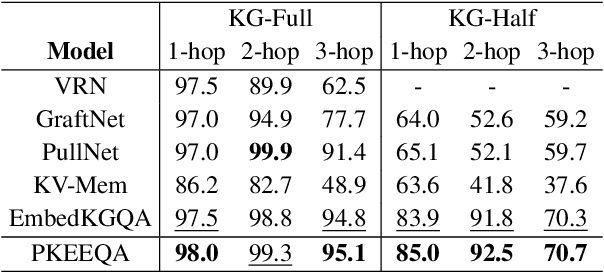
The multi-relational Knowledge Base Question Answering (KBQA) system performs multi-hop reasoning over the knowledge graph (KG) to achieve the answer. Recent approaches attempt to introduce the knowledge graph embedding (KGE) technique to handle the KG incompleteness but only consider the triple facts and neglect the significant semantic correlation between paths and multi-relational questions. In this paper, we propose a Path and Knowledge Embedding-Enhanced multi-relational Question Answering model (PKEEQA), which leverages multi-hop paths between entities in the KG to evaluate the ambipolar correlation between a path embedding and a multi-relational question embedding via a customizable path representation mechanism, benefiting for achieving more accurate answers from the perspective of both the triple facts and the extra paths. Experimental results illustrate that PKEEQA improves KBQA models' performance for multi-relational question answering with explainability to some extent derived from paths.
Relational Learning with Gated and Attentive Neighbor Aggregator for Few-Shot Knowledge Graph Completion
Apr 27, 2021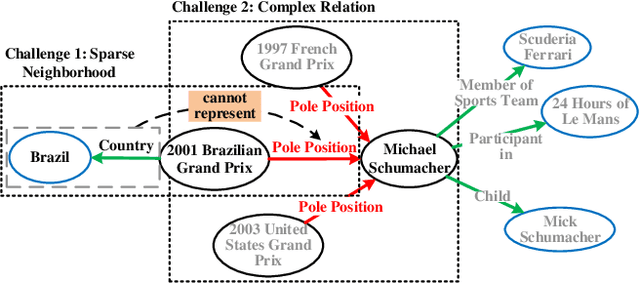

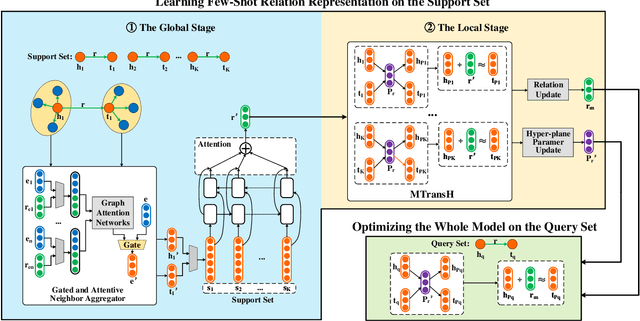
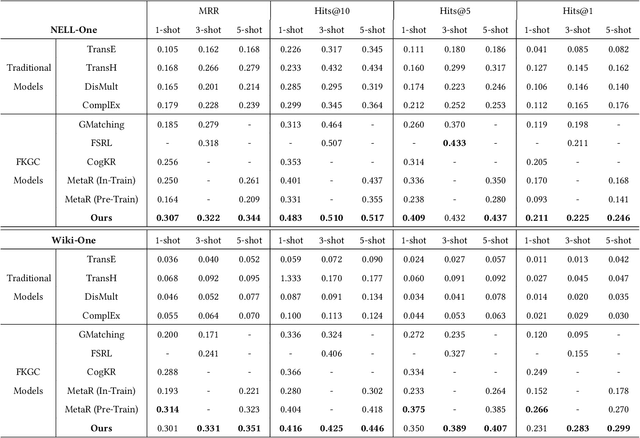
Aiming at expanding few-shot relations' coverage in knowledge graphs (KGs), few-shot knowledge graph completion (FKGC) has recently gained more research interests. Some existing models employ a few-shot relation's multi-hop neighbor information to enhance its semantic representation. However, noise neighbor information might be amplified when the neighborhood is excessively sparse and no neighbor is available to represent the few-shot relation. Moreover, modeling and inferring complex relations of one-to-many (1-N), many-to-one (N-1), and many-to-many (N-N) by previous knowledge graph completion approaches requires high model complexity and a large amount of training instances. Thus, inferring complex relations in the few-shot scenario is difficult for FKGC models due to limited training instances. In this paper, we propose a few-shot relational learning with global-local framework to address the above issues. At the global stage, a novel gated and attentive neighbor aggregator is built for accurately integrating the semantics of a few-shot relation's neighborhood, which helps filtering the noise neighbors even if a KG contains extremely sparse neighborhoods. For the local stage, a meta-learning based TransH (MTransH) method is designed to model complex relations and train our model in a few-shot learning fashion. Extensive experiments show that our model outperforms the state-of-the-art FKGC approaches on the frequently-used benchmark datasets NELL-One and Wiki-One. Compared with the strong baseline model MetaR, our model achieves 5-shot FKGC performance improvements of 8.0% on NELL-One and 2.8% on Wiki-One by the metric Hits@10.
A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges
Jul 26, 2020
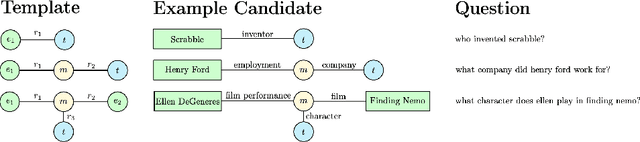

Question Answering (QA) over Knowledge Base (KB) aims to automatically answer natural language questions via well-structured relation information between entities stored in knowledge bases. In order to make KBQA more applicable in actual scenarios, researchers have shifted their attention from simple questions to complex questions, which require more KB triples and constraint inference. In this paper, we introduce the recent advances in complex QA. Besides traditional methods relying on templates and rules, the research is categorized into a taxonomy that contains two main branches, namely Information Retrieval-based and Neural Semantic Parsing-based. After describing the methods of these branches, we analyze directions for future research and introduce the models proposed by the Alime team.
A Survey on Dialog Management: Recent Advances and Challenges
May 05, 2020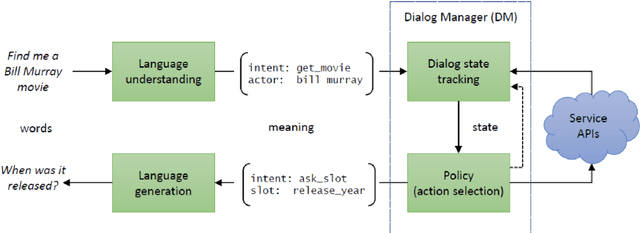
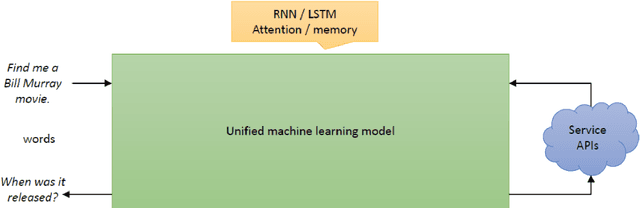

Dialog management (DM) is a crucial component in a task-oriented dialog system. Given the dialog history, DM predicts the dialog state and decides the next action that the dialog agent should take. Recently, dialog policy learning has been widely formulated as a Reinforcement Learning (RL) problem, and more works focus on the applicability of DM. In this paper, we survey recent advances and challenges within three critical topics for DM: (1) improving model scalability to facilitate dialog system modeling in new scenarios, (2) dealing with the data scarcity problem for dialog policy learning, and (3) enhancing the training efficiency to achieve better task-completion performance . We believe that this survey can shed a light on future research in dialog management.