 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA physics-informed foundation model for quantitative diffusion MRI
May 29, 2026Understanding the human brain requires access to its microscopic tissue architecture. Diffusion magnetic resonance imaging (MRI) provides the only noninvasive window into whole-brain microstructure in vivo, yet reliable quantitative mapping remains confined to specialized research settings requiring dense sampling and optimized acquisition protocols. To address this gap, we present a physics-informed generative microstructure network (PIGMENT) that learns a universal generative prior of human brain microstructure and adapts it zero-shot to each participant's measured data to recover subject-specific maps. Trained on 11375 scans spanning multiple sites, vendors, and field strengths, PIGMENT enabled reliable quantitative mapping for tensor, kurtosis, and NODDI models across external datasets from five independent centers. It remains effective where conventional fitting becomes unreliable, recovering meaningful maps from extremely sparse acquisitions while supporting downstream tractography and structural connectivity mapping. PIGMENT estimates demonstrated strong biological validity, preserving submillimeter cortical microarchitectural patterns and early-childhood white matter developmental trajectories from 10-fold accelerated scans. Furthermore, PIGMENT enables reliable quantitative tensor mapping on cost-efficient low-field systems and the extraction of tumor-related biomarkers using ultra-fast clinical protocols. Together, these results establish PIGMENT as a physics-informed foundation model that extends quantitative diffusion MRI into regimes traditionally too sparse, heterogeneous, or clinically constrained for reliable analysis.
Towards Reliable Fetal Ultrasound Interpretation with Multi-Agent Collaboration
May 25, 2026Automated fetal ultrasound interpretation requires a workflow from visual perception, including plane recognition and anatomical segmentation, to clinical understanding, including biometric measurement and diagnostic reporting. However, the prevailing "one-task, one-model" paradigm limits systematic integration of evidence across this multi-step process. Although multimodal large language models (MLLMs) show promising visual understanding, their limited domain-specific grounding and hallucination risks restrict reliability in fetal ultrasound analysis. To address these limitations, we propose FetUSAgents, a tool-augmented multi-agent system for comprehensive fetal ultrasound interpretation, supporting visual question answering (VQA), report generation, image captioning, and video summarization. FetUSAgents coordinates task-specific visual tools through collaborative LLM agents and decomposes clinical queries into subtasks that progress from anatomical recognition to quantitative measurement. We further introduce Dual-Path Evidence Arbitration (DPEA), which integrates LLM-based deliberative reasoning with structured computational evidence from specialized visual tools. A retrieval-enhanced evidence bank consolidates intermediate findings to support traceable and clinically grounded conclusions. In addition, we construct FetUS-VQA, a dedicated VQA benchmark for fetal ultrasound, comprising 1,892 images and 3,205 question-answer pairs across 10 clinical tasks. Extensive out-of-distribution experiments show that FetUSAgents outperforms general and medical MLLMs, exceeding the strongest baseline by more than 25 percent in VQA accuracy. These results suggest a scalable route toward evidence-driven clinical assistants for prenatal imaging. Code is available.
INFANiTE: Implicit Neural representation for high-resolution Fetal brain spatio-temporal Atlas learNing from clinical Thick-slicE MRI
May 11, 2026Spatio-temporal fetal brain atlases are important for characterizing normative neurodevelopment and identifying congenital anomalies. However, existing atlas construction pipelines necessitate days for slice-to-volume reconstruction (SVR) to generate high-resolution 3D brain volumes and several additional days for iterative volume registration, thereby rendering atlas construction from large-scale cohorts prohibitively impractical. We address these limitations with INFANiTE, an Implicit Neural Representation (INR) framework for high-resolution Fetal brain spatio-temporal Atlas learNing from clinical Thick-slicE MRI scans, bypassing both the costly SVR and the iterative non-rigid registration steps entirely, thereby substantially accelerating atlas construction. Extensive experiments demonstrate that INFANiTE outperforms existing baselines in subject consistency, reference fidelity, intrinsic quality and biological plausibility, even under challenging sparse-data settings. Additionally, INFANiTE reduces the end-to-end processing time (i.e., from raw scans to the final atlas) from days to hours compared to the traditional 3D volume-based pipeline (e.g., SyGN), facilitating large-scale population-level fetal brain analysis. Our code is publicly available at: https://anonymous.4open.science/r/INFANiTE-5D74
Annotation-free deep learning for detection and segmentation of fetal germinal matrix-intraventricular hemorrhage in brain MRI
May 10, 2026Background: Prenatal germinal matrix-intraventricular hemorrhage (GMH-IVH) is a leading cause of infant mortality and neurodevelopmental impairment. Manual diagnosis and lesion segmentation are labor-intensive and error-prone. Deep learning models offer potential for automation but typically require large annotated datasets, which are challenging to obtain. Purpose: To develop and validate an annotation-free deep learning framework for automated detection and segmentation of GMH-IVH on brain MRI. Materials and Methods: This retrospective study analyzed 2D T2-weighted MRI data from pregnant women collected from October 2015 to October 2023 at one hospital (internal validation) and two hospitals (external validation). Eligible participants included healthy fetuses and those with GMH-IVH. FreeHemoSeg was developed and trained using pseudo GMH-IVH images synthesized from normal fetal data guided by medical priors. Primary outcomes included diagnostic accuracy (area under the ROC curve [AUROC], sensitivity, specificity) and segmentation accuracy (Dice similarity coefficient [DSC]). A reader study evaluated clinical utility. Results: A total of 1674 stacks from 558 pregnant women were analyzed. FreeHemoSeg achieved the highest performance in both internal (sensitivity: 0.914, 95% CI 0.869-0.945; specificity: 0.966, 95% CI 0.946-0.978; DSC: 0.559, 95% CI 0.546-0.571) and external validation (sensitivity: 0.824, 95% CI 0.739-0.885; specificity: 0.943, 95% CI 0.913-0.964; DSC: 0.512, 95% CI 0.497-0.526), outperforming supervised and unsupervised methods. FreeHemoSeg assistance improved radiologists' sensitivity (from 0.882 to 0.941-1.000) and diagnostic confidence while reducing interpretation time by 16.0-52.7%. Conclusion: FreeHemoSeg accurately detects and localizes fetal brain hemorrhages without annotated training data, enabling earlier diagnosis and supporting timely clinical management.
FetalAgents: A Multi-Agent System for Fetal Ultrasound Image and Video Analysis
Mar 10, 2026Fetal ultrasound (US) is the primary imaging modality for prenatal screening, yet its interpretation relies heavily on the expertise of the clinician. Despite advances in deep learning and foundation models, existing automated tools for fetal US analysis struggle to balance task-specific accuracy with the whole-process versatility required to support end-to-end clinical workflows. To address these limitations, we propose FetalAgents, the first multi-agent system for comprehensive fetal US analysis. Through a lightweight, agentic coordination framework, FetalAgents dynamically orchestrates specialized vision experts to maximize performance across diagnosis, measurement, and segmentation. Furthermore, FetalAgents advances beyond static image analysis by supporting end-to-end video stream summarization, where keyframes are automatically identified across multiple anatomical planes, analyzed by coordinated experts, and synthesized with patient metadata into a structured clinical report. Extensive multi-center external evaluations across eight clinical tasks demonstrate that FetalAgents consistently delivers the most robust and accurate performance when compared against specialized models and multimodal large language models (MLLMs), ultimately providing an auditable, workflow-aligned solution for fetal ultrasound analysis and reporting.
Deep learning-based neurodevelopmental assessment in preterm infants
Jan 17, 2026Preterm infants (born between 28 and 37 weeks of gestation) face elevated risks of neurodevelopmental delays, making early identification crucial for timely intervention. While deep learning-based volumetric segmentation of brain MRI scans offers a promising avenue for assessing neonatal neurodevelopment, achieving accurate segmentation of white matter (WM) and gray matter (GM) in preterm infants remains challenging due to their comparable signal intensities (isointense appearance) on MRI during early brain development. To address this, we propose a novel segmentation neural network, named Hierarchical Dense Attention Network. Our architecture incorporates a 3D spatial-channel attention mechanism combined with an attention-guided dense upsampling strategy to enhance feature discrimination in low-contrast volumetric data. Quantitative experiments demonstrate that our method achieves superior segmentation performance compared to state-of-the-art baselines, effectively tackling the challenge of isointense tissue differentiation. Furthermore, application of our algorithm confirms that WM and GM volumes in preterm infants are significantly lower than those in term infants, providing additional imaging evidence of the neurodevelopmental delays associated with preterm birth. The code is available at: https://github.com/ICL-SUST/HDAN.
What-If Analysis of Large Language Models: Explore the Game World Using Proactive Thinking
Sep 05, 2025Large language models (LLMs) excel at processing information reactively but lack the ability to systemically explore hypothetical futures. They cannot ask, "what if we take this action? how will it affect the final outcome" and forecast its potential consequences before acting. This critical gap limits their utility in dynamic, high-stakes scenarios like strategic planning, risk assessment, and real-time decision making. To bridge this gap, we propose WiA-LLM, a new paradigm that equips LLMs with proactive thinking capabilities. Our approach integrates What-If Analysis (WIA), a systematic approach for evaluating hypothetical scenarios by changing input variables. By leveraging environmental feedback via reinforcement learning, WiA-LLM moves beyond reactive thinking. It dynamically simulates the outcomes of each potential action, enabling the model to anticipate future states rather than merely react to the present conditions. We validate WiA-LLM in Honor of Kings (HoK), a complex multiplayer game environment characterized by rapid state changes and intricate interactions. The game's real-time state changes require precise multi-step consequence prediction, making it an ideal testbed for our approach. Experimental results demonstrate WiA-LLM achieves a remarkable 74.2% accuracy in forecasting game-state changes (up to two times gain over baselines). The model shows particularly significant gains in high-difficulty scenarios where accurate foresight is critical. To our knowledge, this is the first work to formally explore and integrate what-if analysis capabilities within LLMs. WiA-LLM represents a fundamental advance toward proactive reasoning in LLMs, providing a scalable framework for robust decision-making in dynamic environments with broad implications for strategic applications.
Dynamic Accumulated Attention Map for Interpreting Evolution of Decision-Making in Vision Transformer
Mar 18, 2025Various Vision Transformer (ViT) models have been widely used for image recognition tasks. However, existing visual explanation methods can not display the attention flow hidden inside the inner structure of ViT models, which explains how the final attention regions are formed inside a ViT for its decision-making. In this paper, a novel visual explanation approach, Dynamic Accumulated Attention Map (DAAM), is proposed to provide a tool that can visualize, for the first time, the attention flow from the top to the bottom through ViT networks. To this end, a novel decomposition module is proposed to construct and store the spatial feature information by unlocking the [class] token generated by the self-attention module of each ViT block. The module can also obtain the channel importance coefficients by decomposing the classification score for supervised ViT models. Because of the lack of classification score in self-supervised ViT models, we propose dimension-wise importance weights to compute the channel importance coefficients. Such spatial features are linearly combined with the corresponding channel importance coefficients, forming the attention map for each block. The dynamic attention flow is revealed by block-wisely accumulating each attention map. The contribution of this work focuses on visualizing the evolution dynamic of the decision-making attention for any intermediate block inside a ViT model by proposing a novel decomposition module and dimension-wise importance weights. The quantitative and qualitative analysis consistently validate the effectiveness and superior capacity of the proposed DAAM for not only interpreting ViT models with the fully-connected layers as the classifier but also self-supervised ViT models. The code is available at https://github.com/ly9802/DynamicAccumulatedAttentionMap.
Tgea: An error-annotated dataset and benchmark tasks for text generation from pretrained language models
Mar 06, 2025In order to deeply understand the capability of pretrained language models in text generation and conduct a diagnostic evaluation, we propose TGEA, an error-annotated dataset with multiple benchmark tasks for text generation from pretrained language models (PLMs). We use carefully selected prompt words to guide GPT-2 to generate candidate sentences, from which we select 47K for error annotation. Crowdsourced workers manually check each of these sentences and detect 12k erroneous sentences. We create an error taxonomy to cover 24 types of errors occurring in these erroneous sentences according to the nature of errors with respect to linguistics and knowledge (eg, common sense). For each erroneous span in PLM-generated sentences, we also detect another span that is closely associated with it. Each error is hence manually labeled with comprehensive annotations, including the span of the error, the associated span, minimal correction to the error, the type of the error, and rationale behind the error. Apart from the fully annotated dataset, we also present a detailed description of the data collection procedure, statistics and analysis of the dataset. This is the first dataset with comprehensive annotations for PLM-generated texts, which facilitates the diagnostic evaluation of PLM-based text generation. Furthermore, we use TGEA as a benchmark dataset and propose a series of automatic diagnosis tasks, including error detection, error type classification, associated span detection, error rationale generation, to further promote future study on the automatic error detection and correction on texts generated by pretrained language models.
Neuron Abandoning Attention Flow: Visual Explanation of Dynamics inside CNN Models
Dec 02, 2024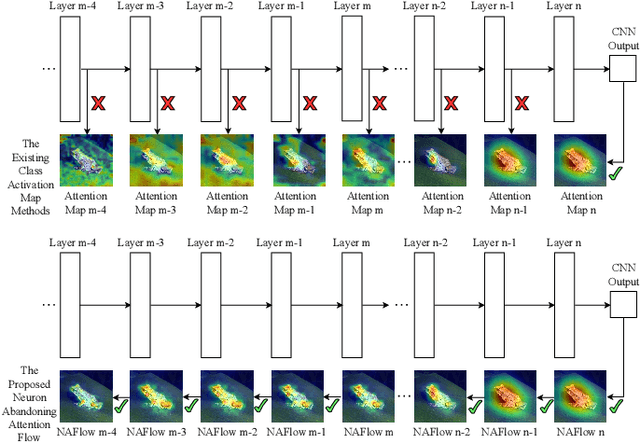
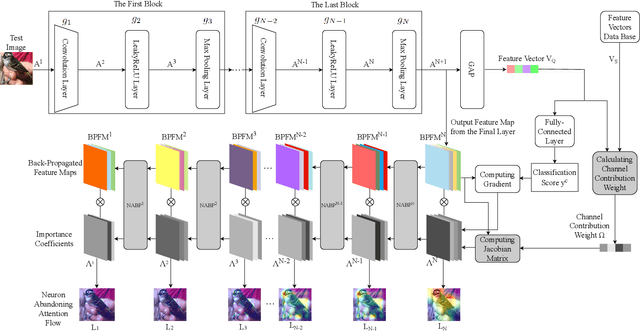
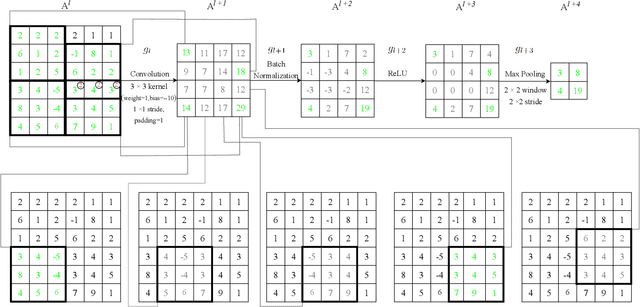
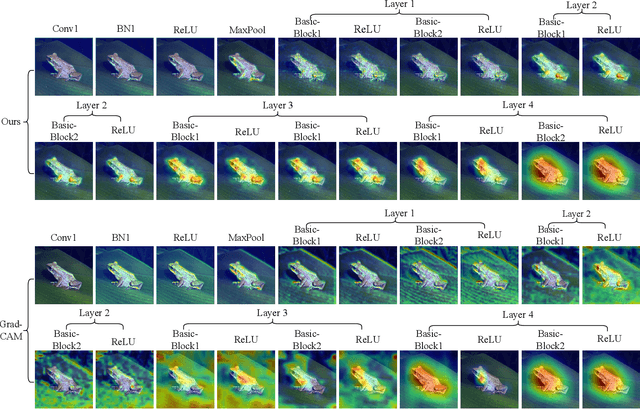
In this paper, we present a Neuron Abandoning Attention Flow (NAFlow) method to address the open problem of visually explaining the attention evolution dynamics inside CNNs when making their classification decisions. A novel cascading neuron abandoning back-propagation algorithm is designed to trace neurons in all layers of a CNN that involve in making its prediction to address the problem of significant interference from abandoned neurons. Firstly, a Neuron Abandoning Back-Propagation (NA-BP) module is proposed to generate Back-Propagated Feature Maps (BPFM) by using the inverse function of the intermediate layers of CNN models, on which the neurons not used for decision-making are abandoned. Meanwhile, the cascading NA-BP modules calculate the tensors of importance coefficients which are linearly combined with the tensors of BPFMs to form the NAFlow. Secondly, to be able to visualize attention flow for similarity metric-based CNN models, a new channel contribution weights module is proposed to calculate the importance coefficients via Jacobian Matrix. The effectiveness of the proposed NAFlow is validated on nine widely-used CNN models for various tasks of general image classification, contrastive learning classification, few-shot image classification, and image retrieval.