 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIANet: A Novel Domain Adaptation Approach to Maximize Class Distinction with Neural Collapse Principles
Jul 23, 2024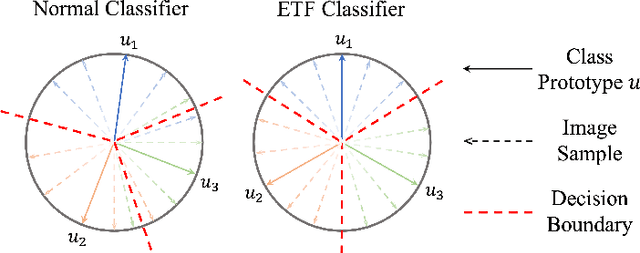
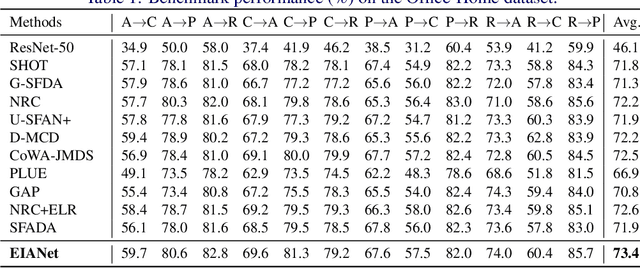
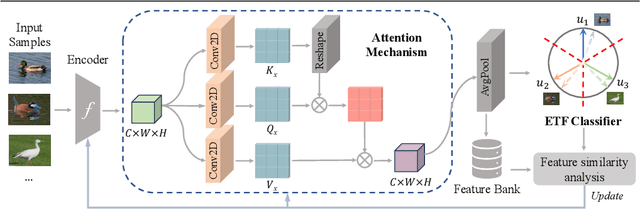
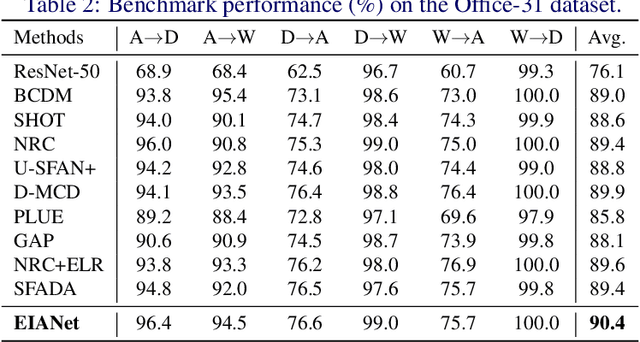
Source-free domain adaptation (SFDA) aims to transfer knowledge from a labelled source domain to an unlabelled target domain. A major challenge in SFDA is deriving accurate categorical information for the target domain, especially when sample embeddings from different classes appear similar. This issue is particularly pronounced in fine-grained visual categorization tasks, where inter-class differences are subtle. To overcome this challenge, we introduce a novel ETF-Informed Attention Network (EIANet) to separate class prototypes by utilizing attention and neural collapse principles. More specifically, EIANet employs a simplex Equiangular Tight Frame (ETF) classifier in conjunction with an attention mechanism, facilitating the model to focus on discriminative features and ensuring maximum class prototype separation. This innovative approach effectively enlarges the feature difference between different classes in the latent space by locating salient regions, thereby preventing the misclassification of similar but distinct category samples and providing more accurate categorical information to guide the fine-tuning process on the target domain. Experimental results across four SFDA datasets validate EIANet's state-of-the-art performance. Code is available at: https://github.com/zichengpan/EIANet.
Mask-Guided Feature Extraction and Augmentation for Ultra-Fine-Grained Visual Categorization
Sep 16, 2021
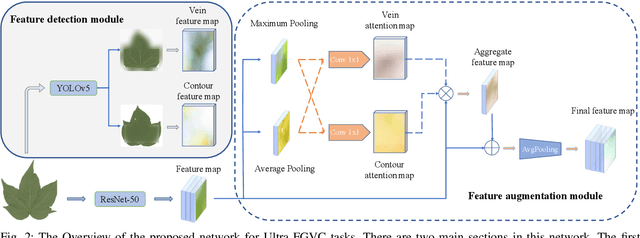
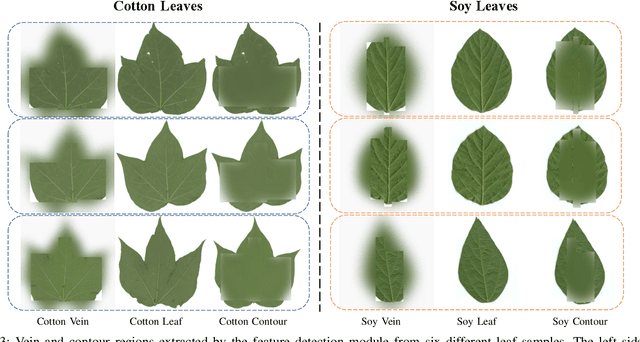
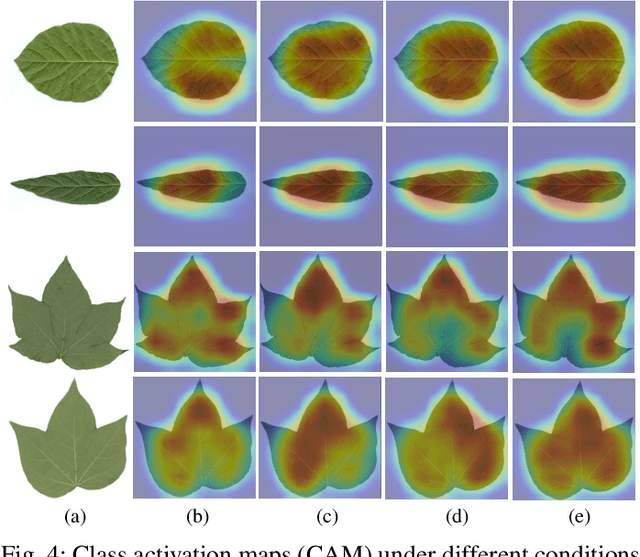
While the fine-grained visual categorization (FGVC) problems have been greatly developed in the past years, the Ultra-fine-grained visual categorization (Ultra-FGVC) problems have been understudied. FGVC aims at classifying objects from the same species (very similar categories), while the Ultra-FGVC targets at more challenging problems of classifying images at an ultra-fine granularity where even human experts may fail to identify the visual difference. The challenges for Ultra-FGVC mainly comes from two aspects: one is that the Ultra-FGVC often arises overfitting problems due to the lack of training samples; and another lies in that the inter-class variance among images is much smaller than normal FGVC tasks, which makes it difficult to learn discriminative features for each class. To solve these challenges, a mask-guided feature extraction and feature augmentation method is proposed in this paper to extract discriminative and informative regions of images which are then used to augment the original feature map. The advantage of the proposed method is that the feature detection and extraction model only requires a small amount of target region samples with bounding boxes for training, then it can automatically locate the target area for a large number of images in the dataset at a high detection accuracy. Experimental results on two public datasets and ten state-of-the-art benchmark methods consistently demonstrate the effectiveness of the proposed method both visually and quantitatively.