 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
PSMamba: Progressive Self-supervised Vision Mamba for Plant Disease Recognition
Dec 16, 2025Self-supervised Learning (SSL) has become a powerful paradigm for representation learning without manual annotations. However, most existing frameworks focus on global alignment and struggle to capture the hierarchical, multi-scale lesion patterns characteristic of plant disease imagery. To address this gap, we propose PSMamba, a progressive self-supervised framework that integrates the efficient sequence modelling of Vision Mamba (VM) with a dual-student hierarchical distillation strategy. Unlike conventional single teacher-student designs, PSMamba employs a shared global teacher and two specialised students: one processes mid-scale views to capture lesion distributions and vein structures, while the other focuses on local views to capture fine-grained cues such as texture irregularities and early-stage lesions. This multi-granular supervision facilitates the joint learning of contextual and detailed representations, with consistency losses ensuring coherent cross-scale alignment. Experiments on three benchmark datasets show that PSMamba consistently outperforms state-of-the-art SSL methods, delivering superior accuracy and robustness in both domain-shifted and fine-grained scenarios.
StateSpace-SSL: Linear-Time Self-supervised Learning for Plant Disease Detection
Dec 11, 2025Self-supervised learning (SSL) is attractive for plant disease detection as it can exploit large collections of unlabeled leaf images, yet most existing SSL methods are built on CNNs or vision transformers that are poorly matched to agricultural imagery. CNN-based SSL struggles to capture disease patterns that evolve continuously along leaf structures, while transformer-based SSL introduces quadratic attention cost from high-resolution patches. To address these limitations, we propose StateSpace-SSL, a linear-time SSL framework that employs a Vision Mamba state-space encoder to model long-range lesion continuity through directional scanning across the leaf surface. A prototype-driven teacher-student objective aligns representations across multiple views, encouraging stable and lesion-aware features from labelled data. Experiments on three publicly available plant disease datasets show that StateSpace-SSL consistently outperforms the CNN- and transformer-based SSL baselines in various evaluation metrics. Qualitative analyses further confirm that it learns compact, lesion-focused feature maps, highlighting the advantage of linear state-space modelling for self-supervised plant disease representation learning.
A Compositional Feature Embedding and Similarity Metric for Ultra-Fine-Grained Visual Categorization
Oct 06, 2021

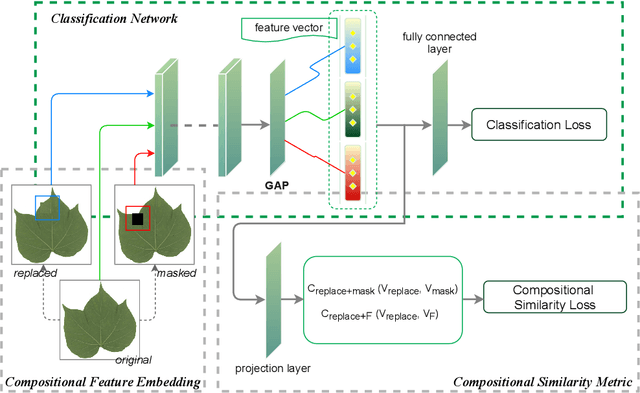
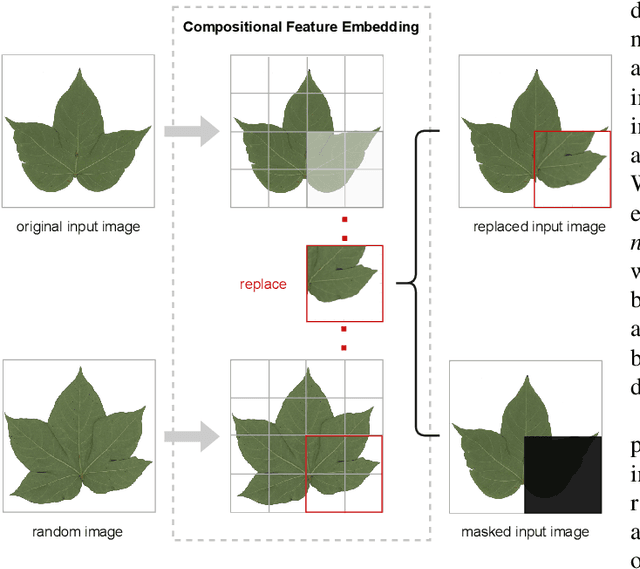
Fine-grained visual categorization (FGVC), which aims at classifying objects with small inter-class variances, has been significantly advanced in recent years. However, ultra-fine-grained visual categorization (ultra-FGVC), which targets at identifying subclasses with extremely similar patterns, has not received much attention. In ultra-FGVC datasets, the samples per category are always scarce as the granularity moves down, which will lead to overfitting problems. Moreover, the difference among different categories is too subtle to distinguish even for professional experts. Motivated by these issues, this paper proposes a novel compositional feature embedding and similarity metric (CECS). Specifically, in the compositional feature embedding module, we randomly select patches in the original input image, and these patches are then replaced by patches from the images of different categories or masked out. Then the replaced and masked images are used to augment the original input images, which can provide more diverse samples and thus largely alleviate overfitting problem resulted from limited training samples. Besides, learning with diverse samples forces the model to learn not only the most discriminative features but also other informative features in remaining regions, enhancing the generalization and robustness of the model. In the compositional similarity metric module, a new similarity metric is developed to improve the classification performance by narrowing the intra-category distance and enlarging the inter-category distance. Experimental results on two ultra-FGVC datasets and one FGVC dataset with recent benchmark methods consistently demonstrate that the proposed CECS method achieves the state of-the-art performance.
Mask-Guided Feature Extraction and Augmentation for Ultra-Fine-Grained Visual Categorization
Sep 16, 2021
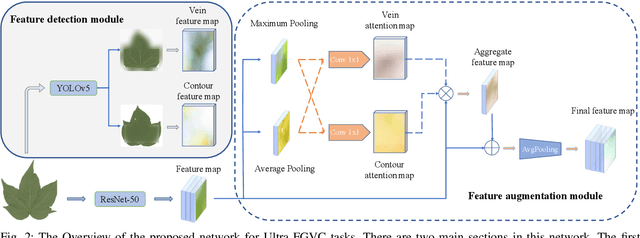
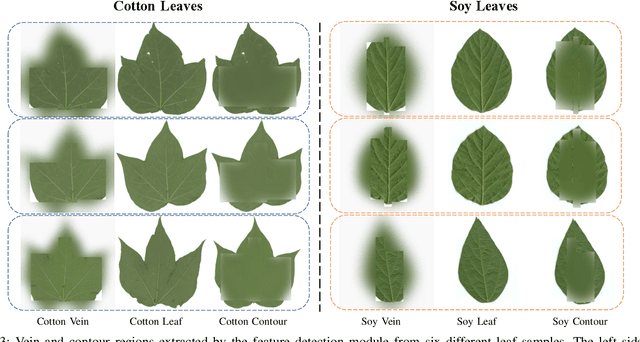
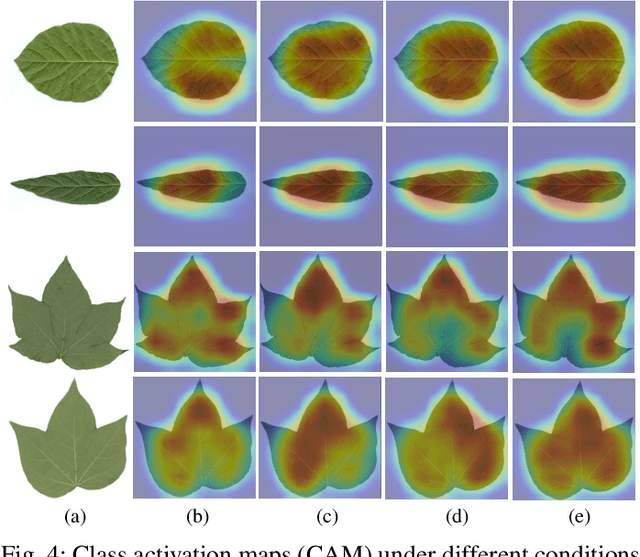
While the fine-grained visual categorization (FGVC) problems have been greatly developed in the past years, the Ultra-fine-grained visual categorization (Ultra-FGVC) problems have been understudied. FGVC aims at classifying objects from the same species (very similar categories), while the Ultra-FGVC targets at more challenging problems of classifying images at an ultra-fine granularity where even human experts may fail to identify the visual difference. The challenges for Ultra-FGVC mainly comes from two aspects: one is that the Ultra-FGVC often arises overfitting problems due to the lack of training samples; and another lies in that the inter-class variance among images is much smaller than normal FGVC tasks, which makes it difficult to learn discriminative features for each class. To solve these challenges, a mask-guided feature extraction and feature augmentation method is proposed in this paper to extract discriminative and informative regions of images which are then used to augment the original feature map. The advantage of the proposed method is that the feature detection and extraction model only requires a small amount of target region samples with bounding boxes for training, then it can automatically locate the target area for a large number of images in the dataset at a high detection accuracy. Experimental results on two public datasets and ten state-of-the-art benchmark methods consistently demonstrate the effectiveness of the proposed method both visually and quantitatively.
A Generalized Kernel Risk Sensitive Loss for Robust Two-Dimensional Singular Value Decomposition
May 10, 2020
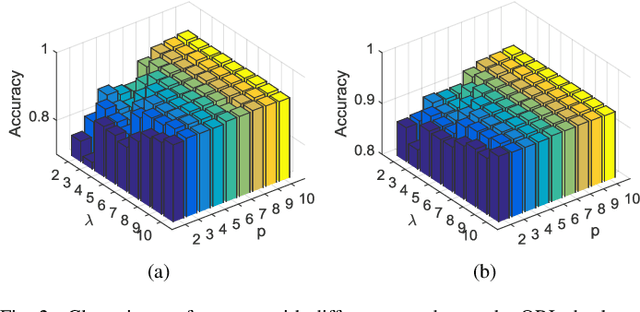


Two-dimensional singular decomposition (2DSVD) has been widely used for image processing tasks, such as image reconstruction, classification, and clustering. However, traditional 2DSVD algorithm is based on the mean square error (MSE) loss, which is sensitive to outliers. To overcome this problem, we propose a robust 2DSVD framework based on a generalized kernel risk sensitive loss (GKRSL-2DSVD) which is more robust to noise and and outliers. Since the proposed objective function is non-convex, a majorization-minimization algorithm is developed to efficiently solve it with guaranteed convergence. The proposed framework has inherent properties of processing non-centered data, rotational invariant, being easily extended to higher order spaces. Experimental results on public databases demonstrate that the performance of the proposed method on different applications significantly outperforms that of all the benchmarks.
A Unified Weight Learning and Low-Rank Regression Model for Robust Face Recognition
May 10, 2020


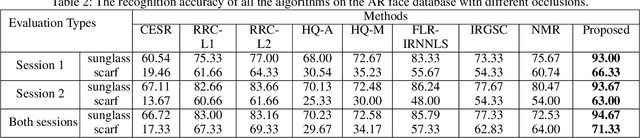
Regression-based error modelling has been extensively studied for face recognition in recent years. The most important problem in regression-based error model is fitting the complex representation error caused by various corruptions and environment changes. However, existing works are not robust enough to model the complex corrupted errors. In this paper, we address this problem by a unified sparse weight learning and low-rank approximation regression model and applied it to the robust face recognition in the presence of varying types and levels of corruptions, such as random pixel corruptions and block occlusions, or disguise. The proposed model enables the random noise and contiguous occlusions to be addressed simultaneously. For the random noise, we proposed a generalized correntropy (GC) function to match the error distribution. For the structured error caused by occlusion or disguise, we proposed a GC function based rank approximation to measure the rank of error matrix. An effective iterative optimization is developed to solve the optimal weight learning and low-rank approximation. Extensive experimental results on three public face databases show that the proposed model can fit the error distribution and structure very well, thus obtain better recognition accuracy in comparison with the existing methods.
Robust Tensor Decomposition for Image Representation Based on Generalized Correntropy
May 10, 2020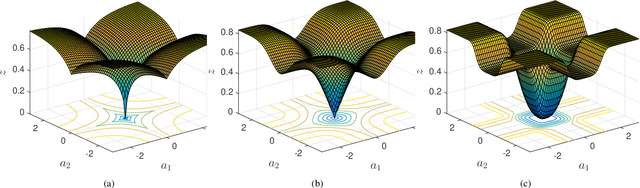


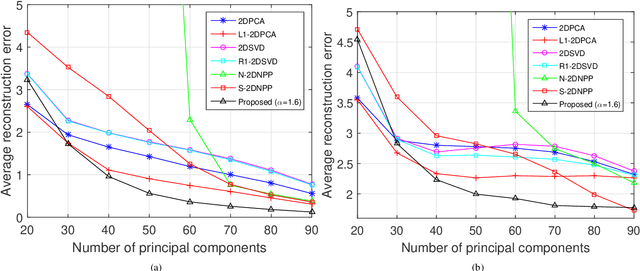
Traditional tensor decomposition methods, e.g., two dimensional principal component analysis and two dimensional singular value decomposition, that minimize mean square errors, are sensitive to outliers. To overcome this problem, in this paper we propose a new robust tensor decomposition method using generalized correntropy criterion (Corr-Tensor). A Lagrange multiplier method is used to effectively optimize the generalized correntropy objective function in an iterative manner. The Corr-Tensor can effectively improve the robustness of tensor decomposition with the existence of outliers without introducing any extra computational cost. Experimental results demonstrated that the proposed method significantly reduces the reconstruction error on face reconstruction and improves the accuracies on handwritten digit recognition and facial image clustering.
A Robust Matching Pursuit Algorithm Using Information Theoretic Learning
May 10, 2020



Current orthogonal matching pursuit (OMP) algorithms calculate the correlation between two vectors using the inner product operation and minimize the mean square error, which are both suboptimal when there are non-Gaussian noises or outliers in the observation data. To overcome these problems, a new OMP algorithm is developed based on the information theoretic learning (ITL), which is built on the following new techniques: (1) an ITL-based correlation (ITL-Correlation) is developed as a new similarity measure which can better exploit higher-order statistics of the data, and is robust against many different types of noise and outliers in a sparse representation framework; (2) a non-second order statistic measurement and minimization method is developed to improve the robustness of OMP by overcoming the limitation of Gaussianity inherent in cost function based on second-order moments. The experimental results on both simulated and real-world data consistently demonstrate the superiority of the proposed OMP algorithm in data recovery, image reconstruction, and classification.