 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat-If Analysis of Large Language Models: Explore the Game World Using Proactive Thinking
Sep 05, 2025Large language models (LLMs) excel at processing information reactively but lack the ability to systemically explore hypothetical futures. They cannot ask, "what if we take this action? how will it affect the final outcome" and forecast its potential consequences before acting. This critical gap limits their utility in dynamic, high-stakes scenarios like strategic planning, risk assessment, and real-time decision making. To bridge this gap, we propose WiA-LLM, a new paradigm that equips LLMs with proactive thinking capabilities. Our approach integrates What-If Analysis (WIA), a systematic approach for evaluating hypothetical scenarios by changing input variables. By leveraging environmental feedback via reinforcement learning, WiA-LLM moves beyond reactive thinking. It dynamically simulates the outcomes of each potential action, enabling the model to anticipate future states rather than merely react to the present conditions. We validate WiA-LLM in Honor of Kings (HoK), a complex multiplayer game environment characterized by rapid state changes and intricate interactions. The game's real-time state changes require precise multi-step consequence prediction, making it an ideal testbed for our approach. Experimental results demonstrate WiA-LLM achieves a remarkable 74.2% accuracy in forecasting game-state changes (up to two times gain over baselines). The model shows particularly significant gains in high-difficulty scenarios where accurate foresight is critical. To our knowledge, this is the first work to formally explore and integrate what-if analysis capabilities within LLMs. WiA-LLM represents a fundamental advance toward proactive reasoning in LLMs, providing a scalable framework for robust decision-making in dynamic environments with broad implications for strategic applications.
Aligning Language Models Using Follow-up Likelihood as Reward Signal
Sep 20, 2024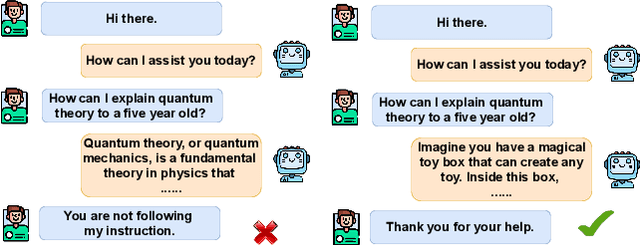

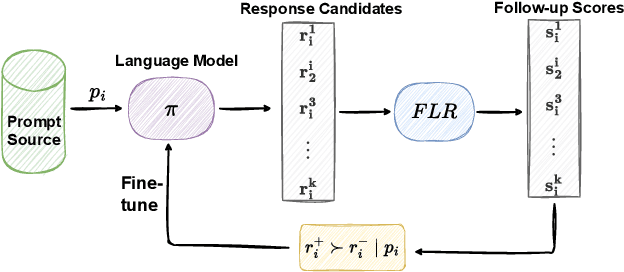

In natural human-to-human conversations, participants often receive feedback signals from one another based on their follow-up reactions. These reactions can include verbal responses, facial expressions, changes in emotional state, and other non-verbal cues. Similarly, in human-machine interactions, the machine can leverage the user's follow-up utterances as feedback signals to assess whether it has appropriately addressed the user's request. Therefore, we propose using the likelihood of follow-up utterances as rewards to differentiate preferred responses from less favored ones, without relying on human or commercial LLM-based preference annotations. Our proposed reward mechanism, ``Follow-up Likelihood as Reward" (FLR), matches the performance of strong reward models trained on large-scale human or GPT-4 annotated data on 8 pairwise-preference and 4 rating-based benchmarks. Building upon the FLR mechanism, we propose to automatically mine preference data from the online generations of a base policy model. The preference data are subsequently used to boost the helpfulness of the base model through direct alignment from preference (DAP) methods, such as direct preference optimization (DPO). Lastly, we demonstrate that fine-tuning the language model that provides follow-up likelihood with natural language feedback significantly enhances FLR's performance on reward modeling benchmarks and effectiveness in aligning the base policy model's helpfulness.
SoftDedup: an Efficient Data Reweighting Method for Speeding Up Language Model Pre-training
Jul 09, 2024
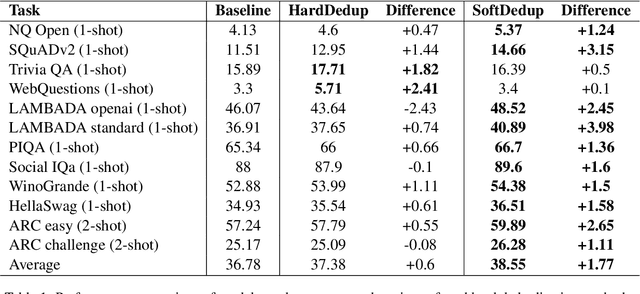
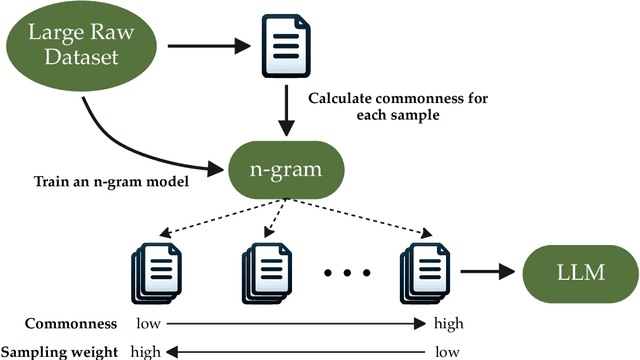
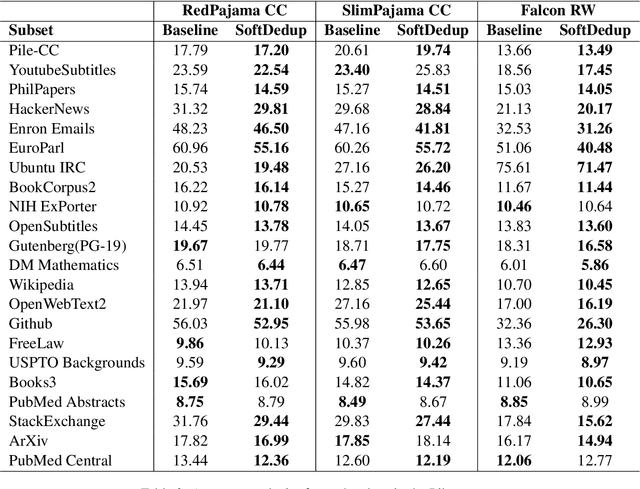
The effectiveness of large language models (LLMs) is often hindered by duplicated data in their extensive pre-training datasets. Current approaches primarily focus on detecting and removing duplicates, which risks the loss of valuable information and neglects the varying degrees of duplication. To address this, we propose a soft deduplication method that maintains dataset integrity while selectively reducing the sampling weight of data with high commonness. Central to our approach is the concept of "data commonness", a metric we introduce to quantify the degree of duplication by measuring the occurrence probabilities of samples using an n-gram model. Empirical analysis shows that this method significantly improves training efficiency, achieving comparable perplexity scores with at least a 26% reduction in required training steps. Additionally, it enhances average few-shot downstream accuracy by 1.77% when trained for an equivalent duration. Importantly, this approach consistently improves performance, even on rigorously deduplicated datasets, indicating its potential to complement existing methods and become a standard pre-training process for LLMs.
TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
May 30, 2024



Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the "TS-Align" framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023



Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.