 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-FedPGN: Finding Global Flat Minima for Differentially Private Federated Learning via Penalizing Gradient Norm
Oct 31, 2025To prevent inference attacks in Federated Learning (FL) and reduce the leakage of sensitive information, Client-level Differentially Private Federated Learning (CL-DPFL) is widely used. However, current CL-DPFL methods usually result in sharper loss landscapes, which leads to a decrease in model generalization after differential privacy protection. By using Sharpness Aware Minimization (SAM), the current popular federated learning methods are to find a local flat minimum value to alleviate this problem. However, the local flatness may not reflect the global flatness in CL-DPFL. Therefore, to address this issue and seek global flat minima of models, we propose a new CL-DPFL algorithm, DP-FedPGN, in which we introduce a global gradient norm penalty to the local loss to find the global flat minimum. Moreover, by using our global gradient norm penalty, we not only find a flatter global minimum but also reduce the locally updated norm, which means that we further reduce the error of gradient clipping. From a theoretical perspective, we analyze how DP-FedPGN mitigates the performance degradation caused by DP. Meanwhile, the proposed DP-FedPGN algorithm eliminates the impact of data heterogeneity and achieves fast convergence. We also use R\'enyi DP to provide strict privacy guarantees and provide sensitivity analysis for local updates. Finally, we conduct effectiveness tests on both ResNet and Transformer models, and achieve significant improvements in six visual and natural language processing tasks compared to existing state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/DP-FedPGN
FedMuon: Accelerating Federated Learning with Matrix Orthogonalization
Oct 31, 2025The core bottleneck of Federated Learning (FL) lies in the communication rounds. That is, how to achieve more effective local updates is crucial for reducing communication rounds. Existing FL methods still primarily use element-wise local optimizers (Adam/SGD), neglecting the geometric structure of the weight matrices. This often leads to the amplification of pathological directions in the weights during local updates, leading deterioration in the condition number and slow convergence. Therefore, we introduce the Muon optimizer in local, which has matrix orthogonalization to optimize matrix-structured parameters. Experimental results show that, in IID setting, Local Muon significantly accelerates the convergence of FL and reduces communication rounds compared to Local SGD and Local AdamW. However, in non-IID setting, independent matrix orthogonalization based on the local distributions of each client induces strong client drift. Applying Muon in non-IID FL poses significant challenges: (1) client preconditioner leading to client drift; (2) moment reinitialization. To address these challenges, we propose a novel Federated Muon optimizer (FedMuon), which incorporates two key techniques: (1) momentum aggregation, where clients use the aggregated momentum for local initialization; (2) local-global alignment, where the local gradients are aligned with the global update direction to significantly reduce client drift. Theoretically, we prove that \texttt{FedMuon} achieves a linear speedup convergence rate without the heterogeneity assumption, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. Empirically, we validate the effectiveness of FedMuon on language and vision models. Compared to several baselines, FedMuon significantly reduces communication rounds and improves test accuracy.
FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models
Oct 31, 2025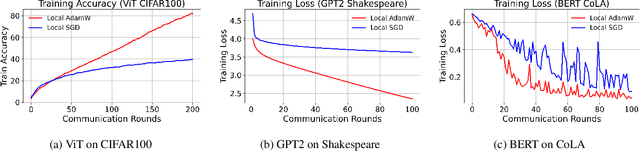
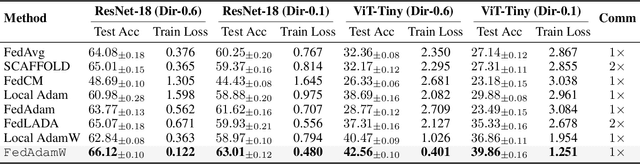
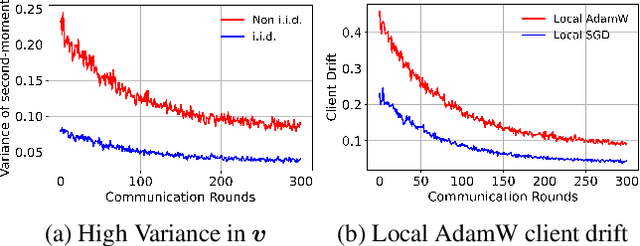
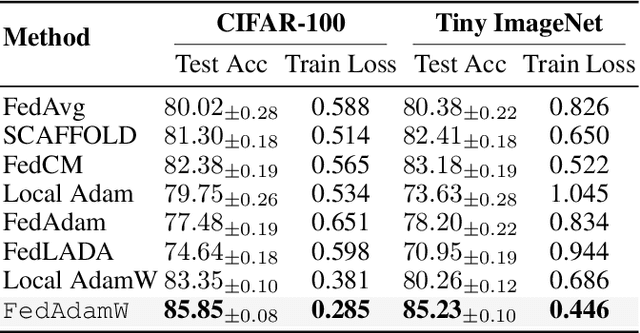
AdamW has become one of the most effective optimizers for training large-scale models. We have also observed its effectiveness in the context of federated learning (FL). However, directly applying AdamW in federated learning settings poses significant challenges: (1) due to data heterogeneity, AdamW often yields high variance in the second-moment estimate $\boldsymbol{v}$; (2) the local overfitting of AdamW may cause client drift; and (3) Reinitializing moment estimates ($\boldsymbol{v}$, $\boldsymbol{m}$) at each round slows down convergence. To address these challenges, we propose the first \underline{Fed}erated \underline{AdamW} algorithm, called \texttt{FedAdamW}, for training and fine-tuning various large models. \texttt{FedAdamW} aligns local updates with the global update using both a \textbf{local correction mechanism} and decoupled weight decay to mitigate local overfitting. \texttt{FedAdamW} efficiently aggregates the \texttt{mean} of the second-moment estimates to reduce their variance and reinitialize them. Theoretically, we prove that \texttt{FedAdamW} achieves a linear speedup convergence rate of $\mathcal{O}(\sqrt{(L \Delta \sigma_l^2)/(S K R \epsilon^2)}+(L \Delta)/R)$ without \textbf{heterogeneity assumption}, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. We also employ PAC-Bayesian generalization analysis to explain the effectiveness of decoupled weight decay in local training. Empirically, we validate the effectiveness of \texttt{FedAdamW} on language and vision Transformer models. Compared to several baselines, \texttt{FedAdamW} significantly reduces communication rounds and improves test accuracy. The code is available in https://github.com/junkangLiu0/FedAdamW.
SSL-SSAW: Self-Supervised Learning with Sigmoid Self-Attention Weighting for Question-Based Sign Language Translation
Sep 17, 2025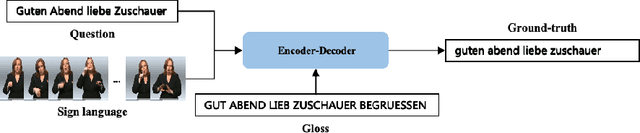
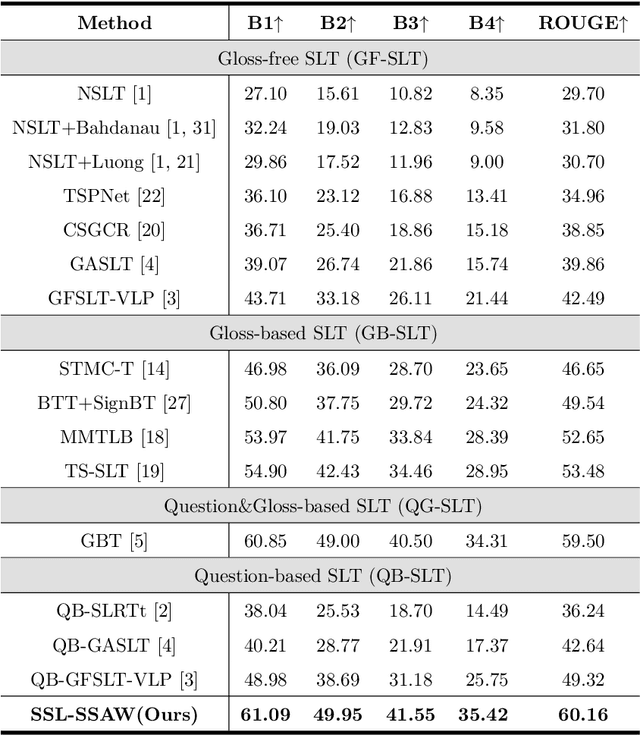
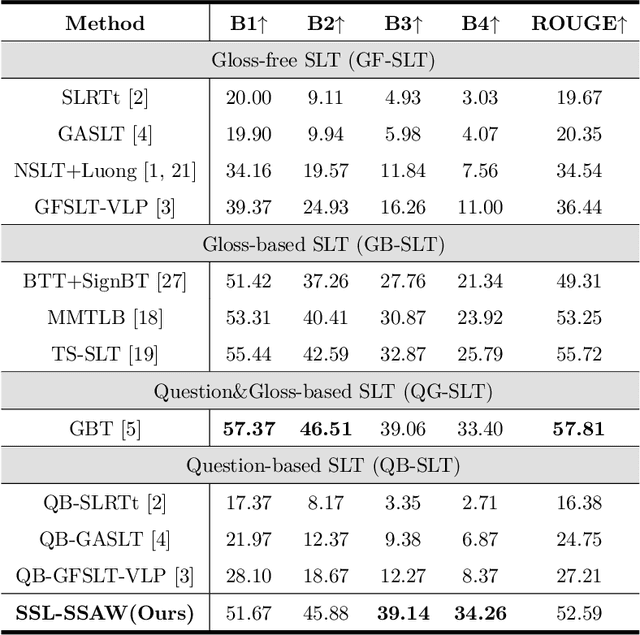
Sign Language Translation (SLT) bridges the communication gap between deaf people and hearing people, where dialogue provides crucial contextual cues to aid in translation. Building on this foundational concept, this paper proposes Question-based Sign Language Translation (QB-SLT), a novel task that explores the efficient integration of dialogue. Unlike gloss (sign language transcription) annotations, dialogue naturally occurs in communication and is easier to annotate. The key challenge lies in aligning multimodality features while leveraging the context of the question to improve translation. To address this issue, we propose a cross-modality Self-supervised Learning with Sigmoid Self-attention Weighting (SSL-SSAW) fusion method for sign language translation. Specifically, we employ contrastive learning to align multimodality features in QB-SLT, then introduce a Sigmoid Self-attention Weighting (SSAW) module for adaptive feature extraction from question and sign language sequences. Additionally, we leverage available question text through self-supervised learning to enhance representation and translation capabilities. We evaluated our approach on newly constructed CSL-Daily-QA and PHOENIX-2014T-QA datasets, where SSL-SSAW achieved SOTA performance. Notably, easily accessible question assistance can achieve or even surpass the performance of gloss assistance. Furthermore, visualization results demonstrate the effectiveness of incorporating dialogue in improving translation quality.
Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation
Mar 28, 2025



In this work, we focus on continual semantic segmentation (CSS), where segmentation networks are required to continuously learn new classes without erasing knowledge of previously learned ones. Although storing images of old classes and directly incorporating them into the training of new models has proven effective in mitigating catastrophic forgetting in classification tasks, this strategy presents notable limitations in CSS. Specifically, the stored and new images with partial category annotations leads to confusion between unannotated categories and the background, complicating model fitting. To tackle this issue, this paper proposes a novel Enhanced Instance Replay (EIR) method, which not only preserves knowledge of old classes while simultaneously eliminating background confusion by instance storage of old classes, but also mitigates background shifts in the new images by integrating stored instances with new images. By effectively resolving background shifts in both stored and new images, EIR alleviates catastrophic forgetting in the CSS task, thereby enhancing the model's capacity for CSS. Experimental results validate the efficacy of our approach, which significantly outperforms state-of-the-art CSS methods.
iLLaVA: An Image is Worth Fewer Than 1/3 Input Tokens in Large Multimodal Models
Dec 09, 2024



In this paper, we introduce iLLaVA, a simple method that can be seamlessly deployed upon current Large Vision-Language Models (LVLMs) to greatly increase the throughput with nearly lossless model performance, without a further requirement to train. iLLaVA achieves this by finding and gradually merging the redundant tokens with an accurate and fast algorithm, which can merge hundreds of tokens within only one step. While some previous methods have explored directly pruning or merging tokens in the inference stage to accelerate models, our method excels in both performance and throughput by two key designs. First, while most previous methods only try to save the computations of Large Language Models (LLMs), our method accelerates the forward pass of both image encoders and LLMs in LVLMs, which both occupy a significant part of time during inference. Second, our method recycles the beneficial information from the pruned tokens into existing tokens, which avoids directly dropping context tokens like previous methods to cause performance loss. iLLaVA can nearly 2$\times$ the throughput, and reduce the memory costs by half with only a 0.2\% - 0.5\% performance drop across models of different scales including 7B, 13B and 34B. On tasks across different domains including single-image, multi-images and videos, iLLaVA demonstrates strong generalizability with consistently promising efficiency. We finally offer abundant visualizations to show the merging processes of iLLaVA in each step, which show insights into the distribution of computing resources in LVLMs. Code is available at https://github.com/hulianyuyy/iLLaVA.
Deep Correlated Prompting for Visual Recognition with Missing Modalities
Oct 10, 2024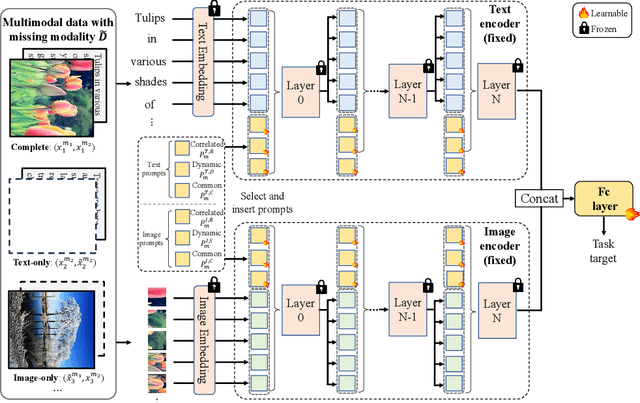
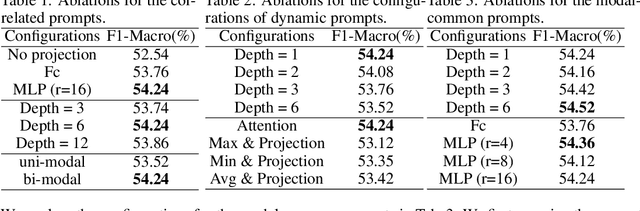
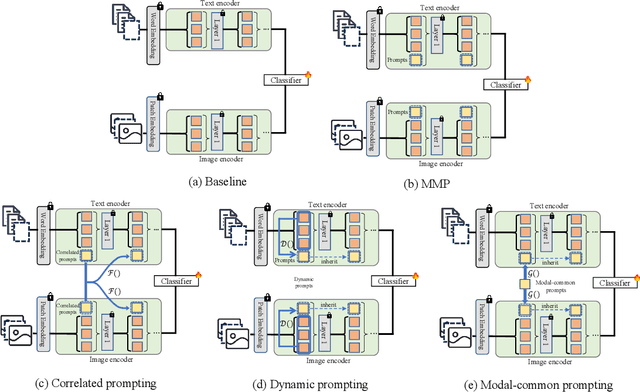
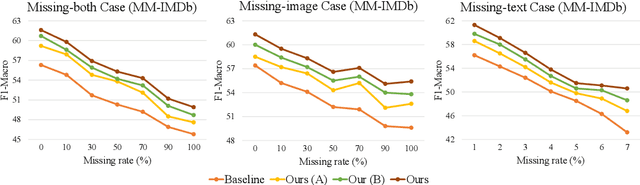
Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
Pose-Guided Fine-Grained Sign Language Video Generation
Sep 25, 2024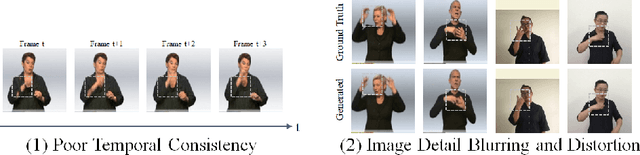

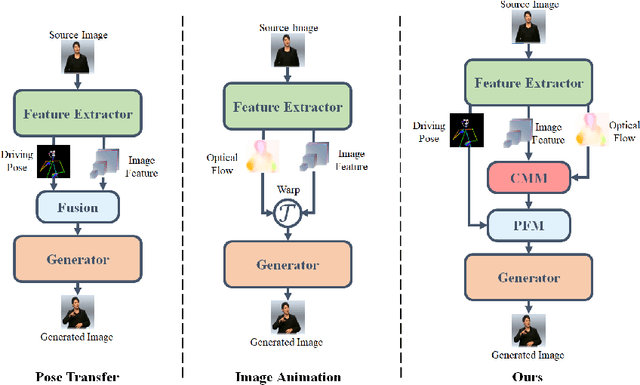
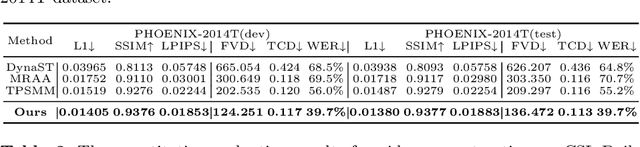
Sign language videos are an important medium for spreading and learning sign language. However, most existing human image synthesis methods produce sign language images with details that are distorted, blurred, or structurally incorrect. They also produce sign language video frames with poor temporal consistency, with anomalies such as flickering and abrupt detail changes between the previous and next frames. To address these limitations, we propose a novel Pose-Guided Motion Model (PGMM) for generating fine-grained and motion-consistent sign language videos. Firstly, we propose a new Coarse Motion Module (CMM), which completes the deformation of features by optical flow warping, thus transfering the motion of coarse-grained structures without changing the appearance; Secondly, we propose a new Pose Fusion Module (PFM), which guides the modal fusion of RGB and pose features, thus completing the fine-grained generation. Finally, we design a new metric, Temporal Consistency Difference (TCD) to quantitatively assess the degree of temporal consistency of a video by comparing the difference between the frames of the reconstructed video and the previous and next frames of the target video. Extensive qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in most benchmark tests, with visible improvements in details and temporal consistency.
Compensate Quantization Errors+: Quantized Models Are Inquisitive Learners
Jul 22, 2024



Large Language Models (LLMs) showcase remarkable performance and robust deductive capabilities, yet their expansive size complicates deployment and raises environmental concerns due to substantial resource consumption. The recent development of a quantization technique known as Learnable Singular-value Increment (LSI) has addressed some of these quantization challenges. Leveraging insights from LSI and our extensive research, we have developed innovative methods that enhance the performance of quantized LLMs, particularly in low-bit settings. Our methods consistently deliver state-of-the-art results across various quantization scenarios and offer deep theoretical insights into the quantization process, elucidating the potential of quantized models for widespread application.
Towards stable training of parallel continual learning
Jul 11, 2024



Parallel Continual Learning (PCL) tasks investigate the training methods for continual learning with multi-source input, where data from different tasks are learned as they arrive. PCL offers high training efficiency and is well-suited for complex multi-source data systems, such as autonomous vehicles equipped with multiple sensors. However, at any time, multiple tasks need to be trained simultaneously, leading to severe training instability in PCL. This instability manifests during both forward and backward propagation, where features are entangled and gradients are conflict. This paper introduces Stable Parallel Continual Learning (SPCL), a novel approach that enhances the training stability of PCL for both forward and backward propagation. For the forward propagation, we apply Doubly-block Toeplit (DBT) Matrix based orthogonality constraints to network parameters to ensure stable and consistent propagation. For the backward propagation, we employ orthogonal decomposition for gradient management stabilizes backpropagation and mitigates gradient conflicts across tasks. By optimizing gradients by ensuring orthogonality and minimizing the condition number, SPCL effectively stabilizing the gradient descent in complex optimization tasks. Experimental results demonstrate that SPCL outperforms state-of-the-art methjods and achieve better training stability.